Model besar seni bina Mamba sekali lagi mencabar Transformer.
Adakah model seni bina Mamba akhirnya akan "berdiri" kali ini? Sejak pelancaran awalnya pada Disember 2023, Mamba telah muncul sebagai pesaing serius kepada Transformer. Sejak itu, model menggunakan seni bina Mamba terus muncul, seperti Codestral 7B, model besar sumber terbuka pertama berdasarkan seni bina Mamba yang dikeluarkan oleh Mistral. Hari ini, Institut Inovasi Teknologi Abu Dhabi (TII) mengeluarkan model Mamba sumber terbuka baharu – Falcon Mamba 7B. 
Mari kita ringkaskan dahulu sorotan Falcon Mamba 7B: ia boleh mengendalikan jujukan pada sebarang panjang tanpa meningkatkan storan memori, dan ia boleh berjalan pada satu GPU A10 24GB. Anda boleh melihat dan menggunakan Falcon Mamba 7B pada Muka Memeluk Model penyahkod sebab ini sahaja menggunakan novel Mamba State Space Language Model (SSLM) seni bina untuk mengendalikan pelbagai tugas penjanaan Teks. Berdasarkan keputusan, Falcon Mamba 7B mengatasi model terkemuka dalam kelas saiznya pada beberapa penanda aras, termasuk Llama 3 8B Meta, Llama 3.1 8B dan Mistral 7B.
Falcon Mamba 7B terbahagi kepada empat model varian, iaitu versi asas, versi penalaan halus arahan, versi 4bit dan versi penalaan halus arahan 4bit.
Sebagai model sumber terbuka, Falcon Mamba 7B mengguna pakai lesen berasaskan Apache 2.0 "Falcon License 2.0" untuk menyokong tujuan penyelidikan dan aplikasi.
Alamat Muka Berpeluk: https://huggingface.co/tiiuae/falcon-mamba-7bFalcon Mamba 7B juga telah menjadi sumber terbuka TII ketiga selepas Falcon 180B, Fourlcon40B dan Falcon model, dan ia adalah model seni bina Mamba SSLM yang pertama.
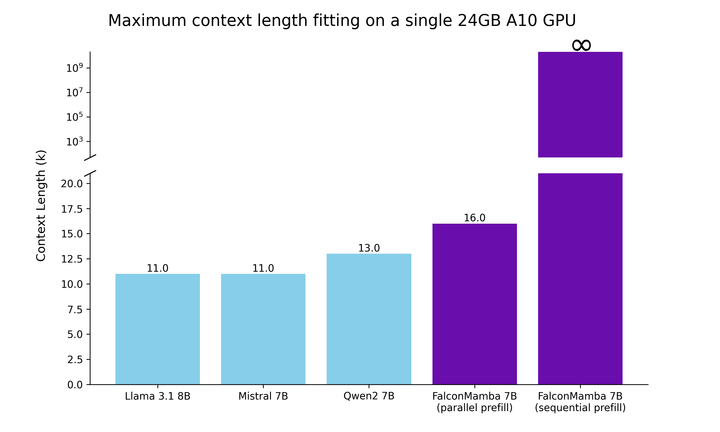
Model Mamba tulen berskala besar yang pertamaSejak sekian lama, model berasaskan Transformer telah mendominasi AI generatif Walau bagaimanapun, penyelidik mendapati bahawa seni bina Transformer mengalami kesukaran memproses maklumat teks yang panjang mungkin dihadapi. Pada asasnya, mekanisme perhatian dalam Transformer memahami konteks dengan membandingkan setiap perkataan (atau token) dengan setiap perkataan dalam teks, yang memerlukan lebih kuasa pengkomputeran dan keperluan memori untuk mengendalikan tetingkap konteks yang semakin meningkat. Tetapi jika sumber pengkomputeran tidak dikembangkan dengan sewajarnya, kelajuan inferens model akan menjadi perlahan dan teks yang melebihi panjang tertentu tidak boleh diproses. Untuk mengatasi halangan ini, seni bina State Space Language Model (SSLM), yang berfungsi dengan mengemas kini keadaan secara berterusan sambil memproses perkataan, telah muncul sebagai alternatif yang menjanjikan dan sedang digunakan oleh banyak institusi termasuk TII jenis ini. Falcon Mamba 7B menggunakan seni bina SSM Mamba yang asalnya dicadangkan dalam kertas kerja Disember 2023 oleh penyelidik di Carnegie Mellon University dan Princeton University. Seni bina menggunakan mekanisme pemilihan yang membolehkan model melaraskan parameternya secara dinamik berdasarkan input. Dengan cara ini, model boleh memfokus pada atau mengabaikan input tertentu, sama seperti cara mekanisme perhatian berfungsi dalam Transformer, sambil menyediakan keupayaan untuk memproses urutan teks yang panjang (seperti keseluruhan buku) tanpa memerlukan memori tambahan atau sumber pengkomputeran. TII menyatakan bahawa pendekatan ini menjadikan model itu sesuai untuk tugasan seperti terjemahan mesin peringkat perusahaan, ringkasan teks, visi komputer dan tugas pemprosesan audio, serta anggaran dan ramalan. Falcon Mamba 7B Data latihan adalah sehingga 5500GT, terutamanya terdiri daripada sumber data data teknikal yang Ditapis dan berkualiti tinggi daripada set data Web Berkualiti tinggi . Semua data diberi token menggunakan tokenizer Falcon-7B/11B. Sama seperti model siri Falcon yang lain, Falcon Mamba 7B dilatih menggunakan strategi latihan berbilang peringkat, panjang konteks ditingkatkan daripada 2048 kepada 8192. Di samping itu, diilhamkan oleh konsep pembelajaran kursus, TII dengan teliti memilih data bercampur sepanjang fasa latihan, dengan mempertimbangkan sepenuhnya kepelbagaian dan kerumitan data. Dalam peringkat latihan akhir, TII menggunakan set kecil data susun atur berkualiti tinggi (iaitu sampel daripada Fineweb-edu) untuk meningkatkan lagi prestasi. Proses latihan, hiperparameter 56) strategi digabungkan dengan ZeRO. Rajah di bawah menunjukkan butiran hiperparameter model, termasuk ketepatan, pengoptimum, kadar pembelajaran maksimum, pereputan berat dan saiz kelompok. Konkret wurde Falcon Mamba 7B mit dem AdamW-Optimierer und dem WSD-Lernratenplan (Warm-Stabilize-Decay) trainiert, und während des Trainingsprozesses der ersten 50 GT erhöhte sich die Batch-Größe von b_min=128 auf b_max=2048. In der stabilen Phase verwendet TII die maximale Lernrate η_max=6,4×10^−4 und senkt sie dann mithilfe eines Exponentialplans über 500GT auf den Minimalwert ab. Gleichzeitig nutzt TII BatchScaling in der Beschleunigungsphase, um die Lernrate η so anzupassen, dass die Adam-Rauschentemperatur konstant bleibt. Die gesamte Modelausbildung dauerte etwa zwei Monate. Um zu verstehen, wie Falcon Mamba 7B im Vergleich zu führenden Transformer-Modellen seiner Größenklasse abschneidet, führte die Studie einen Test durch, um zu ermitteln, was das Modell mit einem einzigen 24-GB-A10-GPU-Maximum-Kontext bewältigen kann Länge. Die Ergebnisse zeigen, dass Falcon Mamba in der Lage ist, sich an größere Sequenzen als das aktuelle Transformer-Modell anzupassen, während es theoretisch in der Lage ist, sich an unbegrenzte Kontextlängen anzupassen.
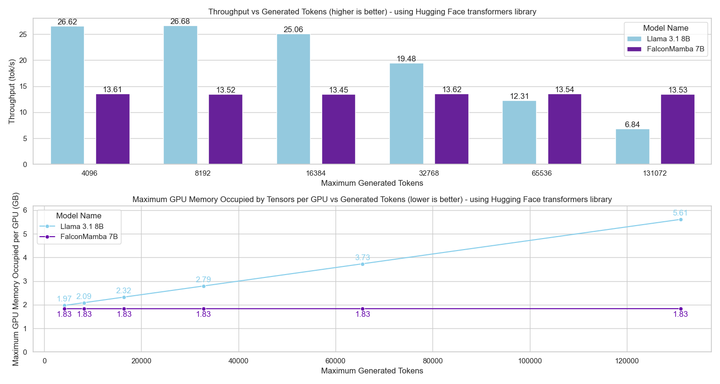
Als nächstes maßen die Forscher den Durchsatz der Modellgenerierung mit einer Stapelgröße von 1 und einer Hardwareeinstellung der H100-GPU. Die Ergebnisse sind in der folgenden Abbildung dargestellt. Falcon Mamba generiert alle Token mit konstantem Durchsatz, ohne den CUDA-Spitzenspeicher zu erhöhen. Bei Transformer-Modellen steigt der Spitzenspeicher und die Generierungsgeschwindigkeit verlangsamt sich, wenn die Anzahl der generierten Token steigt.
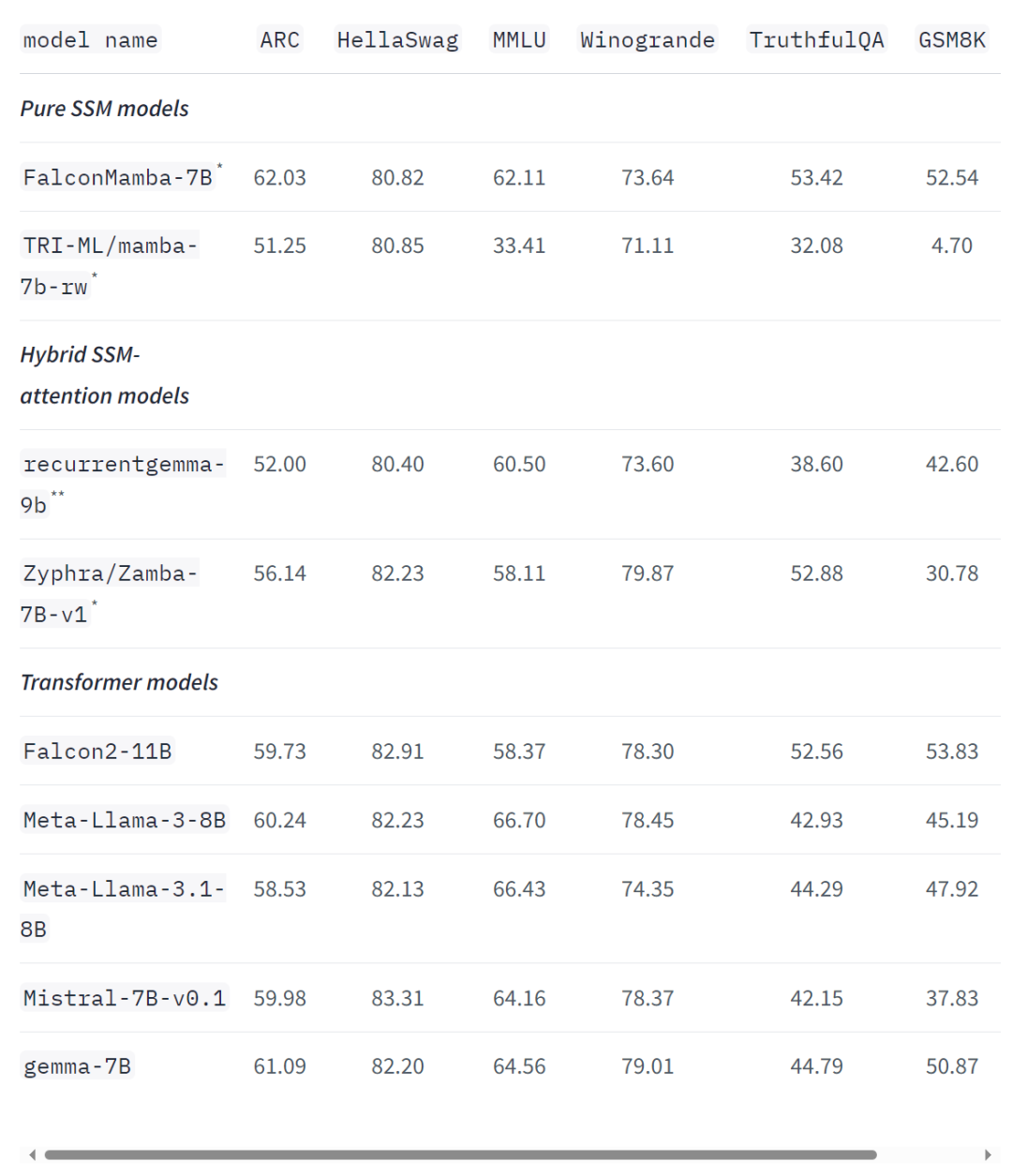
Selbst bei branchenüblichen Benchmarks schneidet das neue Modell besser ab als beliebte Transformatormodelle sowie reine und hybride Zustandsraummodelle oder kommt ihnen nahe. Zum Beispiel erzielte Falcon Mamba 7B in den Benchmarks Arc, TruthfulQA und GSM8K 62,03 %, 53,42 % bzw. 52,54 % und übertraf damit Llama 3 8B, Llama 3.1 8B, Gemma 7B und Mistral 7B. Allerdings liegt die Falcon Mamba 7B in den MMLU- und Hellaswag-Benchmarks weit hinter diesen Modellen zurück.
Der leitende Ermittler von TII, Hakim Hacid, sagte in einer Erklärung: Der Start von Falcon Mamba 7B stellt für die Agentur einen großen Schritt nach vorne dar, der neue Perspektiven inspiriert und den Vorstoß zur systematischen Erkundung nachrichtendienstlicher Erkenntnisse vorantreibt. Am TII erweitern sie die Grenzen von SSLM- und Transformatormodellen, um weitere Innovationen in der generativen KI anzuregen. Derzeit wurde die Falcon-Sprachmodellfamilie von TII mehr als 45 Millionen Mal heruntergeladen – was sie zu einer der erfolgreichsten LLM-Versionen in den VAE macht. Falcon Mamba 7B Papier wird bald veröffentlicht, Sie können einen Moment warten. https://huggingface.co/blog/falconmambahttps://venturebeat.com/ai/falcon-mamba-7bs-powerful -new-ai-architecture-offers-alternative-to-transformer-models/Atas ialah kandungan terperinci Seni bina bukan Transformer berdiri! Model besar tanpa perhatian tulen pertama, mengatasi gergasi sumber terbuka Llama 3.1. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn





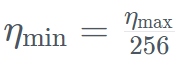 . Gleichzeitig nutzt TII BatchScaling in der Beschleunigungsphase, um die Lernrate η so anzupassen, dass die Adam-Rauschentemperatur
. Gleichzeitig nutzt TII BatchScaling in der Beschleunigungsphase, um die Lernrate η so anzupassen, dass die Adam-Rauschentemperatur 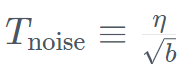 konstant bleibt.
konstant bleibt.