Mamba bagus, tapi perkembangannya masih awal. Terdapat banyak seni bina pembelajaran mendalam, tetapi yang paling berjaya dalam beberapa tahun kebelakangan ini adalah tiada satupun Transformer telah menubuhkan kedudukan dominannya dalam pelbagai bidang aplikasi.
Salah satu pemacu utama kejayaan tersebut ialah mekanisme perhatian, yang membolehkan model berasaskan Transformer menumpukan pada bahagian yang berkaitan dengan jujukan input dan mencapai hasil yang lebih baik. Walau bagaimanapun, kelemahan mekanisme perhatian ialah overhed pengiraan adalah tinggi, yang meningkat secara kuadratik dengan saiz input, menjadikannya sukar untuk memproses teks yang sangat panjang.
Nasib baik, seni bina baharu yang berpotensi besar telah lahir suatu masa dahulu: model jujukan ruang keadaan berstruktur (SSM). Seni bina ini boleh menangkap kebergantungan kompleks dalam data jujukan dengan cekap, menjadikannya lawan kuat Transformer.
Reka bentuk model jenis ini diilhamkan oleh model angkasa keadaan klasik - kita boleh menganggapnya sebagai gabungan rangkaian saraf berulang dan konvolusi. rangkaian neural Model gabungan. Mereka boleh dikira dengan cekap menggunakan operasi gelung atau lilitan, membenarkan overhed pengiraan untuk skala secara linear atau hampir linear dengan panjang jujukan, sekali gus mengurangkan kos pengiraan dengan ketara.
Secara lebih khusus, keupayaan pemodelan Mamba, salah satu varian paling berjaya SSM, sudah boleh menyamai Transformer, sambil mengekalkan urutan kebolehskalaan linear.
Mamba mula-mula memperkenalkan mekanisme pemilihan yang mudah tetapi berkesan, yang boleh membuat parameter semula SSM mengikut input, supaya model dapat menapis ketidakkonsistenan . maklumat yang relevan sambil mengekalkan data yang diperlukan dan relevan selama-lamanya. Mamba kemudiannya menyertakan algoritma peka perkakasan yang mengira model secara berulang menggunakan imbasan dan bukannya konvolusi, yang menghasilkan kelajuan 3x ganda pada GPU A100.
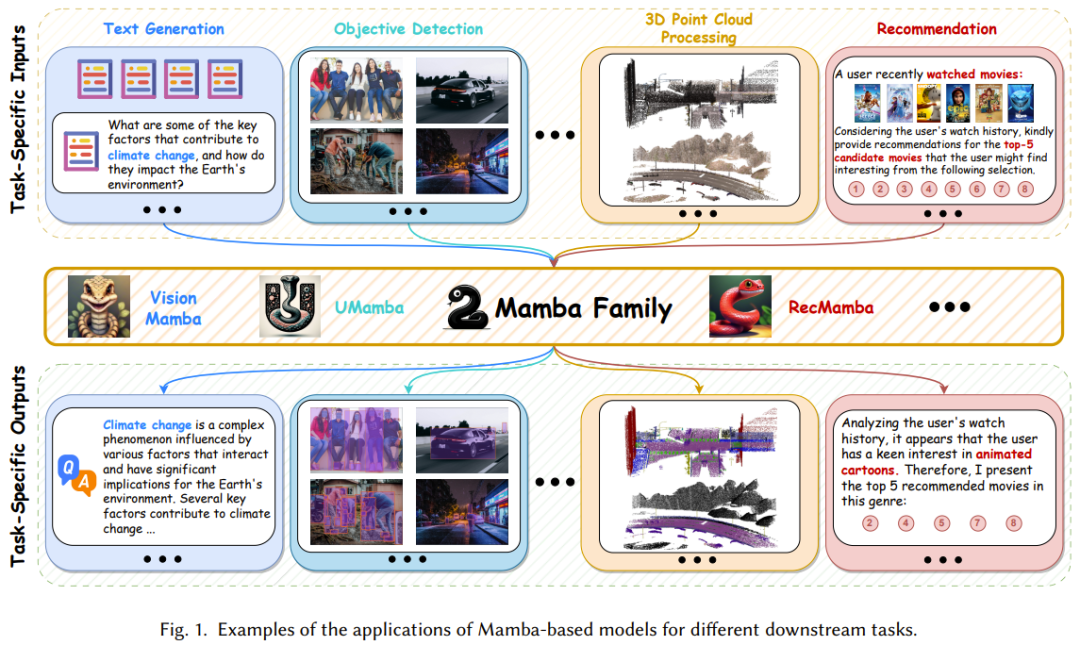
Seperti yang ditunjukkan dalam Rajah 1, dengan keupayaan berkuasanya untuk memodelkan data jujukan panjang yang kompleks dan skalabiliti hampir linear, Mamba telah muncul sebagai Ia adalah model asas dan dijangka merevolusikan banyak bidang penyelidikan dan aplikasi seperti penglihatan komputer, pemprosesan bahasa semula jadi dan rawatan perubatan.
Oleh itu, kesusasteraan tentang penyelidikan dan aplikasi Mamba berkembang pesat dan membingungkan laporan semakan yang komprehensif akan memberi manfaat yang besar. Baru-baru ini, pasukan penyelidik dari Universiti Politeknik Hong Kong menerbitkan sumbangan mereka di arXiv.
 Tajuk kertas: Tinjauan Mamba
Tajuk kertas: Tinjauan Mamba
#🎜🎜 #Alamat kertas: https://arxiv.org/pdf/2408.01129
Laporan semakan sudut ini diambil daripada berbilang meringkaskan Mamba, yang bukan sahaja dapat membantu pemula mempelajari mekanisme kerja asas Mamba, tetapi juga membantu pengamal berpengalaman memahami perkembangan terkini.
Mamba ialah hala tuju penyelidikan yang popular, dan oleh itu banyak pasukan cuba menulis laporan ulasan Sebagai tambahan kepada yang diperkenalkan dalam artikel ini, terdapat juga Ulasan lain memfokuskan pada model angkasa negeri atau Mamba visual Untuk butiran, sila rujuk kertas yang berkaitan:
Mamba-360: Tinjauan model angkasa negeri sebagai alternatif pengubah. untuk pemodelan jujukan panjang : Kaedah, aplikasi dan cabaran arXiv:2404.16112Nyatakan model angkasa untuk alternatif rangkaian generasi baharu kepada transformer: Satu tinjauan. 🎜🎜## Tinjauan tentang visi mamba: Model, aplikasi dan cabaran arXiv:2405.04404 . 🎜 🎜#
Mamba konzentriert sich auf das zyklische Gerüst des Recurrent Neural Network (RNN), den parallelen Rechen- und Aufmerksamkeitsmechanismus des Transformers und die linearen Eigenschaften des State Space Model (SSM). Um Mamba vollständig zu verstehen, ist es daher notwendig, zunächst diese drei Architekturen zu verstehen. Rekurrentes neuronales Netzwerk Rekurrentes neuronales Netzwerk (RNN) hat die Fähigkeit, den internen Speicher beizubehalten, sodass es Sequenzdaten sehr gut verarbeiten kann. Insbesondere verarbeitet das Standard-RNN bei jedem diskreten Zeitschritt k einen Vektor zusammen mit dem verborgenen Zustand des vorherigen Zeitschritts, gibt dann einen anderen Vektor aus und aktualisiert den verborgenen Zustand. Dieser verborgene Zustand kann als Speicher des RNN verwendet werden, der Informationen über in der Vergangenheit gesehene Eingaben speichern kann. Dieser dynamische Speicher ermöglicht es RNNs, Sequenzen unterschiedlicher Länge zu verarbeiten. Das heißt, RNN ist ein nichtlineares wiederkehrendes Modell, das zeitliche Muster effektiv erfassen kann, indem es historisches Wissen nutzt, das in verborgenen Zuständen gespeichert ist. Der Selbstaufmerksamkeitsmechanismus von Transformer hilft dabei, globale Abhängigkeiten zwischen Eingaben zu erfassen. Dies erfolgt durch die Zuweisung von Gewichtungen zu jeder Position basierend auf ihrer Bedeutung im Verhältnis zu anderen Positionen. Genauer gesagt wird die ursprüngliche Eingabe zunächst linear transformiert, um die Folge der Eingabevektoren x in drei Arten von Vektoren umzuwandeln: Abfragen Q, Schlüssel K und Werte V. Berechnen Sie dann den normalisierten Aufmerksamkeitswert S und berechnen Sie das Aufmerksamkeitsgewicht. Zusätzlich zur Ausführung einer Einzelaufmerksamkeitsfunktion können wir auch Mehrkopfaufmerksamkeit ausführen. Dadurch kann das Modell verschiedene Arten von Beziehungen erfassen und Eingabesequenzen aus mehreren Perspektiven verstehen. Multi-Head-Aufmerksamkeit verwendet mehrere Sätze von Selbstaufmerksamkeitsmodulen, um Eingabesequenzen parallel zu verarbeiten. Jeder dieser Köpfe arbeitet unabhängig und führt die gleichen Berechnungen durch wie Standardmechanismen der Selbstaufmerksamkeit. Danach werden die Aufmerksamkeitsgewichte jedes Kopfes aggregiert und kombiniert, um die gewichtete Summe der Wertvektoren zu erhalten. Dieser Aggregationsschritt ermöglicht es dem Modell, Informationen aus mehreren Köpfen zu nutzen und viele verschiedene Muster und Beziehungen in der Eingabesequenz zu erfassen. Das Zustandsraummodell (SSM) ist ein traditionelles mathematisches Framework, das zur Beschreibung des dynamischen Verhaltens eines Systems über die Zeit verwendet werden kann. In den letzten Jahren wurde SSM in so unterschiedlichen Bereichen wie Kybernetik, Robotik und Wirtschaft häufig eingesetzt. Im Kern spiegelt SSM das Verhalten des Systems durch eine Reihe versteckter Variablen namens „Zustand“ wider und ermöglicht so die effektive Erfassung der Abhängigkeiten von Zeitdaten. Im Gegensatz zu RNN ist SSM ein lineares Modell mit assoziativen Eigenschaften. Insbesondere erstellt das klassische Zustandsraummodell zwei Schlüsselgleichungen (Zustandsgleichung und Beobachtungsgleichung), um die Beziehung zwischen Eingabe x und Ausgabe y zum aktuellen Zeitpunkt t durch einen N-dimensionalen verborgenen Zustand h (t) zu modellieren.
Um den Anforderungen des maschinellen Lernens gerecht zu werden, muss SSM einen Diskretisierungsprozess durchlaufen – die Umwandlung kontinuierlicher Parameter in diskrete Parameter. Im Allgemeinen besteht das Ziel von Diskretisierungsverfahren darin, kontinuierliche Zeit in K diskrete Intervalle mit möglichst gleicher Integralfläche zu unterteilen. Um dieses Ziel zu erreichen, ist eine der repräsentativsten Lösungen von SSM Zero-Order Hold (ZOH), die davon ausgeht, dass der Funktionswert im Intervall Δ = [?_{?−1}, ?_? ] konstant bleibt. Diskretes SSM hat eine ähnliche Struktur wie ein wiederkehrendes neuronales Netzwerk, sodass es den Inferenzprozess effizienter durchführen kann als transformatorbasierte Modelle.
Diskretes SSM ist ein lineares System mit assoziativen Eigenschaften, sodass es nahtlos in Faltungsberechnungen integriert werden kann. Die Beziehung zwischen RNN, Transformer und SSMAbbildung 2 zeigt den Berechnungsalgorithmus von RNN, Transformer und SSM.
Di satu pihak, RNN konvensional beroperasi berdasarkan rangka kerja berulang bukan linear, di mana setiap pengiraan hanya bergantung pada keadaan tersembunyi sebelumnya dan input semasa. Walaupun borang ini membolehkan RNN menjana output dengan cepat semasa inferens autoregresif, ia juga menyukarkan RNN untuk menggunakan sepenuhnya kuasa pengkomputeran selari GPU, menghasilkan latihan model yang lebih perlahan. Sebaliknya, seni bina Transformer melakukan pendaraban matriks secara selari pada berbilang pasangan "kunci pertanyaan", dan pendaraban matriks boleh diperuntukkan dengan cekap kepada sumber perkakasan, membolehkan latihan model berasaskan perhatian yang lebih pantas. Walau bagaimanapun, jika anda mahu model berasaskan Transformer menjana respons atau ramalan, proses inferens boleh memakan masa yang lama. Tidak seperti RNN dan Transformer, yang hanya menyokong satu jenis pengiraan, SSM diskret adalah sangat fleksibel; terima kasih kepada sifat linearnya, ia boleh menyokong pengiraan gelung dan pengiraan konvolusi. Ciri ini membolehkan SSM bukan sahaja mencapai inferens yang cekap tetapi juga untuk mencapai latihan selari. Walau bagaimanapun, perlu diingatkan bahawa SSM yang paling konvensional adalah invarian masa, iaitu, A, B, C, dan Δnya adalah bebas daripada input model x. Ini akan mengehadkan keupayaan pemodelannya yang sedar konteks, menyebabkan SSM berprestasi buruk pada beberapa tugas tertentu seperti penyalinan terpilih. Mamba-1: Model ruang keadaan terpilih menggunakan algoritma peka perkakasanMamba-1 memperkenalkan tiga teknologi inovatif berdasarkan model ruang keadaan berstruktur, iaitu berdasarkan polinomulasi kalkomelan unjuran tinggi pemulaan, mekanisme pemilihan dan pengiraan sedar perkakasan HiPPO. Seperti yang ditunjukkan dalam Rajah 3. Matlamat teknik ini adalah untuk meningkatkan keupayaan pemodelan siri masa linear jarak jauh SSM.
Insbesondere kann die Initialisierungsstrategie eine kohärente Matrix für verborgene Zustände erstellen, um das Langstreckengedächtnis effektiv zu fördern. Dann gibt der Auswahlmechanismus SSM die Möglichkeit, Darstellungen wahrnehmbarer Inhalte zu erhalten. Um die Trainingseffizienz zu verbessern, enthält Mamba schließlich auch zwei hardwarebewusste Computeralgorithmen: Parallel Associative Scan und Memory Recomputation. Mamba-2: State Space Dual Transformer hat die Entwicklung vieler verschiedener Technologien inspiriert, wie etwa Parameter-effiziente Feinabstimmung, Minderung des katastrophalen Vergessens und Modellquantisierung. Damit Zustandsraummodelle auch von diesen ursprünglich für Transformer entwickelten Techniken profitieren können, führt Mamba-2 ein neues Framework ein: Structured State Space Duality (SSD). Dieser Rahmen verbindet theoretisch SSM und verschiedene Formen der Aufmerksamkeit. Im Wesentlichen zeigt SSD, dass sowohl der von Transformer verwendete Aufmerksamkeitsmechanismus als auch das in SSM verwendete lineare zeitinvariante System als semi-separierbare Matrixtransformationen angesehen werden können. Darüber hinaus haben Albert Gu und Tri Dao auch bewiesen, dass selektives SSM einem strukturierten linearen Aufmerksamkeitsmechanismus entspricht, der mithilfe einer halbseparierbaren Maskenmatrix implementiert wird. Mamba-2 entwirft eine auf SSD basierende Rechenmethode, die Hardware effizienter nutzen kann und einen Blockzerlegungsmatrix-Multiplikationsalgorithmus verwendet. Insbesondere ist Mamba-2 durch die Behandlung des Zustandsraummodells durch diese Matrixtransformation in der Lage, diese Berechnung in Matrixblöcke zu zerlegen, wobei die diagonalen Blöcke die Intra-Block-Berechnungen darstellen. Während Off-Diagonal-Blöcke eine Inter-Block-Berechnung durch versteckte Zustandszerlegung von SSM darstellen. Mit dieser Methode kann Mamba-2 zwei- bis achtmal schneller trainieren als der parallele Korrelationsscan von Mamba-1 und dennoch eine mit Transformer vergleichbare Leistung erzielen. Werfen wir einen Blick auf die Blockdesigns von Mamba-1 und Mamba-2. Abbildung 4 vergleicht die beiden Architekturen.
Mamba-1 basiert auf SSM, wobei die selektive SSM-Schicht die Aufgabe hat, die Zuordnung von der Eingabesequenz X zu Y durchzuführen. In diesem Entwurf wird nach der anfänglichen Erstellung einer linearen Projektion von X eine lineare Projektion von (A, B, C) verwendet. Anschließend werden das Eingabe-Token und die Zustandsmatrix mithilfe der Parallelkorrelation durch die selektive SSM-Einheit gescannt, um die Ausgabe Y zu erhalten. Anschließend übernimmt Mamba-1 eine Skip-Verbindung, um die Wiederverwendung von Funktionen zu fördern und Leistungseinbußen abzumildern, die häufig während des Modelltrainings auftreten. Schließlich wird das Mamba-Modell erstellt, indem dieses Modul abwechselnd mit Standardnormalisierung und Restverbindungen gestapelt wird. Was Mamba-2 betrifft, wird die SSD-Schicht eingeführt, um eine Zuordnung von [X, A, B, C] zu Y zu erstellen. Dies wird erreicht, indem eine einzelne Projektion am Anfang des Blocks verwendet wird, um [X, A, B, C] gleichzeitig zu verarbeiten, ähnlich wie Standard-Aufmerksamkeitsarchitekturen Q-, K- und V-Projektionen parallel generieren. Das heißt, der Mamba-2-Block wird basierend auf dem Mamba-1-Block vereinfacht, indem die lineare Sequenzprojektion entfernt wird. Dadurch kann die SSD-Fabric schneller berechnet werden als der parallele selektive Scan von Mamba-1. Um die Trainingsstabilität zu verbessern, fügt Mamba-2 außerdem eine Normalisierungsschicht nach der Sprungverbindung hinzu. Mamba-Modell entwickelt sich und schreitet voranStaatsraummodell und Mamba haben sich in letzter Zeit rasant weiterentwickelt und sind zu einer grundlegenden Wahl für das Backbone-Netzwerk mit großem Potenzial geworden. Obwohl Mamba bei der Verarbeitung natürlicher Sprache eine gute Leistung erbringt, weist es dennoch einige Probleme auf, z. B. Gedächtnisverlust, Schwierigkeiten bei der Verallgemeinerung auf verschiedene Aufgaben, und seine Leistung bei komplexen Mustern ist nicht so gut wie bei Transformer-basierten Sprachmodellen. Um diese Probleme zu lösen, hat die Forschungsgemeinschaft viele Verbesserungen der Mamba-Architektur vorgeschlagen. Die bestehende Forschung konzentriert sich hauptsächlich auf das Design von Modifikationsblöcken, Scanmuster und Speicherverwaltung. Tabelle 1 fasst relevante Studien nach Kategorien zusammen.
Das Design und die Struktur des Mamba-Blocks haben einen großen Einfluss auf die Gesamtleistung des Mamba-Modells und sind daher zu einem wichtigen Forschungsschwerpunkt geworden.
Wie in Abbildung 5 gezeigt, kann die bestehende Forschung basierend auf verschiedenen Methoden zum Aufbau neuer Mamba-Module in drei Kategorien unterteilt werden:
-
Integrationsmethode: Integrieren Sie Mamba-Blöcke mit anderen Modellen, um ein Gleichgewicht zwischen Wirkung und Effizienz zu erzielen
- Ersetzungsmethode: Ersetzen Sie die Hauptebenen in anderen Modell-Frameworks durch Mamba-Blöcke.
- Modifikationsmethode: Ändern Sie die Komponenten innerhalb des klassischen Mamba-Blocks.
Parallelkorrelationsscan ist eine Schlüsselkomponente innerhalb des Mamba-Modells. Sein Ziel ist es, die durch den Auswahlmechanismus verursachten Rechenprobleme zu lösen, die Geschwindigkeit des Trainingsprozesses zu verbessern, und den Speicherbedarf reduzieren. Dies wird erreicht, indem die lineare Natur zeitlich variierender SSMs ausgenutzt wird, um Kernfusion und Neuberechnung auf Hardwareebene zu entwerfen. Das einseitige Sequenzmodellierungsparadigma von Mamba eignet sich jedoch nicht für das umfassende Lernen verschiedener Daten wie Bilder und Videos.
Um dieses Problem zu lindern, haben einige Forscher neue effiziente Scanmethoden erforscht, um die Leistung des Mamba-Modells zu verbessern und seinen Trainingsprozess zu erleichtern. Wie in Abbildung 6 dargestellt, lassen sich die vorhandenen Forschungsergebnisse im Hinblick auf die Entwicklung von Scan-Modi in zwei Kategorien einteilen:
- Flache Scan-Methode: Betrachten Sie die Token-Sequenz aus einer abgeflachten Perspektive und verarbeiten Sie das Modell darauf basierend Eingabe;
- Stereoskopische Scanmethode: Scannen von Modelleingaben über Dimensionen, Kanäle oder Maßstäbe hinweg, die weiter in drei Kategorien unterteilt werden können: geschichtetes Scannen, räumlich-zeitliches Scannen und Hybrid-Scannen.
Ähnlich wie bei RNN speichert der Speicher verborgener Zustände im Zustandsraummodell effektiv die Informationen vorheriger Schritte und ist daher für die Gesamtleistung von SSM Influence von entscheidender Bedeutung . Obwohl Mamba HiPPO-basierte Methoden zur Speicherinitialisierung einführt, ist die Speicherverwaltung in SSM-Einheiten immer noch schwierig, einschließlich der Übertragung versteckter Informationen vor Schichten und der Erzielung einer verlustfreien Speicherkomprimierung. Zu diesem Zweck haben einige bahnbrechende Forschungen eine Reihe verschiedener Lösungen vorgeschlagen, darunter Speicherinitialisierung, Komprimierung und Verkettung. Lassen Sie Mamba sich an verschiedene Daten anpassenDie Mamba-Architektur ist eine Erweiterung des selektiven Zustandsraummodells. Sie verfügt über die grundlegenden Eigenschaften des zyklischen Modells und eignet sich daher sehr gut für die Verarbeitung von Text und Zeit Serie, ein allgemeines Grundmodell für Sequenzdaten wie Sprache. Darüber hinaus haben einige aktuelle Pionierforschungen die Anwendungsszenarien der Mamba-Architektur erweitert, sodass sie nicht nur Sequenzdaten verarbeiten, sondern auch in Bereichen wie Bildern und Karten verwendet werden kann, wie in Abbildung 7 dargestellt .
Das Ziel dieser Studien besteht darin, die hervorragende Fähigkeit von Mamba, langfristige Abhängigkeiten zu erlangen, voll auszunutzen und außerdem ihre Effizienz im Lern- und Argumentationsprozess zu nutzen. Tabelle 2 fasst diese Ergebnisse kurz zusammen.
Sequenzdaten beziehen sich auf Daten, die in einer bestimmten Reihenfolge gesammelt und organisiert werden, wobei die Reihenfolge der Datenpunkte von Bedeutung ist. Dieser Übersichtsbericht fasst umfassend die Anwendung von Mamba auf eine Vielzahl von Sequenzdaten zusammen, darunter natürliche Sprach-, Video-, Zeitreihen-, Sprach- und menschliche Bewegungsdaten. Einzelheiten finden Sie im Originalpapier. Im Gegensatz zu Sequenzdaten folgen nicht sequentielle Daten keiner bestimmten Reihenfolge. Seine Datenpunkte können in beliebiger Reihenfolge organisiert werden, ohne dass die Bedeutung der Daten wesentlich beeinträchtigt wird. Dieser Mangel an inhärenter Ordnung kann für wiederkehrende Modelle (RNN, SSM usw.), die speziell auf die Erfassung zeitlicher Abhängigkeiten in Daten ausgelegt sind, schwierig sein. Überraschenderweise haben einige neuere Forschungsergebnisse Mamba (einen repräsentativen SSM) erfolgreich in die Lage versetzt, nicht sequentielle Daten, einschließlich Bilder, Karten und Punktwolkendaten, effizient zu verarbeiten. Um die Wahrnehmungs- und Szenenverständnisfähigkeiten der KI zu verbessern, können mehrere modale Daten integriert werden, wie z. B. Sprache (sequentielle Daten) und Bilder (nicht sequentielle Daten). Eine solche Integration kann sehr wertvolle und ergänzende Informationen liefern. In jüngster Zeit waren multimodale große Sprachmodelle (MLLM) der beliebteste Forschungsschwerpunkt. Diese Art von Modell erbt die leistungsstarken Fähigkeiten großer Sprachmodelle (LLM), einschließlich leistungsstarker Sprachausdrücke und logischer Denkfähigkeit. Obwohl sich Transformer zur dominierenden Methode auf diesem Gebiet entwickelt hat, entwickelt sich Mamba auch zu einem starken Konkurrenten. Seine Leistung bei der Ausrichtung gemischter Quelldaten und der Erzielung einer linearen Komplexitätsskalierung mit der Sequenzlänge macht Mamba zu einem vielversprechenden Ersatz für Transformer. Hier sind einige bemerkenswerte Anwendungen von Mamba-basierten Modellen. Das Team teilte diese Anwendungen in die folgenden Kategorien ein: Verarbeitung natürlicher Sprache, Computer Vision, Sprachanalyse, Arzneimittelentwicklung, Empfehlungssysteme sowie Robotik und autonome Systeme. Wir werden es hier nicht zu sehr vorstellen. Einzelheiten finden Sie im Originalpapier. Herausforderungen und ChancenMamba Obwohl die Mamba-Forschung in einigen Bereichen herausragende Leistungen erbracht hat, steckt sie insgesamt noch in den Kinderschuhen und es müssen noch einige Herausforderungen bewältigt werden. Natürlich sind diese Herausforderungen auch Chancen.
- Wie man auf Mamba basierende Basismodelle entwickelt und verbessert;
- Wie man hardwarebewusstes Computing vollständig implementiert, um die Nutzung von Hardware wie GPU und TPU zu maximieren, um die Modelleffizienz zu verbessern; Wie man Mamba verbessert. Die Glaubwürdigkeit des Modells erfordert weitere Forschung zu Sicherheit und Robustheit, Fairness, Erklärbarkeit und Datenschutz und katastrophales Vergessen Mitigation, Retrieval Augmented Generation (RAG).
-
Atas ialah kandungan terperinci Satu artikel untuk memahami Mamba, pesaing terkuat Transformer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


 Tajuk kertas: Tinjauan Mamba
Tajuk kertas: Tinjauan Mamba







