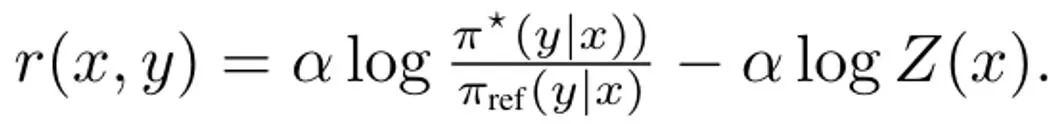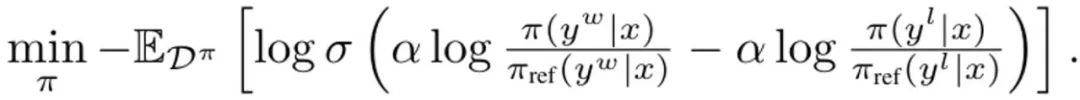Kaedah pendidikan manusia juga sesuai untuk model besar.
Apabila membesarkan anak, orang sepanjang zaman telah bercakap tentang kaedah penting: memimpin melalui teladan. Maksudnya, jadikan diri anda sebagai contoh untuk ditiru dan dipelajari oleh kanak-kanak, bukannya hanya memberitahu mereka apa yang perlu dilakukan. Apabila melatih model bahasa besar (LLM), kami juga mungkin boleh menggunakan kaedah ini - menunjukkan kepada model.
Baru-baru ini, pasukan Yang Diyi di Universiti Stanford mencadangkan rangka kerja baharu DITTO yang boleh menyelaraskan LLM dengan tetapan tertentu melalui sebilangan kecil demonstrasi (contoh tingkah laku yang diingini disediakan oleh pengguna). Contoh-contoh ini boleh diperoleh daripada log interaksi sedia ada pengguna, atau dengan mengedit terus output LLM. Ini membolehkan model memahami dan menyelaraskan pilihan pengguna dengan cekap untuk pengguna dan tugasan yang berbeza. 
- Tajuk kertas: Tunjukkan, Jangan Beritahu: Menjajarkan Model Bahasa dengan Maklum Balas yang Ditunjukkan
- Alamat kertas: https://arxiv.org/pdf/2406.00888
jadilah berdasarkan Sebilangan kecil tunjuk cara (kurang daripada 10) secara automatik mencipta set data yang mengandungi sejumlah besar perbandingan keutamaan (proses yang dipanggil perancah) dengan secara senyap-senyap menyedari bahawa pengguna lebih suka LLM berbanding output LLM asal dan lelaran terdahulu . Kemudian, demonstrasi dan output model digabungkan menjadi pasangan data untuk mendapatkan set data yang dipertingkatkan. Model bahasa kemudiannya boleh dikemas kini menggunakan algoritma penjajaran seperti DPO.
Selain itu, pasukan juga mendapati bahawa DITTO boleh dilihat sebagai algoritma pembelajaran tiruan dalam talian, di mana data yang disampel daripada LLM digunakan untuk membezakan tingkah laku pakar. Daripada perspektif ini, pasukan menunjukkan bahawa DITTO boleh mencapai prestasi pakar-unggul melalui ekstrapolasi.
Pasukan juga mengesahkan kesan DITTO melalui eksperimen. Untuk menyelaraskan LLM, kaedah sebelumnya selalunya memerlukan penggunaan beribu-ribu pasangan data perbandingan, manakala DITTO boleh mengubah suai tingkah laku model dengan hanya beberapa demonstrasi. Penyesuaian pantas dan kos rendah ini dimungkinkan terutamanya oleh cerapan teras pasukan: Data perbandingan dalam talian mudah didapati melalui demonstrasi.
Simbol dan latar belakang
Model bahasa boleh dilihat sebagai dasar π(y|x), yang menghasilkan pengedaran x segera dan hasil penyelesaian y. Matlamat RLHF adalah untuk melatih LLM untuk memaksimumkan fungsi ganjaran r (x, y) yang menilai kualiti pasangan hasil penyelesaian segera (x, y). Biasanya, perbezaan KL juga ditambah untuk mengelakkan model yang dikemas kini daripada menyimpang terlalu jauh daripada model bahasa asas (π_ref). Secara keseluruhan, matlamat pengoptimuman kaedah RLHF ialah: Ini adalah untuk memaksimumkan ganjaran yang dijangkakan pada pengedaran segera p, yang dipengaruhi oleh kekangan KL yang dikawal oleh α. Lazimnya, matlamat pengoptimuman menggunakan set data perbandingan dalam bentuk {(x, y^w, y^l )}, dengan hasil penyelesaian "menang" y^w adalah lebih baik daripada hasil penyelesaian "kalah" y ^l, direkodkan sebagai y^w ⪰ y^l. Selain itu, di sini kami menandakan set data demonstrasi pakar kecil sebagai D_E, dan menganggap bahawa demonstrasi ini dihasilkan oleh dasar pakar π_E, yang boleh memaksimumkan ganjaran ramalan. DITTO boleh terus menggunakan output model bahasa dan demonstrasi pakar untuk menjana data perbandingan. Iaitu, tidak seperti paradigma generatif untuk data sintetik, DITTO tidak memerlukan model yang sudah berfungsi dengan baik pada tugasan tertentu. Wawasan utama DITTO ialah model bahasa itu sendiri, ditambah dengan demonstrasi pakar, boleh membawa kepada set data perbandingan untuk penjajaran, yang menghapuskan keperluan pasangan untuk mengumpul jumlah keutamaan yang besar . Ini menghasilkan sasaran seperti kontras di mana demonstrasi pakar adalah contoh positif. Jana perbandingan. Katakan kita mencuba hasil penyiapan y^E ∼ π_E (・|x) daripada dasar pakar. Maka boleh dianggap bahawa ganjaran yang sepadan dengan sampel yang diambil daripada dasar lain π adalah lebih rendah daripada atau sama dengan ganjaran sampel yang diambil daripada π_E. Berdasarkan pemerhatian ini, pasukan membina data perbandingan (x, y^E, y^π ), di mana y^E ⪰ y^π. Walaupun data perbandingan tersebut diperoleh daripada strategi dan bukannya sampel individu, kajian terdahulu telah menunjukkan keberkesanan pendekatan ini. Pendekatan semula jadi untuk DITTO adalah menggunakan set data ini dan algoritma RLHF yang tersedia untuk mengoptimumkan (1). Melakukannya meningkatkan kebarangkalian respons pakar sambil mengurangkan kebarangkalian sampel model semasa, tidak seperti kaedah penalaan halus standard yang hanya melakukan yang pertama. Kuncinya ialah dengan menggunakan sampel daripada π, set data keutamaan yang tidak terhad boleh dibina dengan sebilangan kecil demonstrasi. Walau bagaimanapun, pasukan mendapati bahawa ia boleh dilakukan dengan lebih baik dengan mengambil kira aspek temporal proses pembelajaran. Dari perbandingan kepada ranking. Menggunakan hanya data perbandingan daripada pakar dan satu dasar π mungkin tidak mencukupi untuk memperoleh prestasi yang baik. Melakukannya hanya akan mengurangkan kemungkinan π tertentu, yang membawa kepada masalah overfitting - yang juga melanda SFT dengan sedikit data. Pasukan itu mencadangkan bahawa data yang dijana oleh semua dasar yang dipelajari dari semasa ke semasa semasa RLHF juga boleh dipertimbangkan, sama seperti memainkan semula dalam pembelajaran pengukuhan. Biar strategi awal dalam pusingan pertama lelaran ialah π_0. Set data D_0 diperoleh dengan mensampel strategi ini. Set data perbandingan untuk RLHF kemudiannya boleh dijana berdasarkan ini, yang boleh dilambangkan sebagai D_E ⪰ D_0. Menggunakan data perbandingan terbitan ini, π_0 boleh dikemas kini untuk mendapatkan π_1. Mengikut definisi, juga memegang. Selepas itu, teruskan menggunakan π_1 untuk menjana data perbandingan, dan D_E ⪰ D_1. Teruskan proses ini, terus menjana data perbandingan yang semakin pelbagai menggunakan semua strategi sebelumnya. Pasukan itu memanggil perbandingan ini "perbandingan ulang tayang." Walaupun kaedah ini masuk akal secara teori, overfitting mungkin berlaku jika D_E kecil. Walau bagaimanapun, perbandingan antara dasar juga boleh dipertimbangkan semasa latihan jika diandaikan bahawa dasar itu akan bertambah baik selepas setiap lelaran. Tidak seperti perbandingan dengan pakar, kami tidak dapat menjamin bahawa strategi akan menjadi lebih baik selepas setiap lelaran, tetapi pasukan mendapati bahawa model keseluruhan masih bertambah baik selepas setiap lelaran Ini mungkin kerana kedua-dua pemodelan ganjaran dan (1) Ia cembung. Dengan cara ini, data perbandingan boleh dijadikan sampel mengikut kedudukan berikut:
Dengan menambah data perbandingan "antara model" dan "main semula", kesan yang diperoleh ialah kemungkinan sampel awal (seperti sampel dalam D_1) akan lebih tinggi daripada yang Kemudian (seperti dalam D_t) tekan lebih rendah, sekali gus melicinkan gambar ganjaran tersirat. Dalam pelaksanaan praktikal, pendekatan pasukan bukan sahaja menggunakan data perbandingan dengan pakar, tetapi juga mengagregatkan beberapa data perbandingan antara model ini. Algoritma praktikal. Dalam amalan, algoritma DITTO ialah proses berulang yang terdiri daripada tiga komponen mudah, seperti yang ditunjukkan dalam Algoritma 1.
Mula-mula, jalankan penalaan halus diselia pada set demo pakar, melakukan langkah kecerunan dalam jumlah terhad. Biarkan ini menjadi dasar awal π_0 Langkah kedua, data perbandingan sampel: semasa latihan, untuk setiap demonstrasi N dalam D_E, set data baharu D_t dibina dengan pensampelan hasil penyiapan M daripada π_t, Mereka kemudiannya ditambah pada kedudukan mengikut kedudukan. strategi (2). Apabila mensampel data perbandingan daripada persamaan (2), setiap kumpulan B terdiri daripada 70% data perbandingan "dalam talian" D_E ⪰ D_t dan 20% data perbandingan "main semula" D_E ⪰ D_{i
di mana σ adalah fungsi logistik dari model pilihan Bradley-Terry. Semasa setiap kemas kini, model rujukan daripada strategi SFT tidak dikemas kini untuk mengelakkan penyelewengan terlalu jauh daripada permulaan. Menerbitkan DITTO ke dalam Pembelajaran Tiruan Dalam Talian DITTO boleh diperoleh daripada perspektif pembelajaran tiruan dalam talian, di mana gabungan demonstrasi pakar dan data dalam talian digunakan untuk mempelajari fungsi ganjaran dan dasar secara serentak. Secara khusus, pemain strategi memaksimumkan ganjaran yang dijangkakan? (π, r), manakala pemain ganjaran meminimumkan kerugian min_r L (D^π, r) pada set data dalam talian D^π Secara lebih khusus, pendekatan pasukan adalah untuk gunakan objektif dasar dalam (1) dan kerugian model ganjaran standard untuk menimbulkan masalah pengoptimuman:
Menerbitkan DITTO, langkah pertama dalam memudahkan (3) ialah menyelesaikan isu maksimum dasar dalamannya. Nasib baik, pasukan mendapati berdasarkan penyelidikan terdahulu bahawa objektif dasar ?_KL mempunyai penyelesaian bentuk tertutup dalam bentuk di mana Z (x) ialah fungsi partition bagi taburan ternormal. Terutama, ini mewujudkan hubungan bijektif antara dasar dan fungsi ganjaran, yang boleh digunakan untuk menghapuskan pengoptimuman dalaman. Dengan menyusun semula penyelesaian ini, fungsi ganjaran boleh ditulis sebagai: Selain itu, kajian terdahulu telah menunjukkan bahawa penyusunan semula ini boleh mewakili fungsi ganjaran sewenang-wenangnya. Oleh itu, dengan menggantikan persamaan (3), pembolehubah r boleh ditukar kepada π, dengan itu memperoleh objektif DITTO: Sila ambil perhatian bahawa sama dengan DPO, fungsi ganjaran dianggarkan secara tersirat di sini. Perbezaan daripada DPO ialah DITTO bergantung pada set data keutamaan dalam talian D^π. Mengapa DITTO lebih baik daripada hanya menggunakan SFT? Satu sebab mengapa DITTO berprestasi lebih baik ialah ia menggunakan lebih banyak data daripada SFT dengan menjana data perbandingan. Sebab lain ialah dalam beberapa kes kaedah pembelajaran tiruan dalam talian mengatasi penyampai, manakala SFT hanya boleh meniru demonstrasi. Pasukan juga menjalankan kajian empirikal untuk membuktikan keberkesanan DITTO. Sila rujuk kertas asal untuk tetapan khusus percubaan Kami hanya menumpukan pada keputusan percubaan di sini. Hasil penyelidikan berdasarkan penanda aras statik Penilaian penanda aras statik menggunakan GPT-4, dan keputusan ditunjukkan dalam Jadual 1.
En moyenne, DITTO surpasse toutes les autres méthodes : 71,67 % de taux de victoire moyen sur CMCC, 82,50 % de taux de victoire moyen sur CCAT50 ; 77,09 % de taux de victoire moyen global. Sur CCAT50, pour tous les auteurs, DITTO n'a pas remporté la victoire globale dans un seul d'entre eux. Sur CMCC, pour tous les auteurs, DITTO surpasse la moitié des benchmarks dans tous les domaines, suivi de quelques tirs incitant à gagner de 30 %. Bien que SFT ait bien performé, DITTO a amélioré son taux de victoire moyen de 11,7 % par rapport à lui. Étude utilisateur : tester la capacité de généralisation à des tâches naturellesDans l'ensemble, les résultats de l'étude utilisateur sont cohérents avec les résultats des benchmarks statiques. DITTO surpasse les méthodes contrastées en termes de préférence pour les démos alignées, comme le montre le tableau 2 : où DITTO (taux de victoire de 72,1 %) > SFT (60,1 %) > quelques plans (48,1 %) > auto-invite (44,2 %) > tir nul (25,0 %).
Quand DITTO est-il utile ? Avant d'utiliser DITTO, les utilisateurs doivent prendre en compte certaines conditions préalables, du nombre de démos dont ils disposent au nombre d'exemples négatifs qui doivent être échantillonnés à partir du modèle de langage. L'équipe a exploré l'impact de ces décisions et s'est concentrée sur le CMCC car il couvre plus de missions que le CCAT. De plus, ils ont analysé l’efficacité de l’échantillon de démonstration par rapport aux commentaires appariés. Perturbation algorithmique L'équipe a mené des études d'ablation sur les composants de DITTO. Comme le montre la figure 2 (à gauche), augmenter le nombre d'itérations de DITTO peut généralement améliorer les performances.
On constate que lorsque le nombre d'itérations passe de 1 à 4, le taux de victoire évalué par GPT-4 augmentera de 31,5%. Cette amélioration n'est pas monotone : à l'itération 2, les performances diminuent légèrement (-3,4%). En effet, les premières itérations peuvent aboutir à des échantillons plus bruyants, réduisant ainsi les performances. D'un autre côté, comme le montre la figure 2 (au milieu), l'augmentation du nombre d'exemples négatifs améliore de manière monotone les performances de DITTO. De plus, à mesure que davantage d’exemples négatifs sont échantillonnés, la variance des performances de DITTO diminue.
De plus, comme le montre le tableau 3, des études d'ablation sur DITTO ont révélé que la suppression de l'un de ses composants entraînait une dégradation des performances. Par exemple, si vous abandonnez l'échantillonnage itératif en ligne, par rapport à l'utilisation de DITTO, le taux de réussite passera de 70,1 % à 57,3 %. Et si π_ref est continuellement mis à jour pendant le processus en ligne, cela entraînera une baisse significative des performances : de 70,1 % à 45,8 %. L'équipe suppose que la raison en est que la mise à jour de π_ref peut conduire à un surapprentissage. Enfin, on peut également voir dans le tableau 3 l’importance des données de replay et de comparaison inter-stratégies. Efficacité des échantillons L'un des principaux avantages de DITTO est l'efficacité de ses échantillons. L'équipe a évalué cela et les résultats sont présentés dans la figure 2 (à droite encore, les taux de victoire normalisés sont rapportés ici) ; Tout d’abord, vous pouvez voir que le taux de victoire de DITTO augmentera rapidement au début. Comme le nombre de démos passe de 1 à 3, les performances normalisées s'améliorent significativement à chaque augmentation (0% → 5% → 11,9%). Cependant, lorsque le nombre de démos augmente encore, l'augmentation des revenus diminue (11,9% → 15,39% en passant de 4 à 7), ce qui montre qu'à mesure que le nombre de démos augmente, les performances de DITTO seront saturées. De plus, l'équipe spécule que non seulement le nombre de démonstrations affectera les performances de DITTO, mais aussi la qualité des démonstrations, mais cela est laissé pour des recherches futures. Comment la préférence par paire se compare-t-elle à la démo ? Une hypothèse fondamentale de DITTO est que l'efficacité des échantillons vient de la démonstration. En théorie, si l’utilisateur a en tête un ensemble parfait de démonstrations, un effet similaire peut être obtenu en annotant de nombreuses paires de données de préférence. L'équipe a mené une expérience approfondie, en utilisant les sorties échantillonnées de Compliance Mistral 7B, et a disposé de 500 paires de données de préférence également annotées par l'un des auteurs qui a fourni une démo de l'étude utilisateur. En résumé, ils ont construit un ensemble de données de préférences par paires D_pref = {(x, y^i , y^j )}, où y^i ≻ y^j. Ils ont ensuite calculé le taux de réussite pour 20 paires de résultats échantillonnés à partir de deux modèles : l'un formé sur 4 démos à l'aide de DITTO et l'autre formé sur {0...500} paires de données de préférence en utilisant uniquement DPO.
Lors de l'échantillonnage des données de préférence par paire uniquement à partir de π_ref, on peut observer que les paires de données générées se situent en dehors de la distribution démontrée - les préférences par paire n'impliquent pas le comportement démontré par l'utilisateur (résultats pour la politique de base dans la figure 3, couleur bleue). Même lorsqu'ils ont affiné π_ref à l'aide de démonstrations d'utilisateurs, il fallait encore plus de 500 paires de données de préférence pour correspondre aux performances de DITTO (résultats de la politique de démonstration affinée dans la figure 3, orange). Atas ialah kandungan terperinci Ia hanya memerlukan beberapa demonstrasi untuk menyelaraskan model besar DITTO yang dicadangkan oleh pasukan Yang Diyi begitu cekap.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn




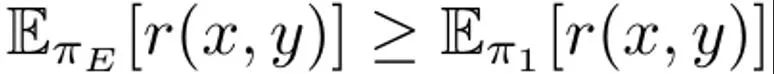 juga memegang. Selepas itu, teruskan menggunakan π_1 untuk menjana data perbandingan, dan D_E ⪰ D_1. Teruskan proses ini, terus menjana data perbandingan yang semakin pelbagai menggunakan semua strategi sebelumnya. Pasukan itu memanggil perbandingan ini "perbandingan ulang tayang."
juga memegang. Selepas itu, teruskan menggunakan π_1 untuk menjana data perbandingan, dan D_E ⪰ D_1. Teruskan proses ini, terus menjana data perbandingan yang semakin pelbagai menggunakan semua strategi sebelumnya. Pasukan itu memanggil perbandingan ini "perbandingan ulang tayang."