
Rumah >Tutorial Perkakasan >Kajian perkakasan >Model besar mempunyai pemahaman bahasa mereka sendiri! Kertas MIT mendedahkan 'proses pemikiran' model besar
Model besar mempunyai pemahaman bahasa mereka sendiri! Kertas MIT mendedahkan 'proses pemikiran' model besar

- 王林asal
- 2024-08-17 15:40:45773semak imbas
Model besar boleh membentuk pemahaman anda sendiri tentang dunia sebenar!
Kajian dari MIT mendapati bahawa apabila model menjadi lebih berkebolehan, pemahamannya tentang realiti mungkin melangkaui peniruan mudah.
Sebagai contoh, jika model besar tidak pernah menghidu bau, adakah itu bermakna ia tidak dapat memahami bau?
Penyelidikan mendapati ia boleh mensimulasikan beberapa konsep secara spontan untuk memudahkan pemahaman.
Penyelidikan ini bermakna model besar dijangka mempunyai pemahaman yang lebih mendalam tentang bahasa dan dunia pada masa hadapan.

Pengarang kertas ini ialah pelajar kedoktoran Cina Charles Jin dan penyelianya Profesor Martin Rinard dari Makmal Komputer dan Kepintaran Buatan MIT (CSAIL).
Dalam kajian itu, penulis meminta model besar untuk hanya mempelajari teks kod, dan mendapati model itu secara beransur-ansur memahami maksud di sebaliknya.
Profesor Rinard berkata bahawa penyelidikan ini secara langsung menangani persoalan teras kecerdasan buatan moden -
Sama ada keupayaan model besar hanya disebabkan oleh korelasi statistik berskala besar, atau adakah ia menjana pemahaman bermakna tentang masalah kehidupan sebenar mereka. bertujuan untuk menyelesaikan?
△Sumber: laman web rasmi MIT
Pada masa yang sama, penyelidikan ini juga mencetuskan banyak perbincangan.
Sesetengah netizen berkata walaupun model besar mungkin memahami bahasa secara berbeza daripada manusia, kajian ini sekurang-kurangnya menunjukkan model itu melakukan lebih daripada sekadar menghafal data latihan.

Biarkan model besar mempelajari kod tulen
Untuk meneroka sama ada model besar boleh menghasilkan pemahaman tahap semantik, pengarang membina set data sintetik yang terdiri daripada kod program dan input dan output yang sepadan.
Atur cara kod ini ditulis dalam bahasa pengajaran yang dipanggil Karel dan digunakan terutamanya untuk melaksanakan tugas robot menavigasi dalam dunia grid 2D.
Dunia grid ini terdiri daripada grid 8x8, setiap grid boleh mengandungi halangan, penanda atau ruang terbuka. Robot boleh bergerak antara grid dan melakukan operasi seperti meletakkan/mengambil penanda.
Bahasa Karel mengandungi 5 operasi primitif - bergerak (ke hadapan satu langkah), belok Kiri (belok kiri 90 darjah), belok Kanan (belok kanan 90 darjah), pickMarker (penanda ambil), putMarker (penanda tempat), program ini terdiri daripada Urutan operasi primitif ini.
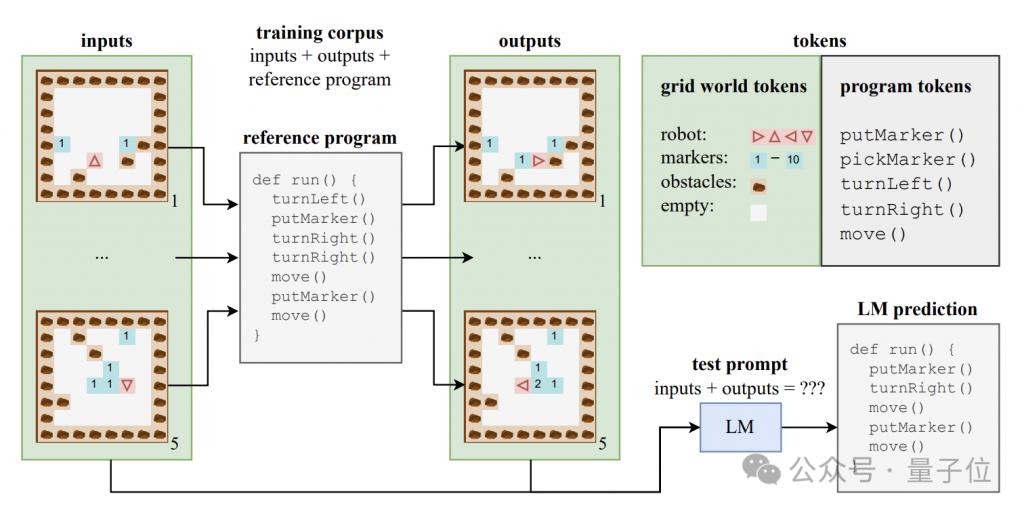
Pengarang secara rawak menghasilkan set latihan yang mengandungi 500,000 program Karel, setiap program panjang antara 6 dan 10.
Setiap sampel latihan terdiri daripada tiga bahagian: 5 keadaan input, 5 keadaan output dan kod program lengkap Keadaan input dan output dikodkan ke dalam rentetan dalam format tertentu.
Menggunakan data ini, pengarang melatih varian model CodeGen bagi seni bina Transformer standard.
Semasa proses latihan, model boleh mengakses maklumat input dan output serta awalan program dalam setiap sampel, tetapi ia tidak dapat melihat trajektori lengkap dan keadaan perantaraan pelaksanaan program.
Selain set latihan, penulis juga membina set ujian yang mengandungi 10,000 sampel untuk menilai prestasi generalisasi model.
Untuk mengkaji sama ada model bahasa memahami semantik di sebalik kod, dan pada masa yang sama memperoleh pemahaman yang mendalam tentang "proses pemikiran" model, penulis mereka bentuk gabungan pengesan termasuk pengelas linear dan satu/double tersembunyi lapisan MLP.
Input pengesan ialah keadaan tersembunyi model bahasa dalam proses penjanaan token program, dan sasaran ramalan ialah keadaan perantaraan pelaksanaan program, khususnya termasuk orientasi (arah) robot, mengimbangi relatif kepada kedudukan awal (kedudukan), dan Sama ada bahagian hadapan menghadapi halangan (halangan) adalah tiga ciri ini.
Semasa proses latihan model generatif, penulis merekodkan tiga ciri di atas setiap 4000 langkah, dan juga merekodkan keadaan tersembunyi model generatif untuk membentuk set data latihan untuk pengesan.
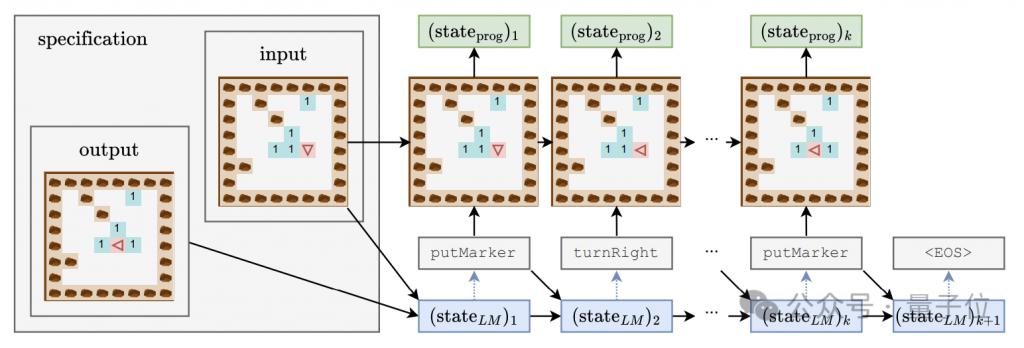
Tiga peringkat pembelajaran model besar
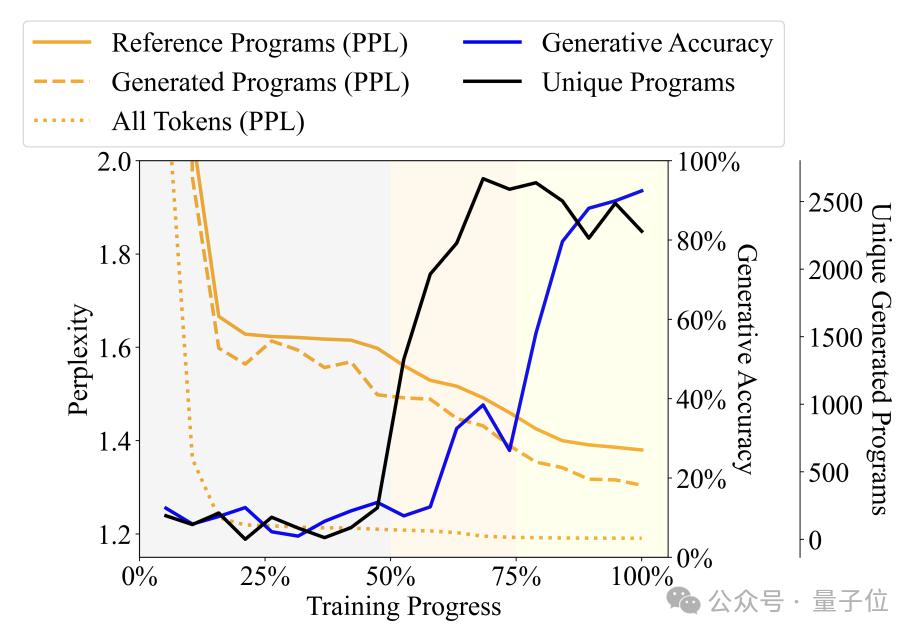
Dengan memerhatikan perubahan dalam kepelbagaian, kebingungan dan penunjuk lain program yang dihasilkan oleh model bahasa dengan proses latihan, penulis membahagikan proses latihan kepada tiga peringkat -
Peringkat Babbling ( Karut): Program keluaran sangat berulang dan ketepatan pengesan tidak stabil.
Peringkat pemerolehan tatabahasa: Kepelbagaian program meningkat dengan cepat, ketepatan penjanaan meningkat sedikit, dan kekeliruan berkurangan, menunjukkan bahawa model bahasa telah mempelajari struktur sintaksis program.
Peringkat pemerolehan semantik: Tahap kepelbagaian program dan penguasaan struktur sintaksis adalah stabil, tetapi ketepatan penjanaan dan prestasi pengesan dipertingkatkan dengan banyak, menunjukkan bahawa model bahasa telah mempelajari semantik program.
Secara khusus, peringkat Babbling menduduki 50% pertama daripada keseluruhan proses latihan Contohnya, apabila latihan mencapai kira-kira 20%, tidak kira apa spesifikasi input, model hanya akan menjana program tetap - "pickMarker" diulang 9 kali. .
Peringkat pemerolehan tatabahasa berada pada 50% hingga 75% daripada proses latihan, kekeliruan model pada program Karel telah menurun dengan ketara, menunjukkan bahawa model bahasa telah mula menyesuaikan diri dengan lebih baik kepada ciri statistik program Karel. ketepatan program yang dihasilkan telah meningkat Tidak banyak (dari kira-kira 10% kepada kira-kira 25%), tetapi masih tidak dapat menyelesaikan tugas dengan tepat.
Peringkat pemerolehan semantik ialah 25% terakhir Ketepatan program telah meningkat secara mendadak, daripada kira-kira 25% kepada lebih daripada 90%, dan program yang dihasilkan dapat menyelesaikan tugasan yang diberikan dengan tepat.
Eksperimen lanjut mendapati pengesan bukan sahaja boleh meramalkan langkah masa serentak pada masa t, tetapi juga meramalkan status pelaksanaan program bagi langkah masa berikutnya.
Sebagai contoh, anggap bahawa model generatif menjana token "pergerakan" pada masa t dan akan menjana "turnLeft" pada masa t+1.
Pada masa yang sama, program menyatakan pada masa t ialah robot menghadap ke utara dan terletak pada koordinat (0,0), manakala robot pada masa t+1 ialah robot akan menghadap ke barat, dengan kedudukan tidak berubah.
Jika pengesan berjaya meramalkan dari keadaan tersembunyi model bahasa pada masa t bahawa robot akan menghadap ke barat pada masa t+1, ini bermakna sebelum menjana "turnLeft", keadaan tersembunyi sudah mengandungi kesan ini operasi Maklumat perubahan status.
Fenomena ini menunjukkan bahawa model bukan sahaja mempunyai pemahaman semantik tentang bahagian program yang dihasilkan, tetapi pada setiap langkah penjanaan, ia telah pun menjangka dan merancang kandungan yang akan dihasilkan seterusnya, menunjukkan kemahiran Penaakulan berorientasikan masa depan awal.
Tetapi penemuan ini telah membawa persoalan baharu kepada penyelidikan ini -
Adakah peningkatan ketepatan yang diperhatikan dalam eksperimen benar-benar peningkatan dalam model generatif, atau adakah ia hasil daripada inferens pengesan itu sendiri?
Untuk menyelesaikan keraguan ini, penulis menambah eksperimen intervensi pengesanan semantik.
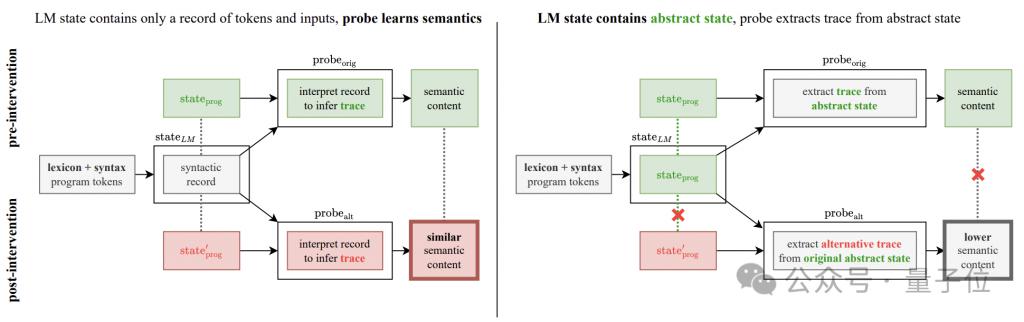
Idea asas eksperimen adalah untuk menukar peraturan tafsiran semantik operasi program, yang dibahagikan kepada dua kaedah: "flip" dan "musuh".
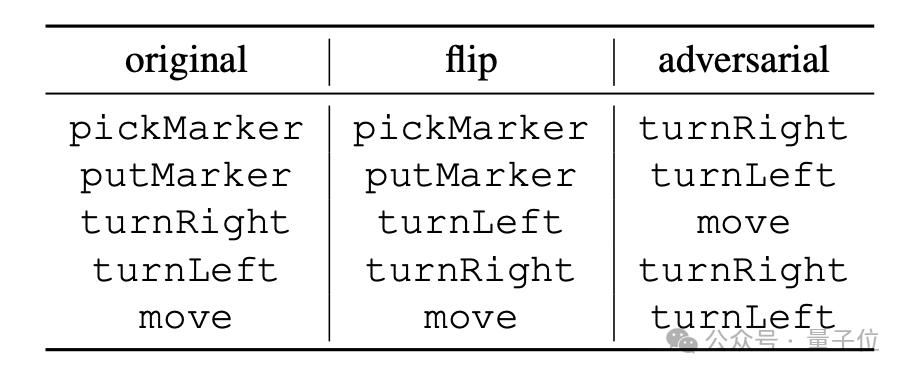
"flip" ialah pembalikan paksa maksud arahan Contohnya, "turn Right" secara paksa ditafsirkan sebagai "turn left". "musuh" adalah untuk memaksa Semantik yang sepadan dengan semua arahan dikocok secara rawak, seperti yang ditunjukkan dalam jadual di bawah.
 Jika keadaan tersembunyi model generatif hanya mengekod struktur sintaksis atur cara dan bukannya maklumat semantik, maka pengesan masih boleh mengekstrak maklumat semantik yang diubah daripada keadaan tersembunyi dengan prestasi yang sama.
Jika keadaan tersembunyi model generatif hanya mengekod struktur sintaksis atur cara dan bukannya maklumat semantik, maka pengesan masih boleh mengekstrak maklumat semantik yang diubah daripada keadaan tersembunyi dengan prestasi yang sama.
Sebaliknya, jika prestasi pengesan menurun dengan ketara, ini bermakna peningkatan prestasi yang ditunjukkan oleh pengesan sememangnya kerana keadaan tersembunyi model generatif mengekod semantik sebenar.
Hasil eksperimen menunjukkan bahawa prestasi pengesan menurun dengan ketara di bawah kedua-dua semantik baharu.
Terutamanya lebih jelas dalam mod "musuh", yang juga konsisten dengan ciri bahawa semantik dalam mod ini berbeza dengan ketara daripada semantik asal.
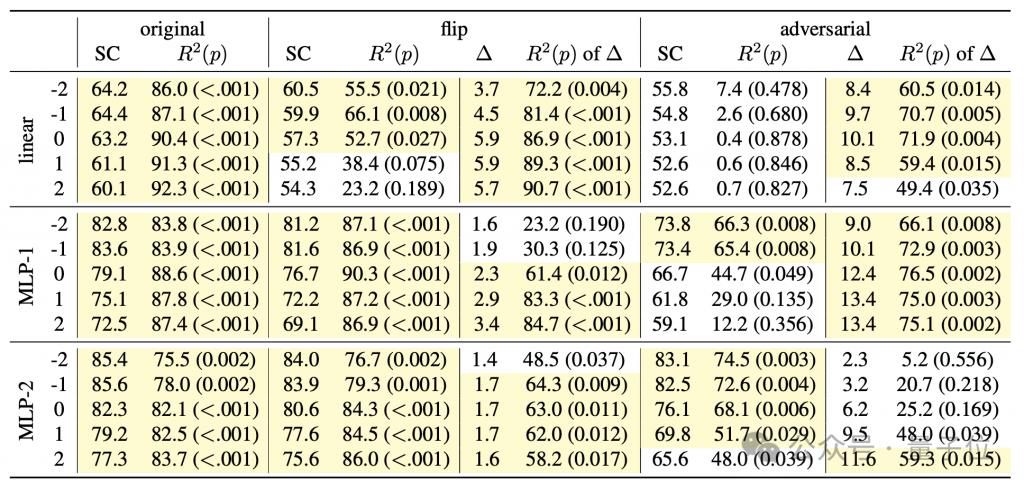 Hasil ini sangat menolak kemungkinan pengesan "mempelajari pemetaan semantik dengan sendirinya", seterusnya mengesahkan bahawa model generatif sememangnya memahami maksud kod.
Hasil ini sangat menolak kemungkinan pengesan "mempelajari pemetaan semantik dengan sendirinya", seterusnya mengesahkan bahawa model generatif sememangnya memahami maksud kod.
Alamat kertas:
https://icml.cc/virtual/2024/poster/34849
Pautan rujukan:
[ 1 ] https://news.mit.edu/2024/llms-develop-own- pemahaman-tentang-realiti-sebagai-kebolehan-bahasa-meningkatkan-0814
[ 2 ] https://www.reddit.com/r/LocalLLaMA/comments/1esxkin/llms_develop_their_own_understanding_of_reality/
🎜🎜🎜
Atas ialah kandungan terperinci Model besar mempunyai pemahaman bahasa mereka sendiri! Kertas MIT mendedahkan 'proses pemikiran' model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Dibenci oleh NPC pintar Ni Shuihan membuatkan saya berasa sedih...
- Pengukuran sebenar perbandingan kekuatan isyarat antara iPhone 15 dan Mate60P, keputusan didedahkan
- Ujian isyarat Huawei Mate 60 Pro: Terdapat penyesalan, tetapi terdapat lebih banyak kejutan
- Hargai daya tarikan pelbagai aspek Aichir Time Elf: segar dan pintar, serta pintar dan pelbagai fungsi
- Keputusan ujian sebenar panggilan satelit Huawei: kualiti bunyi melebihi telefon satelit profesional