
Rumah >pembangunan bahagian belakang >Tutorial Python >Merangkak Halaman dengan Tatal Infinite menggunakan Scrapy dan Penulis Drama
Merangkak Halaman dengan Tatal Infinite menggunakan Scrapy dan Penulis Drama

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-08-10 06:58:331765semak imbas
Apabila merangkak tapak web dengan Scrapy, anda akan dengan cepat menjumpai pelbagai senario yang memerlukan anda menjadi kreatif atau berinteraksi dengan halaman yang anda cuba kikis. Salah satu senario ini ialah apabila anda perlu merangkak halaman tatal yang tidak terhingga. Halaman tapak web jenis ini memuatkan lebih banyak kandungan semasa anda menatal ke bawah halaman seperti suapan media sosial.
Sudah pasti terdapat lebih daripada satu cara untuk merangkak jenis halaman ini. Satu cara saya baru-baru ini mendekati perkara ini adalah dengan terus menatal sehingga panjang halaman berhenti meningkat (iaitu tatal ke bawah). Siaran ini melangkah melalui proses ini.
Siaran ini mengandaikan bahawa anda mempunyai projek Scrapy yang disediakan, dijalankan dan Spider yang boleh anda ubah suai dan jalankan.
Menggunakan Penulis Drama dengan Scrapy
Penyepaduan ini menggunakan pemalam scrapy-playwright untuk menyepadukan Playwright untuk Python dengan Scrapy. Penulis drama ialah perpustakaan automasi penyemak imbas tanpa kepala yang digunakan untuk berinteraksi dengan halaman web dan mengekstrak data.
Saya telah menggunakan uv untuk pemasangan dan pengurusan pakej Python.
Kemudian, saya menggunakan persekitaran maya terus dari uv dengan:
uv venv source .venv/bin/activate
Pasang pemalam scrapy-playwright dan Playwright dengan arahan berikut ke dalam persekitaran maya anda:
uv pip install scrapy-playwright
Pasang penyemak imbas yang anda mahu gunakan dengan Penulis Drama. Contohnya, untuk memasang Chromium, anda boleh menjalankan arahan berikut:
playwright install chromium
Anda juga boleh memasang pelayar lain seperti Firefox jika perlu.
Nota: Kod Scrapy dan penyepaduan Playwright di bawah hanya diuji dengan Chromium.
Kemas kini fail settings.py atau atribut custom_settings dalam labah-labah untuk menyertakan tetapan DOWNLOAD_HANDLERS dan PLAYWRIGHT_LAUNCH_OPTIONS.
# settings.py
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
PLAYWRIGHT_LAUNCH_OPTIONS = {
# optional for CORS issues
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
# optional for debugging
"headless": False,
},
Untuk PLAYWRIGHT_LAUNCH_OPTIONS anda boleh menetapkan pilihan tanpa kepala kepada False untuk membuka contoh penyemak imbas dan menonton proses berjalan. Ini bagus untuk nyahpepijat dan membina pengikis awal.
Menangani Isu CORS
Saya memberikan hujah tambahan untuk melumpuhkan keselamatan web dan mengasingkan asal. Ini berguna apabila anda merangkak tapak yang mempunyai isu CORS.
Sebagai contoh, mungkin terdapat situasi apabila aset JavaScript yang diperlukan tidak dimuatkan atau permintaan rangkaian tidak dibuat kerana CORS. Anda boleh mengasingkan perkara ini dengan lebih pantas dengan menyemak konsol penyemak imbas untuk ralat jika tindakan halaman tertentu (seperti mengklik butang) tidak berfungsi seperti yang diharapkan tetapi yang lain berfungsi.
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
}
Merangkak Halaman Tatal Tak Terhingga
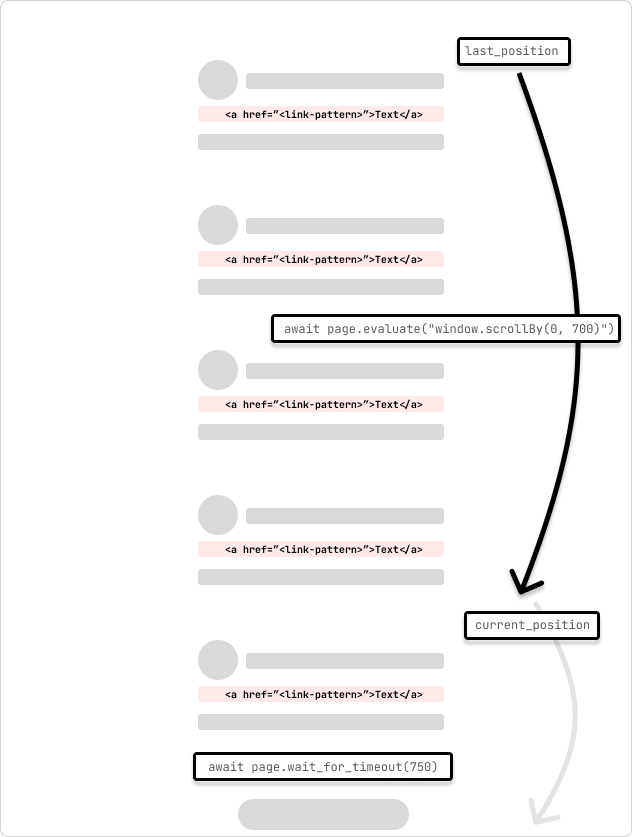
Ini ialah contoh labah-labah yang merangkak halaman tatal yang tidak terhingga. Labah-labah menatal halaman sebanyak 700 piksel dan menunggu 750ms untuk permintaan selesai. Labah-labah akan terus menatal sehingga ia mencapai bahagian bawah halaman yang ditunjukkan oleh kedudukan tatal yang tidak berubah semasa ia melalui gelung.
Saya sedang mengubah suai tetapan dalam labah-labah itu sendiri menggunakan custom_settings untuk mengekalkan tetapan di satu tempat. Anda juga boleh menambah tetapan ini pada fail settings.py.
# /<project>/spiders/infinite_scroll.py
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
class InfinitePageSpider(CrawlSpider):
"""
Spider to crawl an infinite scroll page
"""
name = "infinite_scroll"
allowed_domains = ["<allowed_domain>"]
start_urls = ["<start_url>"]
custom_settings = {
"TWISTED_REACTOR": "twisted.internet.asyncioreactor.AsyncioSelectorReactor",
"DOWNLOAD_HANDLERS": {
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
},
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
},
"LOG_LEVEL": "INFO",
}
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
async def parse(
self,
response,
):
page = response.meta["playwright_page"]
page.set_default_timeout(10000)
await page.wait_for_timeout(5000)
try:
last_position = await page.evaluate("window.scrollY")
while True:
# scroll by 700 while not at the bottom
await page.evaluate("window.scrollBy(0, 700)")
await page.wait_for_timeout(750) # wait for 750ms for the request to complete
current_position = await page.evaluate("window.scrollY")
if current_position == last_position:
print("Reached the bottom of the page.")
break
last_position = current_position
except Exception as error:
print(f"Error: {error}")
pass
print("Getting content")
content = await page.content()
print("Parsing content")
selector = Selector(text=content)
print("Extracting links")
links = selector.xpath("//a[contains(@href, '/<link-pattern>/')]//@href").getall()
print(f"Found {len(links)} links...")
print("Yielding links")
for link in links:
yield {"link": link}
Satu perkara yang saya pelajari ialah tiada dua halaman atau tapak yang sama jadi anda mungkin perlu melaraskan jumlah tatal dan masa menunggu untuk mengambil kira halaman tersebut dan juga sebarang kependaman dalam perjalanan pergi balik rangkaian untuk permintaan untuk lengkap. Anda boleh melaraskan ini secara dinamik secara pengaturcaraan dengan menyemak kedudukan tatal dan masa yang diperlukan untuk permintaan selesai.
Pada pemuatan halaman, saya menunggu lebih lama untuk aset dimuatkan dan halaman dipaparkan. Halaman Playwright dihantar kepada kaedah panggil balik parse dalam objek response.meta. Ini digunakan untuk berinteraksi dengan halaman dan menatal halaman. Ini dinyatakan dalam scrapy.Minta hujah dengan penulis drama=True and playwright_include_page=True options.
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
Labah-labah ini akan menatal halaman dengan page.evaluate dan kaedah JavaScript scrollBy() sebanyak 700 piksel dan kemudian menunggu selama 750ms untuk permintaan selesai. Kemudian, kandungan halaman Playwright disalin ke pemilih Scrapy dan mengekstrak pautan daripada halaman tersebut. Pautan kemudiannya diserahkan kepada saluran paip Scrapy untuk meneruskan pemprosesan.
Untuk situasi di mana permintaan halaman mula memuatkan kandungan pendua, anda boleh menambah semakan untuk melihat sama ada kandungan telah dimuatkan dan kemudian keluar dari gelung. Atau, jika anda mempunyai idea tentang bilangan beban tatal, anda boleh menambah pembilang untuk keluar dari gelung selepas beberapa tatal tambah/tolak penimbal.
Infinite Scroll with an Element Click
It's also possible that the page may have an element that you can scroll to (i.e. "Load more") that will trigger the next set of content to load. You can use the page.evaluate method to scroll to the element and then click it to load the next set of content.
...
try:
while True:
button = page.locator('//button[contains(., "Load more")]')
await button.wait_for()
if not button:
print("No 'Load more' button found.")
break
is_disabled = await button.is_disabled()
if is_disabled:
print("Button is disabled.")
break
await button.scroll_into_view_if_needed()
await button.click()
await page.wait_for_timeout(750)
except Exception as error:
print(f"Error: {error}")
pass
...
This method is useful when you know the page has a button that will load the next set of content. You can also use this method to click on other elements that will trigger the next set of content to load. The scroll_into_view_if_needed method will scroll the button or element into view if it is not already visible on the page. This is one of those scenarios when you will want to double-check the page actions with headless=False to see if the button is being clicked and the content is being loaded as expected before running a full crawl.
Note: As mentioned above, confirm that the page assets(.js) are loading correctly and that the network requests are being made so that the button (or element) is mounted and clickable.
Wrapping Up
Web crawling is a case-by-case scenario and you will need to adjust the code to fit the page that you are trying to scrape. The above code is a starting point to get you going with crawling infinite scroll pages with Scrapy and Playwright.
Hopefully, this helps to get you unblocked! ?
Subscribe to get my latest content by email -> Newsletter
Atas ialah kandungan terperinci Merangkak Halaman dengan Tatal Infinite menggunakan Scrapy dan Penulis Drama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!