Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Penulis pertama artikel ini ialah Cai Wenxiao, seorang pelajar siswazah di Universiti Stanford sebelum ini, beliau memperoleh ijazah sarjana muda dari Universiti Tenggara markah mata gred pertama. Minat penyelidikannya termasuk model besar multimodal dan kecerdasan yang terkandung. Kerja ini telah disiapkan semasa lawatannya ke Universiti Jiao Tong Shanghai dan latihan amalinya di Institut Penyelidikan Kecerdasan Buatan Beijing Zhiyuan Penyelianya ialah Profesor Zhao Bo, penulis artikel ini. Sebelum ini, Guru Li Feifei mencadangkan konsep Kecerdasan Ruang Sebagai tindak balas, penyelidik dari Universiti Jiao Tong Shanghai, Universiti Stanford, Universiti Zhiyuan, Universiti Peking, Universiti Oxford dan Universiti Dongda mencadangkan model spatial besar SpatialBot. Ia juga mencadangkan data latihan SpatialQA dan senarai ujian SpatialBench, cuba membenarkan model besar berbilang modal memahami kedalaman dan ruang dalam senario umum dan senario yang terkandung. 
- paper Tajuk: Spatialbot: Pemahaman kedalaman yang tepat dengan model bahasa penglihatan Link: https://arxiv.org/abs/2406.13642
- project Homepage: https: // github. com/BAAI-DCAI/SpatialBot
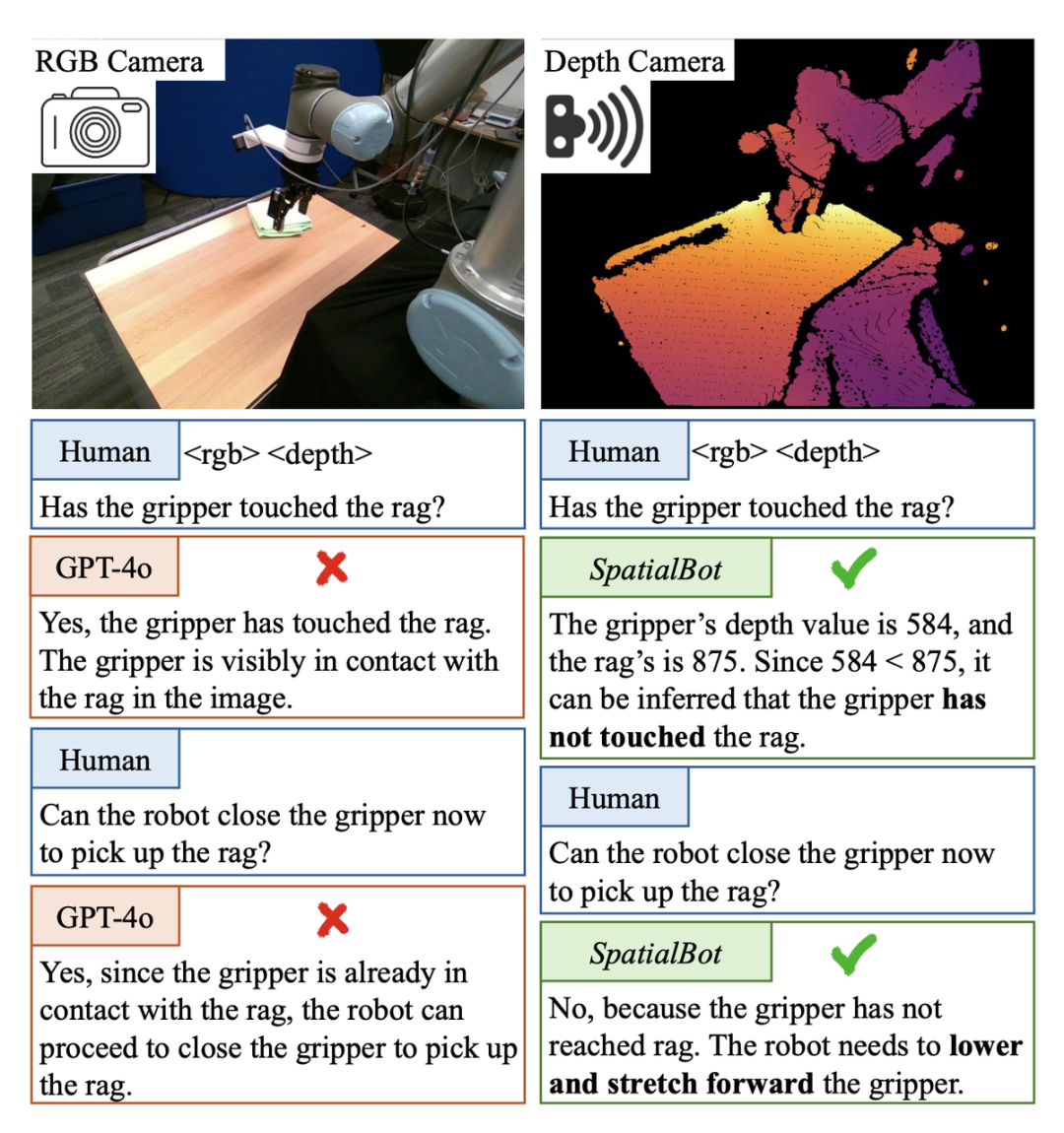
Dalam tugas pilih dan tempat kecerdasan yang terkandung, adalah perlu untuk menentukan sama ada cakar mekanikal telah menyentuh objek sasaran. Jika anda menemuinya, anda boleh menutup kuku anda dan merebutnya. Walau bagaimanapun, dalam adegan Set Data Demonstrasi Berkerly UR5 ini, walaupun GPT-4o atau manusia tidak dapat menentukan sama ada cakar mekanikal telah menyentuh objek sasaran daripada imej RGB tunggal Sebagai contoh, dengan bantuan maklumat kedalaman, peta kedalaman boleh secara langsung ditunjukkan kepada GPT-4o Jika ya, ia tidak boleh dinilai kerana ia tidak dapat memahami peta kedalaman.
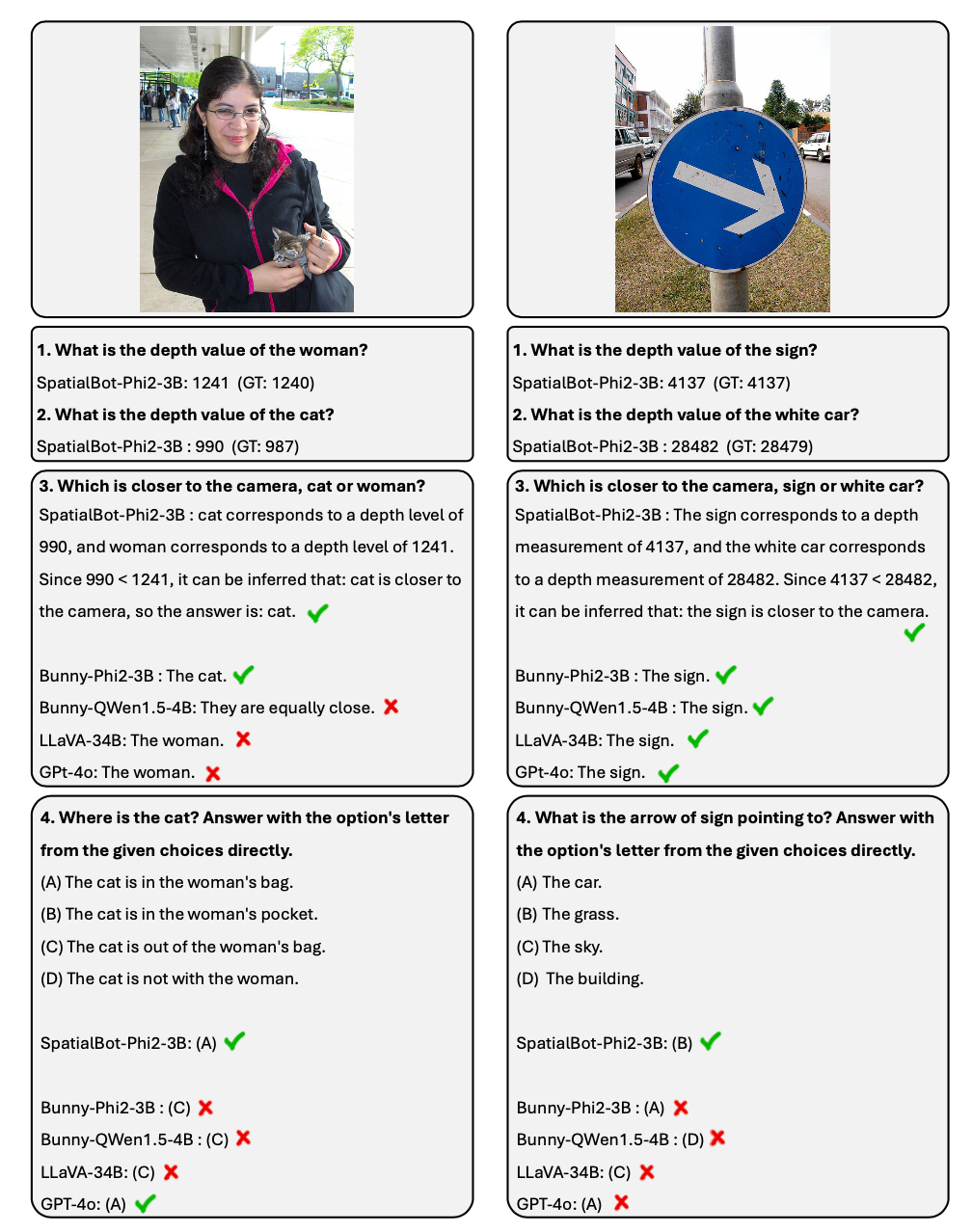
SpatialBot boleh mendapatkan nilai kedalaman cakar mekanikal dan objek sasaran dengan tepat melalui pemahaman RGB-Depth, seterusnya menjana pemahaman tentang konsep spatial.
Spatialbot demo adegan yang terkandung:
1. Sebagai laluan yang diperlukan ke arah kecerdasan yang terkandung, bagaimana untuk menjadikan model besar memahami ruang?
Apakah masalah dengan laluan teknikal semasa? Model sedia ada tidak dapat memahami secara langsung input peta kedalaman. Contohnya, pengekod imej CLIP/SigLIP dilatih pada imej RGB tanpa pernah melihat peta kedalaman.
Kebanyakan set data model besar sedia ada boleh dianalisis dan dijawab hanya menggunakan RGB. Oleh itu, jika data sedia ada hanya ditukar kepada input RGBD, model tidak akan mengindeks pengetahuan secara aktif ke dalam peta kedalaman. Tugasan yang direka khas dan QA diperlukan untuk membimbing model memahami peta kedalaman dan menggunakan maklumat kedalaman. S Tiga peringkat SpatialQA, secara beransur-ansur membimbing model untuk memahami peta kedalaman, penggunaan maklumat kedalaman
Bagaimana untuk membimbing model untuk memahami dan menggunakan maklumat mendalam, dan memahami ruang? Pengarang mencadangkan set data SpatialQA dengan tiga peringkat.
Di peringkat rendah, bimbing model untuk memahami peta kedalaman dan pandu maklumat terus dari peta kedalaman
-
Di peringkat tengah, biarkan model sejajar dengan RGB.
; - Reka bentuk kedalaman berbilang dalam tahap tinggi Untuk tugasan yang berkaitan, 50k data dianotasi, membolehkan model menggunakan maklumat kedalaman untuk menyelesaikan tugas berdasarkan pemahaman peta kedalaman. Tugas merangkumi: hubungan kedudukan spatial, saiz objek, sama ada objek bersentuhan, pemahaman adegan robot, dsb.
Contoh Dialog di Apa yang terkandung dalam spatialbot?
1 Dengan menggunakan idea dalam ejen, SpatialBot boleh mendapatkan maklumat mendalam yang tepat melalui API apabila diperlukan. Ia boleh mencapai ketepatan 99%+ pada tugasan seperti pemerolehan maklumat mendalam dan perbandingan jarak. 2 Untuk tugas pemahaman ruang, penulis mengumumkan senarai SpatialBench. Uji keupayaan pemahaman mendalam model melalui QA yang direka bentuk dengan teliti dan beranotasi. SpatialBot menunjukkan keupayaan hampir dengan GPT-4o dalam senarai. Bagaimana model memahami peta kedalaman? 1. Masukkan peta kedalaman model: Untuk mengambil kira tugas dalaman dan luaran, kaedah pengekodan peta kedalaman bersatu diperlukan. Tugas merebut dan navigasi dalaman mungkin memerlukan ketepatan tahap milimeter Pemandangan luar tidak perlu begitu tepat, tetapi mungkin memerlukan julat nilai kedalaman lebih daripada 100 meter. Pengekodan Ordinal digunakan untuk pengekodan dalam tugas penglihatan tradisional, tetapi nilai ordinal tidak boleh ditambah atau ditolak. Untuk mengekalkan semua maklumat kedalaman sebanyak mungkin, SpatialBot secara langsung menggunakan kedalaman metrik dalam milimeter, antara 1mm hingga 131m, menggunakan uint24 atau tiga saluran uint8 untuk mengekalkan nilai ini. 2. Untuk mendapatkan maklumat mendalam dengan tepat, SpatialBot akan memanggil DepthAPI dalam bentuk mata untuk mendapatkan nilai kedalaman yang tepat apabila difikirkan perlu. Jika anda ingin mendapatkan kedalaman objek, SpatialBot akan terlebih dahulu memikirkan tentang kotak sempadan objek, dan kemudian memanggil API menggunakan titik tengah kotak sempadan. 3 SpatialBot menggunakan titik tengah objek, purata kedalaman, maksimum dan empat nilai minimum untuk menggambarkan kedalaman.
dalam dalam, dalam,
dalam. 1. SpatialBot adalah berdasarkan berbilang LLM asas dari 3B hingga 8B. Dengan mempelajari pengetahuan spatial dalam SpatialQA, SpatialBot juga menunjukkan peningkatan prestasi yang ketara pada set data MLLM yang biasa digunakan (MME, MMBench, dsb.). 2 SpatialBot juga menunjukkan hasil yang menakjubkan pada tugas tertentu seperti Open X-Embodiment dan data merangkak robot yang dikumpul oleh pengarang.
B Spatialbot 일반 시나리오의 데이터 표시 방법 깊이, 거리, 거리, 위, 아래, 왼쪽, 앞, 뒤의 위치 관계, 크기 관계 등 공간적 이해에 관해 세심하게 고안된 질문이며, 두 물체가 서로 같은지 여부 등 구현에 있어서 중요한 문제를 포함합니다. 연락중.
테스트 세트 SpatialBench에서는 질문, 옵션 및 답변이 먼저 수동으로 고려됩니다. 테스트 세트 크기를 확장하기 위해 동일한 프로세스로 주석을 달기 위해 GPT도 사용됩니다.
훈련 세트 SpatialQA에는 세 가지 측면이 포함됩니다.
깊이 맵을 직접 이해하고, 모델이 깊이 맵을 보고, 깊이 분포를 분석하고, 포함될 수 있는 객체를 추측하도록 합니다.
-
공간 관계 이해 및 추론
-
로봇 장면 이해: Open X-Embodiment의 장면, 포함된 개체 및 가능한 작업과 이 기사에서 수집된 로봇 데이터를 설명하고 개체 및 경계 상자에 수동으로 레이블을 지정합니다. 로봇의. ㅋㅋ 열기 GPT를 사용하여 데이터의 이 부분에 주석을 추가할 때 GPT는 먼저 깊이 맵을 보고 깊이 맵에 포함될 수 있는 장면과 객체에 대한 이유를 설명합니다. 그런 다음 RGB 맵을 보고 올바른 설명과 추론을 필터링합니다. .
Atas ialah kandungan terperinci Selepas 'kecerdasan ruang' Li Feifei, Universiti Jiao Tong Shanghai, Universiti Zhiyuan, Universiti Peking, dll. mencadangkan model spatial besar SpatialBot. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn




 Awan titik agak mahal, dan kamera binokular memerlukan penentukuran yang kerap semasa digunakan. Sebaliknya, kamera kedalaman adalah berpatutan dan digunakan secara meluas. Dalam senario umum, walaupun tanpa peralatan perkakasan sedemikian, model anggaran kedalaman latihan berskala besar tanpa pengawasan sudah boleh memberikan maklumat kedalaman yang agak tepat. Oleh itu, penulis mencadangkan untuk menggunakan RGBD sebagai input kepada model ruang yang besar.
Awan titik agak mahal, dan kamera binokular memerlukan penentukuran yang kerap semasa digunakan. Sebaliknya, kamera kedalaman adalah berpatutan dan digunakan secara meluas. Dalam senario umum, walaupun tanpa peralatan perkakasan sedemikian, model anggaran kedalaman latihan berskala besar tanpa pengawasan sudah boleh memberikan maklumat kedalaman yang agak tepat. Oleh itu, penulis mencadangkan untuk menggunakan RGBD sebagai input kepada model ruang yang besar.