Sejak keluaran Sora, bidang penjanaan video AI menjadi lebih "sibuk". Dalam beberapa bulan lalu, kami telah menyaksikan Jimeng, Landasan Gen-3, Luma AI, dan Kuaishou Keling bergilir-gilir untuk meletup. Tidak seperti model terdahulu yang boleh dikenal pasti sebagai dijana AI sepintas lalu, kumpulan model video besar ini mungkin yang "terbaik" yang pernah kita lihat. Walau bagaimanapun, di sebalik prestasi menakjubkan model bahasa besar video (LLM) adalah set data video yang besar dan beranotasi halus, yang memerlukan kos yang sangat tinggi. Baru-baru ini, beberapa kaedah inovatif telah muncul dalam bidang penyelidikan yang tidak memerlukan latihan tambahan: menggunakan model bahasa besar imej terlatih untuk memproses tugas video secara langsung, sekali gus memintas proses latihan "mahal". Di samping itu, kebanyakan LLM video sedia ada mengalami dua kelemahan utama: (1) mereka hanya boleh mengendalikan input video dengan bilangan bingkai yang terhad, yang menyukarkan model untuk menangkap kandungan spatial dan temporal yang halus dalam video; (2) mereka Ia tidak mempunyai reka bentuk pemodelan temporal, tetapi hanya memasukkan ciri video ke dalam LLM, bergantung sepenuhnya pada keupayaan LLM untuk memodelkan gerakan. Sebagai tindak balas kepada masalah di atas, Para penyelidik Apple mencadangkan SlowFast-LLaVA (pendek kata SF-LLaVA). Model ini berdasarkan seni bina LLaVA-NeXT yang dibangunkan oleh pasukan Byte. Ia tidak memerlukan penalaan halus tambahan dan boleh digunakan di luar kotak. Diilhamkan oleh rangkaian dua aliran yang berjaya dalam bidang pengecaman tindakan, pasukan penyelidik mereka bentuk mekanisme input SlowFast novel untuk LLM video. Ringkasnya, SF-LLaVA akan memahami butiran dan gerakan dalam video melalui dua kelajuan pemerhatian yang berbeza (Perlahan dan Cepat).
- Laluan perlahan: ekstrak ciri pada kadar bingkai yang rendah sambil mengekalkan sebanyak mungkin butiran ruang (cth. kekalkan 24×24 token setiap 8 bingkai)
- Gunakan kadar bingkai yang tinggi:, tetapi jalankan pada kadar bingkai yang tinggi: saiz langkah pengumpulan spatial yang lebih besar untuk mengurangkan peleraian video untuk mensimulasikan konteks temporal yang lebih besar dan lebih fokus pada memahami keselarasan tindakan
Ini bersamaan dengan model yang mempunyai dua "mata": satu Lihat sahaja perlahan-lahan dan perhatikan butirannya; Ini menyelesaikan masalah kesakitan kebanyakan LLM video sedia ada dan boleh menangkap kedua-dua semantik spatial terperinci dan konteks temporal yang lebih panjang. 
Pautan kertas: https://arxiv.org/pdf/2407.15841Hasil eksperimen menunjukkan bahawa SF-LLaVA mengatasi kaedah bebas latihan sedia ada dengan kelebihan ketara dalam semua ujian penanda aras. Berbanding dengan model SFT yang diperhalusi dengan teliti, SF-LLaVA mencapai prestasi yang sama atau lebih baik. 
Seperti yang ditunjukkan dalam rajah di bawah, SF-LLaVA mengikuti proses LLM video tanpa latihan standard. Ia memerlukan video V dan soalan Q sebagai input dan mengeluarkan jawapan A yang sepadan. 
Untuk input, N bingkai diambil secara seragam daripada setiap video dengan sebarang saiz dan panjang, I = {I_1, I_2, ..., I_N}, dan tiada gabungan atau susunan khas bingkai video yang dipilih diperlukan. Ciri frekuensi yang diekstrak secara bebas dalam unit bingkai ialah F_v ∈ R^N×H×W, dengan H dan W ialah ketinggian dan lebar ciri bingkai masing-masing. Langkah seterusnya melibatkan pemprosesan selanjutnya F_v dalam kedua-dua laluan perlahan dan pantas serta menggabungkannya sebagai perwakilan video yang berkesan. Laluan perlahan secara seragam mencontohi ciri bingkai 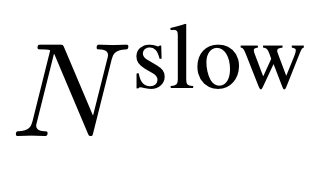 dari F_v, di mana
dari F_v, di mana 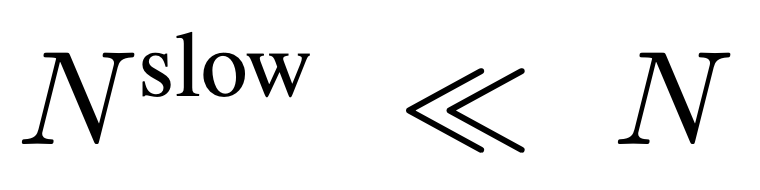 . Penyelidikan sebelum ini mendapati bahawa pengumpulan yang sesuai dalam dimensi ruang boleh meningkatkan kecekapan dan keteguhan penjanaan video. Oleh itu, pasukan penyelidik menggunakan proses pengumpulan dengan saiz langkah σ_h×σ_w pada F_v untuk mendapatkan ciri akhir:
. Penyelidikan sebelum ini mendapati bahawa pengumpulan yang sesuai dalam dimensi ruang boleh meningkatkan kecekapan dan keteguhan penjanaan video. Oleh itu, pasukan penyelidik menggunakan proses pengumpulan dengan saiz langkah σ_h×σ_w pada F_v untuk mendapatkan ciri akhir: 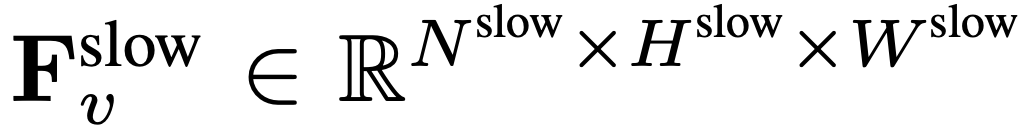 , di mana
, di mana 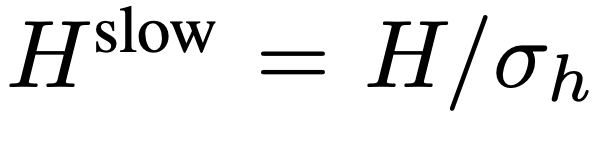 ,
, 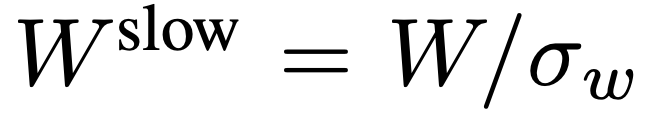 . Keseluruhan proses laluan perlahan ditunjukkan dalam Persamaan 2.
. Keseluruhan proses laluan perlahan ditunjukkan dalam Persamaan 2. 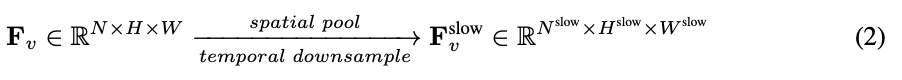
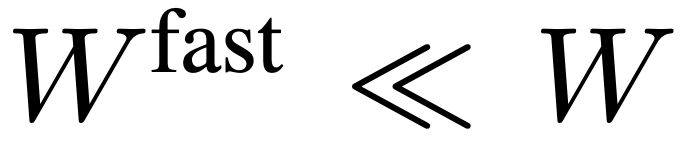
Laluan pantas mengekalkan semua ciri bingkai dalam F_v untuk menangkap sebanyak mungkin konteks temporal jarak jauh video. Khususnya, pasukan penyelidik menggunakan saiz langkah pengumpulan spatial  untuk menurunkan sampel F_v secara agresif untuk mendapatkan ciri akhir
untuk menurunkan sampel F_v secara agresif untuk mendapatkan ciri akhir 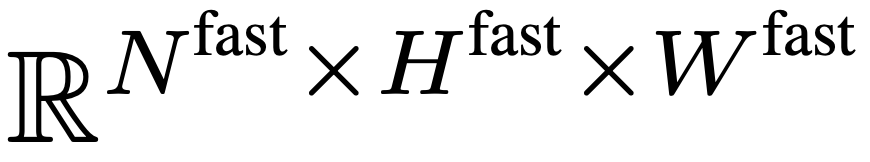 . Pasukan penyelidik menyediakan
. Pasukan penyelidik menyediakan  ,
,  supaya laluan pantas boleh menumpukan pada simulasi konteks temporal dan isyarat gerakan. Keseluruhan proses laluan perlahan ditunjukkan dalam Persamaan 3.
supaya laluan pantas boleh menumpukan pada simulasi konteks temporal dan isyarat gerakan. Keseluruhan proses laluan perlahan ditunjukkan dalam Persamaan 3. 
Akhir sekali, ciri video agregat diperoleh: 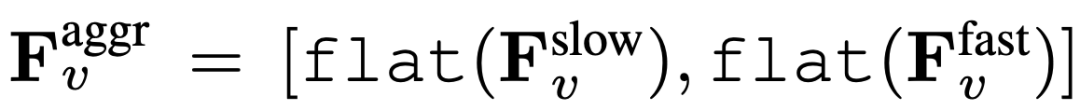 , di mana rata dan [, ] mewakili operasi merata dan penggabungan. Seperti yang ditunjukkan dalam ungkapan,
, di mana rata dan [, ] mewakili operasi merata dan penggabungan. Seperti yang ditunjukkan dalam ungkapan, 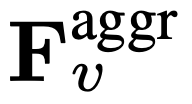 tidak memerlukan sebarang token khas untuk memisahkan laluan perlahan dan pantas. SF-LLaVA menggunakan sejumlah
tidak memerlukan sebarang token khas untuk memisahkan laluan perlahan dan pantas. SF-LLaVA menggunakan sejumlah 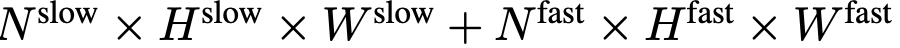 token video. Ciri visual video
token video. Ciri visual video 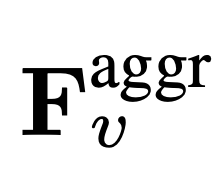 akan digabungkan dengan maklumat teks (seperti soalan yang ditanya oleh pengguna) dan dihantar sebagai data input kepada model bahasa besar (LLM) untuk diproses. Proses Lambat Cepat ditunjukkan dalam Persamaan 4.
akan digabungkan dengan maklumat teks (seperti soalan yang ditanya oleh pengguna) dan dihantar sebagai data input kepada model bahasa besar (LLM) untuk diproses. Proses Lambat Cepat ditunjukkan dalam Persamaan 4. 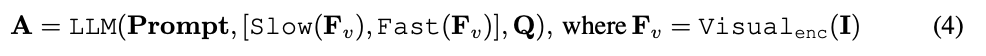
研究团队对 SF-LLaVA 进行了全面的性能评估,将其与当前 SOTA 免训练模型(如 IG-VLM 和 LLoVi)在多个视频问答任务中进行了对比。此外,他们还将其与经过视频数据集监督微调(SFT)的视频 LLM,例如 VideoLLaVA 和 PLLaVA 进行了比较。如下表所示,在开放式视频问答任务中,SF-LLaVA 在所有基准测试中都比现有的免训练方法表现得更好。具体来说,当分别搭载 7B 和 34B 参数规模的 LLM 时,SF-LLaVA 分别在 MSRVTT-QA 上比 IGVLM 高出 2.1% 和 5.0%,在 TGIF-QA 上高出 5.7% 和 1.5%,在 ActivityNet-QA 上高出 2.0% 和 0.8%。即使与经过微调的 SFT 方法相比,SF-LLaVA 在大多数基准测试中也展现了可比的性能,只有在 ActivityNet-QA 这一基准上,PLLaVA 和 LLaVA-NeXT-VideoDPO 略胜一筹。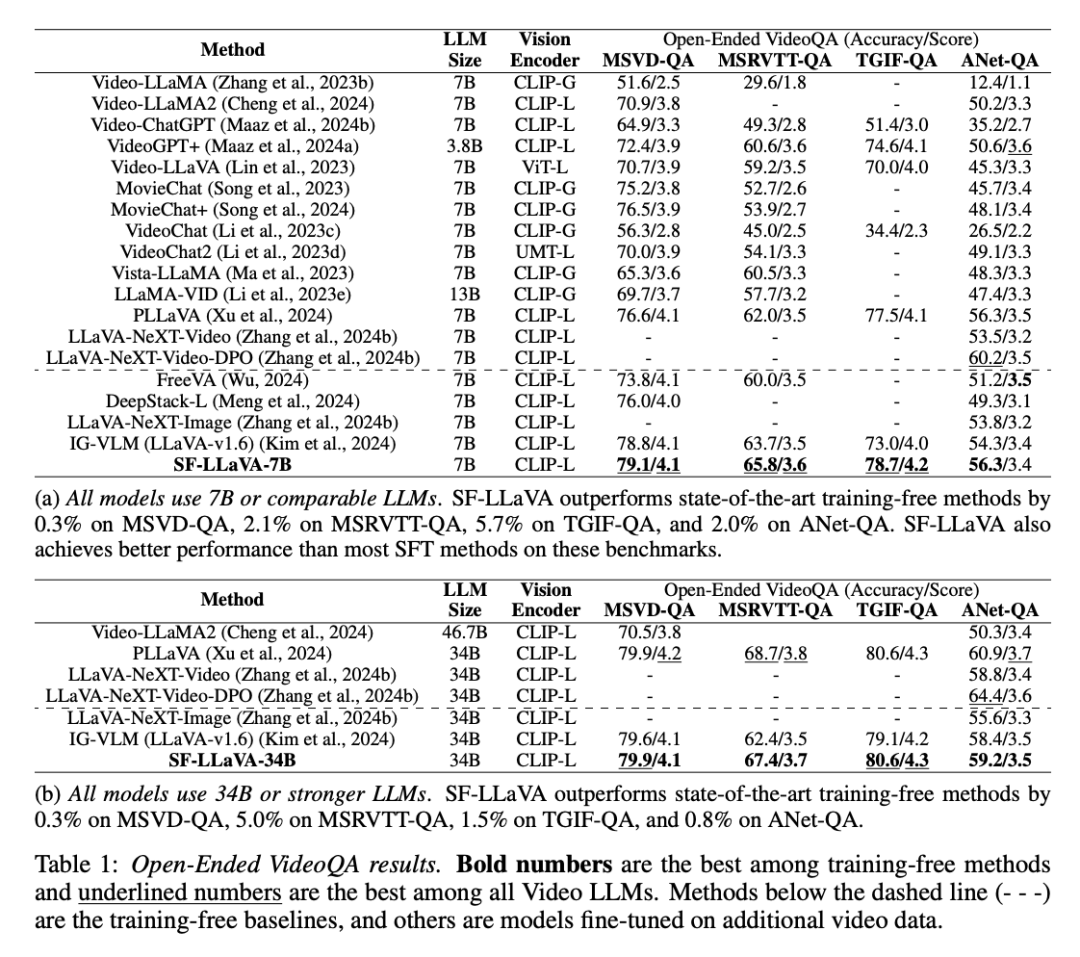
从下表中可见,在所有基准测试中,SF-LLaVA 在多项选择视频问答的表现都优于其他免训练方法。在要求复杂长时序推理的 EgoSchema 数据集中,SF-LLaVA7B 和 34B 的版本相较 IG-VLM 模型的得分分别高出 11.4% 和 2.2%。虽然 VideoTree 在基准测试中领先,因为它是基于 GPT-4 的专有模型,因而性能远高于开源 LLM。与 SFT 方法相比,SF-LLaVA 34B 模型在 EgoSchema 上也取得了更好的结果,这证实了 SlowFast 设计处理长视频方面的强大能力。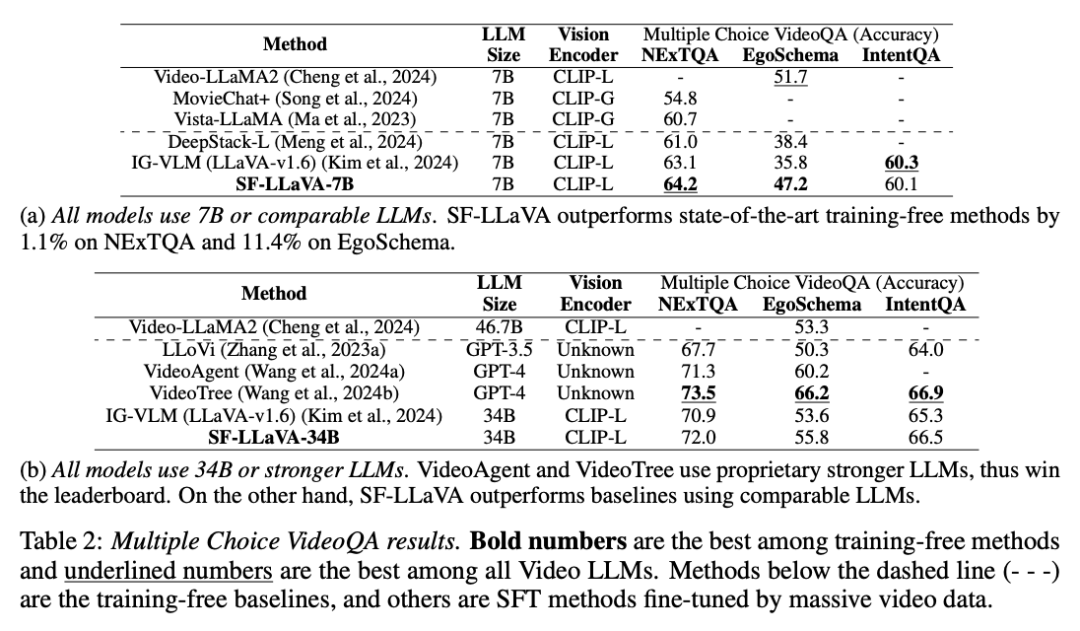
如表 3 所示,对于文本生成视频的任务,SF-LLaVA 也显示出了一些优势。SF-LLaVA-34B 在整体表现上超越了所有免训练的基准。尽管在细节取向方面,SF-LLaVA 略逊于 LLaVA-NeXT-Image。基于 SlowFast 设计,SF-LLaVA 可以用更少的视觉 token 覆盖更长的时间上下文,因此在时间理解任务中表现得格外出色。此外,在文生视频的表现上,SF-LLaVA-34B 也优于大多数 SFT 方法。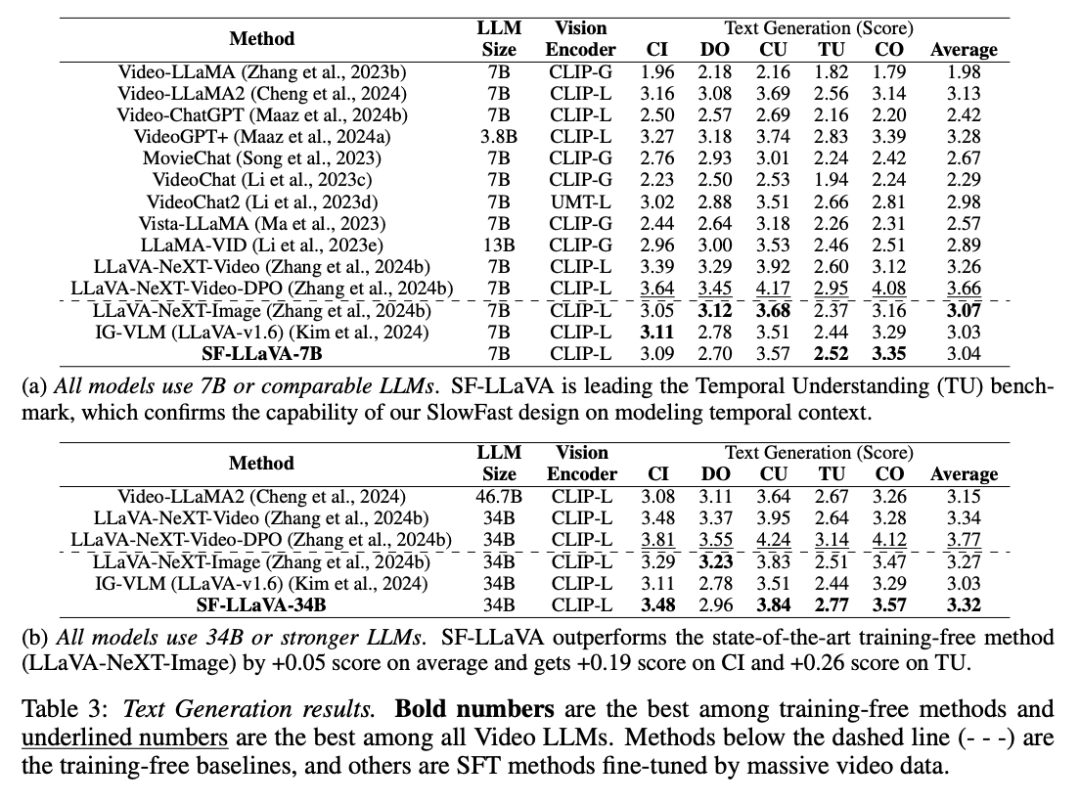
Atas ialah kandungan terperinci Tambahkan mata pantas dan perlahan pada model video, kaedah tanpa latihan baharu Apple mengatasi segala-galanya SOTA dalam beberapa saat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn

