Apabila kelajuan lelaran model besar menjadi lebih pantas dan lebih pantas, skala kluster latihan menjadi lebih besar dan lebih besar, dan kegagalan perisian dan perkakasan frekuensi tinggi telah menjadi titik kesakitan yang menghalang peningkatan lagi kecekapan latihan bertanggungjawab ke atas status semasa proses latihan Penyimpanan dan pemulihan telah menjadi kunci untuk mengatasi kegagalan latihan, memastikan kemajuan latihan dan meningkatkan kecekapan latihan.
Baru-baru ini, pasukan model ByteDance Beanbao dan Universiti Hong Kong bersama-sama mencadangkan ByteCheckpoint. Ini adalah sistem titik semak model besar yang berasal dari PyTorch, serasi dengan pelbagai rangka kerja latihan, dan menyokong pembacaan dan penulisan titik pemeriksaan yang cekap dan pembahagian semula automatik Berbanding dengan kaedah sedia ada, ia mempunyai peningkatan prestasi yang ketara dan kelebihan kemudahan penggunaan. Artikel ini memperkenalkan cabaran yang dihadapi oleh Checkpoint dalam meningkatkan kecekapan latihan model besar, meringkaskan idea penyelesaian ByteCheckpoint, reka bentuk sistem, teknologi pengoptimuman prestasi I/O dan keputusan percubaan dalam prestasi storan dan ujian prestasi baca.
Pegawai Meta baru-baru ini mendedahkan kadar kegagalan latihan Llama3 405B pada kluster latihan 16384 H100 80GB - hanya dalam 54 hari, 419 gangguan berlaku, dengan kemalangan purata setiap tiga jam, menarik perhatian ramai pengamal.
Seperti kata biasa dalam industri, satu-satunya kepastian untuk sistem latihan berskala besar ialah kegagalan perisian dan perkakasan. Apabila skala latihan dan saiz model meningkat, mengatasi kegagalan perisian dan perkakasan dan meningkatkan kecekapan latihan telah menjadi faktor yang mempengaruhi penting untuk lelaran model yang besar.
Titik pemeriksaan telah menjadi kunci untuk meningkatkan kecekapan latihan. Dalam laporan latihan Llama, pasukan teknikal menyebut bahawa untuk memerangi kadar kegagalan yang tinggi, pusat pemeriksaan yang kerap perlu dilakukan semasa proses latihan untuk menyimpan status model, pengoptimum dan pembaca data semasa latihan untuk mengurangkan kehilangan kemajuan latihan.
Pasukan model besar ByteDance Beanbao dan Universiti Hong Kong baru-baru ini mengumumkan keputusan - ByteCheckpoint, anak asli PyTorch, serasi dengan pelbagai rangka kerja latihan, dan sistem Checkpointing model besar yang menyokong pembacaan dan penulisan Checkpoint yang cekap dan semula automatik pembahagian.
Berbanding dengan kaedah garis dasar, ByteCheckpoint meningkatkan prestasi sehingga 529.22 kali pada penjimatan pusat pemeriksaan dan sehingga 3.51 kali pada pemuatan. Antara muka pengguna minimalis dan fungsi pembahagian semula automatik Checkpoint dengan ketara mengurangkan pemerolehan pengguna dan kos penggunaan serta meningkatkan kemudahan penggunaan sistem.
Keputusan kertas itu kini telah diumumkan kepada umum. 
- ByteCheckpoint: Sistem Pemeriksaan Bersatu untuk Pembangunan LLM
- Pautan kertas: https://team.doubao.com/zh/publication/bytecheckpoint-a-unified-checkpointing-system-for-llm-development?view_from =penyelidikan
Cabaran teknikal teknologi Checkpoint dalam latihan model besar Teknologi berkaitan Checkpoint semasa menghadapi sejumlah empat cabaran dalam menyokong kecekapan - Reka bentuk sistem sedia ada mempunyai kelemahan, yang meningkatkan dengan ketara overhed I/O tambahan bagi latihan
Dalam proses melatih model bahasa besar (LLM) peringkat industri, status latihan perlu melepasi teknologi pusat pemeriksaan ( Checkpointing) untuk penjimatan dan kegigihan. Lazimnya, Pusat Pemeriksaan terdiri daripada 5 bahagian (model, pengoptimum, pembaca data, nombor rawak dan konfigurasi yang ditentukan pengguna). Proses ini selalunya membawa sekatan peringkat minit kepada latihan, yang menjejaskan kecekapan latihan dengan serius.
Dalam senario latihan berskala besar menggunakan sistem storan berterusan jauh, sistem Checkpointing sedia ada tidak menggunakan sepenuhnya GPU ke salinan memori CPU (salinan D2H), bersiri, simpan setempat dan muat naik ke storan semasa proses simpan Checkpoint . Kebebasan pelaksanaan setiap peringkat sistem.
Selain itu, potensi pemprosesan selari bagi proses latihan yang berbeza berkongsi tugasan capaian Checkpoint belum diterokai sepenuhnya. Kekurangan reka bentuk sistem ini meningkatkan overhed I/O tambahan yang disebabkan oleh latihan Checkpoint. . RLHF) dan tugasan yang berbeza (daripada Apabila memindahkan Pusat Pemeriksaan antara tugas latihan (menarik Pusat Pemeriksaan dari peringkat berbeza untuk penilaian automatik), biasanya perlu untuk membahagikan semula Pusat Pemeriksaan yang disimpan dalam sistem storan berterusan (Pemeriksaan Semula) untuk menyesuaikan diri dengan keselarian baharu konfigurasi tugas hiliran dan kuota untuk sumber GPU yang tersedia.
Sistem pemeriksaan sedia ada [1, 2, 3, 4] semuanya menganggap bahawa konfigurasi selari dan sumber GPU kekal tidak berubah semasa penyimpanan dan pemuatan, dan tidak dapat mengendalikan keperluan untuk pembahagian semula pusat pemeriksaan. Penyelesaian biasa dalam industri pada masa ini ialah menyesuaikan skrip penggabungan atau pemisahan semula Checkpoint untuk model yang berbeza. Kaedah ini membawa banyak overhed pembangunan dan penyelenggaraan, dan mempunyai kebolehskalaan yang lemah.
Modul Checkpoint bagi rangka kerja latihan yang berbeza dipecah-pecahkan, yang membawa cabaran kepada pengurusan bersatu dan pengoptimuman prestasi Checkpoint
platform latihan, selalunya dalam industri
bekerjasama berdasarkan ciri tugas , pilih rangka kerja yang sesuai (Megatron-LM [5], FSDP [6], DeepSpeed [7], veScale [8, 9]) untuk latihan, dan simpan Checkpoint ke sistem storan. Walau bagaimanapun, rangka kerja latihan yang berbeza ini mempunyai format pusat pemeriksaan bebas dan modul membaca dan menulis mereka sendiri. Reka bentuk modul pusat pemeriksaan bagi rangka kerja latihan yang berbeza adalah berbeza, yang membawa cabaran kepada pengurusan pusat pemeriksaan bersatu dan pengoptimuman prestasi sistem asas. - Pengguna sistem latihan yang diedarkan menghadapi pelbagai masalah
Dari perspektif pengguna sistem latihan (saintis penyelidikan AI), apabila pengguna menggunakan sistem latihan (saintis penyelidikan AI atau checkpoint). sering diganggu oleh tiga masalah: 1) Cara menyimpan pusat pemeriksaan dengan cekap dan menyelamatkan pusat pemeriksaan tanpa menjejaskan kecekapan latihan. - 2) Bagaimana untuk membahagikan semula Checkpoint dan membacanya dengan betul mengikut paralelisme baharu untuk Checkpoint yang disimpan di bawah satu darjah selari. 3) Cara memuat naik produk terlatih ke sistem storan awan (HDFS, S3, dsb.) dan mengurus berbilang sistem storan secara manual, yang mahal untuk dipelajari dan digunakan oleh pengguna.
Sebagai tindak balas kepada masalah di atas, pasukan model ByteDance Beanbao dan makmal Profesor Wu Chuan dari Universiti Hong Kong bersama-sama melancarkan ByteCheckpoint.
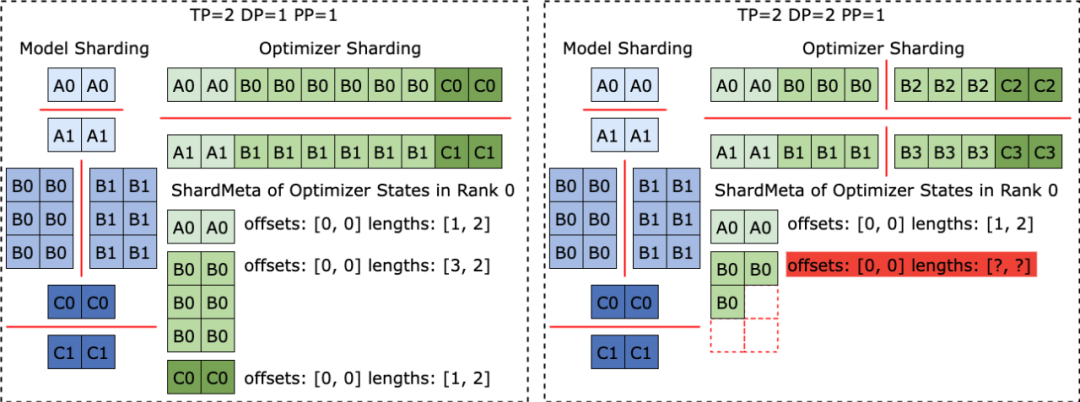
ByteCheckpoint ialah sistem pemeriksaan teragih berprestasi tinggi yang disatukan dengan pelbagai rangka kerja latihan, menyokong berbilang bahagian belakang storan dan mempunyai keupayaan untuk membahagikan semula pusat pemeriksaan secara automatik. ByteCheckpoint menyediakan antara muka pengguna yang ringkas dan mudah digunakan, melaksanakan sebilangan besar teknologi pengoptimuman prestasi I/O untuk meningkatkan prestasi storan dan bacaan pusat pemeriksaan, dan menyokong pemindahan fleksibel pusat pemeriksaan dalam tugasan dengan konfigurasi selari yang berbeza. Reka bentuk sistem lelisme.Kepingan Tensor (Tensor Shard) model dalam rangka kerja latihan dan pengoptimum yang berbeza disimpan dalam fail storan dan maklumat meta (TensorMeta, ShardMeta, ByteMeta) disimpan dalam fail metadata unik di seluruh dunia.
Apabila menggunakan konfigurasi selari yang berbeza untuk membaca Checkpoint, seperti yang ditunjukkan dalam rajah di bawah, setiap proses latihan hanya perlu menetapkan meta-maklumat pertanyaan mengikut selari semasa untuk mendapatkan lokasi penyimpanan tensor yang diperlukan oleh proses . Kemudian baca terus mengikut kedudukan untuk merealisasikan pembahagian semula pusat pemeriksaan.
Penyelesaian bijak kepada segmentasi tensor yang tidak teraturApabila rangka kerja latihan yang berbeza dijalankan, mereka sering meratakan bentuk tensor dalam model atau pengoptimum ke dalam satu dimensi, dengan itu meningkatkan prestasi. Operasi perataan ini membawa cabaran pembahagian tensor tidak teratur (Irregular Tensor Sharding) ke storan Checkpoint. Seperti yang ditunjukkan dalam rajah di bawah, dalam Megatron-LM (rangka kerja latihan model besar yang diedarkan yang dibangunkan oleh NVIDIA) dan veScale (rangka kerja latihan model besar teragih asli PyTorch yang dibangunkan oleh ByteDance), parameter model sepadan dengan Keadaan pengoptimum akan diratakan menjadi satu dimensi, digabungkan, dan kemudian dipecah mengikut keselarian data. Ini mengakibatkan tensor terpecah secara tidak teratur kepada proses yang berbeza, dan meta-maklumat hirisan tensor tidak boleh diwakili menggunakan tuple offset dan panjang, menjadikan penyimpanan dan pembacaan sukar.
Masalah segmentasi tensor yang tidak teratur juga wujud dalam rangka kerja FSDP. Untuk menghapuskan kepingan tensor yang dipotong secara tidak teratur, rangka kerja FSDP akan melaksanakan komunikasi set semua kumpul dan operasi salinan D2H pada kepingan tensor satu dimensi pada semua proses sebelum menyimpan Pusat Pemeriksaan untuk mendapatkan tensor terbahagi yang lengkap. Penyelesaian ini membawa komunikasi yang besar dan overhed penyegerakan GPU-CPU yang kerap, yang menjejaskan prestasi storan Checkpoint dengan serius. Untuk menangani masalah ini, ByteCheckpoint mencadangkan teknologi Penggabungan Tensor Asynchronous. ByteCheckpoint mula-mula mengetahui tensor terbelah yang tidak teratur dalam proses yang berbeza, dan kemudian menggunakan komunikasi P2P tak segerak untuk mengagihkan tensor tidak sekata ini kepada proses yang berbeza untuk penggabungan. Semua operasi menunggu (Tunggu) komunikasi P2P dan tensor D2H untuk tensor tidak teratur ini ditangguhkan sehingga mereka akan memasuki fasa bersiri, dengan itu menghapuskan penyegerakan yang kerap dan meningkatkan komunikasi dengan proses penyimpanan Checkpoint yang lain. . Simpan ) dan baca (Muat) antara muka. Lapisan Perancang akan menjana pelan akses untuk proses latihan yang berbeza berdasarkan objek akses, dan menyerahkannya kepada lapisan Pelaksanaan untuk melaksanakan tugas I/O sebenar.
Lapisan Pelaksanaan melaksanakan tugas I/O dan berinteraksi dengan lapisan Storan, menggunakan pelbagai teknologi pengoptimuman I/O untuk akses pusat pemeriksaan berprestasi tinggi.
Lapisan Storan menguruskan bahagian belakang storan yang berbeza dan melakukan pengoptimuman yang sepadan mengikut bahagian belakang storan yang berbeza semasa tugasan I/O.
Reka bentuk berlapis meningkatkan kebolehskalaan sistem untuk menyokong lebih banyak rangka kerja latihan dan bahagian belakang storan pada masa hadapan. Kes penggunaan API
Kes penggunaan API ByteCheckpoint adalah seperti berikut: ByteCheckpoint provides a minimalist API, reducing the user’s cost of getting started. When storing and reading Checkpoints, users only need to call the storage and loading functions, passing in the content to be stored and read, the file system path and various performance optimization options. I/O performance optimization technologyCheckpoint storage optimizationAs shown in the figure below, ByteCheckpoint Designed a fully asynchronous storage pipeline (Save Pipeline), splits the different stages of Checkpoint storage (P2P tensor transfer, D2H replication, serialization, saving local and uploading file systems) to achieve efficient pipeline execution.
Avoid repeated memory allocationIn the D2H copy process, ByteCheckpoint uses a pinned memory pool (Pinned Memory Pool), which reduces the time overhead of repeated memory allocation. In addition, in order to reduce the additional time overhead caused by synchronously waiting for fixed memory pool recycling in high-frequency storage scenarios, ByteCheckpoint adds a Ping-Pong buffering mechanism based on the fixed memory pool. Two independent memory pools alternately play the role of read and write buffers, interacting with the GPU and I/O workers that perform subsequent I/O operations, further improving storage efficiency.
In data-parallel (Data-Parallel or DP) training, the model is redundant between different data-parallel process groups (DP Group). ByteCheckpoint adopts a load balancing algorithm Evenly distribute redundant model tensors to different process groups for storage, effectively improving Checkpoint storage efficiency. Checkpoint read optimizationAs shown in the figure, when changing the parallelism to read Checkpoint, the new training process may only need to start from the original Read part of it from a tensor slice. ByteCheckpoint uses on-demand partial file reading (Partial File Reading) technology to directly read the required file fragments from remote storage to avoid downloading and reading unnecessary data.
In data-parallel (Data-Parallel or DP) training, the model is redundant between different data parallel process groups (DP Group), and different process groups will repeatedly read the same tensor slice. In large-scale training scenarios, different process groups send a large number of requests to remote persistent storage systems (such as HDFS) at the same time, which will put huge pressure on the storage system. In order to eliminate repeated data reading, reduce the requests sent to HDFS by the training process, and optimize loading performance, ByteCheckpoint evenly distributes the same tensor slice reading tasks to different processes, and reads the remote files. While fetching, the idle bandwidth between GPUs is used for tensor slice transmission.
Experimental configurationThe team uses DenseGPT and SparseGPT models (implemented based on GPT-3 [10] structure), with different model parameter amounts and different training frameworks The Checkpoint access correctness, storage performance and read performance of ByteCheckpoint were evaluated in training tasks of different sizes. For more details on experimental configuration and correctness testing, please refer to the complete paper.
在存储性能测试中,团队比较了不同模型规模和训练框架,在训练过程中每50 或者100 步存一次Checkpoint , Bytecheckpoint 和基线( Baseline )方法给训练带来的总的阻塞时间( Checkpoint stalls )。 得益于对写入性能的深度优化,ByteCheckpoint 在各类实验场景中均取得了很高的表现,在576 卡SparseGPT 110B - Megatron-LM 训练任务中相比基线存储方法取得了66.65~74.55 倍的性能提升,在256 卡DenseGPT 10B - FSDP 训练任务中甚至能达到529.22 倍的性能提升。
在读取性能测试中,团队比较不同方法根据下游任务并行度读取 Checkpoint 的加载时间。 ByteCheckpoint 相比基线方法取得了 1.55 ~ 3.37 倍的性能提升。 团队观察到 ByteCheckpoint 相对于 Megatron-LM 基线方法的性能提升更为显着。这是因为 Megatron-LM 在读取 Checkpoint 到新的并行度配置之前,需要运行离线的脚本对分布式 Checkpoint 进行重新分片。相比之下,ByteCheckpoint 能够直接进行自动 Checkpoint 重新切分,无需运行离线脚本,高效完成读取。
Finally, regarding the future planning of ByteCheckpoint, the team hopes to start from two aspects: First, achieve the long-term goal of supporting efficient checkpointing for ultra-large-scale GPU cluster training tasks. Second, realize checkpoint management of the entire life cycle of large model training, supporting checkpoints in all scenarios, from pre-training (Pre-Training), to supervised fine-tuning (SFT), to reinforcement learning (RLHF) and evaluation (Evaluation) and other scenarios. The ByteDance Beanbao Big Model Team was established in 2023. It is committed to developing the most advanced AI big model technology in the industry and becoming a world-class research team for the development of technology and society. Make a contribution. Currently, the team is continuing to attract outstanding talents to join. Hard-core, open and full of innovative spirit are the keywords of the team atmosphere. The team is committed to creating a positive working environment, encouraging team members to continue to learn and grow, and not be afraid of Challenge and pursue excellence. Hope to work with technical talents with innovative spirit and sense of responsibility to promote the efficiency improvement of large model training and achieve more progress and results. [1] Mohan, Jayashree, Amar Phanishayee, and Vijay Chidambaram. "{CheckFreq}: Frequent,{Fine-Grained}{DNN} Checkpointing." 19th USENIX Conference on File and Storage Technologies (FAST 21). 2021.[2] Eisenman, Assaf, et al. "{Check-N-Run}: A Checkpointing system for training deep learning recommendation models." 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22). 2022.[3] Wang, Zhuang, et al. "Gemini: Fast failure recovery in distributed training with in-memory Checkpoints." Proceedings of the 29th Symposium on Operating Systems Principles. 2023.[4] Gupta, Tanmaey, et al. "Just-In-Time Checkpointing: Low Cost Error Recovery from Deep Learning Training Failures." Proceedings of the Nineteenth European Conference on Computer Systems. 2024.[5] Shoeybi, Mohammad, et al. "Megatron-lm: Training multi-billion parameter language models using model parallelism." arXiv preprint arXiv:1909.08053 (2019). [6] Zhao, Yanli, et al. "Pytorch fsdp: experiences on scaling fully sharded data parallel." arXiv preprint arXiv:2304.11277 (2023).[7] Rasley, Jeff, et al. "Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.[8] Jiang, Ziheng, et al. "{MegaScale}: Scaling large language model training to more than 10,000 {GPUs}." 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). 2024.[9] veScale: A PyTorch Native LLM Training Framework https://github.com/volcengine/veScale[10] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020) ): 1877-1901.Atas ialah kandungan terperinci Latihan Llama3 ranap setiap 3 jam? Model pundi kacang besar dan pasukan HKU meningkatkan latihan Wanka yang rangup. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn