
Rumah >Peranti teknologi >AI >TPAMI 2024 |. ProCo: Pembelajaran kontrastif ekor panjang bagi pasangan kontras tak terhingga
TPAMI 2024 |. ProCo: Pembelajaran kontrastif ekor panjang bagi pasangan kontras tak terhingga

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-07-25 20:52:33529semak imbas

Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Du Chaoqun, pengarang pertama kertas ini, ialah pelajar PhD langsung 2020 di Jabatan Automasi, Universiti Tsinghua. Tutornya ialah Profesor Madya Huang Gao. Beliau sebelum ini menerima ijazah Sarjana Muda Sains daripada Jabatan Fizik Universiti Tsinghua. Minat penyelidikannya termasuk generalisasi model dan penyelidikan keteguhan mengenai pengagihan data yang berbeza, seperti pembelajaran ekor panjang, pembelajaran separa penyeliaan, pembelajaran pemindahan, dsb. Menerbitkan banyak kertas kerja dalam jurnal dan persidangan antarabangsa kelas pertama seperti TPAMI dan ICML. Laman Utama Peribadi: https: //andy-du20.github.io
Artikel ini memperkenalkan kertas mengenai pengiktirafan visual panjang dari Tsinghua University: Pembelajaran Kontrasif Probabilistik untuk Pengiktirafan Visual Panjang. TPAMI 2024 diterima, kod tersebut telah menjadi sumber terbuka. Penyelidikan ini tertumpu terutamanya pada aplikasi pembelajaran kontrastif dalam tugasan pengecaman visual ekor panjang. Ia mencadangkan kaedah pembelajaran kontrastif ekor panjang baharu ProCo Dengan memperbaiki kehilangan kontrastif, ia mencapai pembelajaran kontrastif bilangan pasangan kontras yang tidak terhad. menyelesaikan masalah dengan berkesan Pembelajaran kontrastif yang diselia[1] mempunyai pergantungan yang wujud pada saiz kelompok (bank memori). Sebagai tambahan kepada tugas pengelasan visual ekor panjang, kaedah ini juga telah diuji pada pembelajaran separa penyeliaan ekor panjang, pengesanan objek ekor panjang dan set data seimbang, yang mencapai peningkatan prestasi yang ketara.
Pautan kertas: https://arxiv.org/pdf/2403.06726

- Pautan projek: https://github.com/LeapLabTHU/ProCo
Perbandingan Kejayaan pembelajaran dalam pembelajaran penyeliaan kendiri menunjukkan keberkesanannya dalam mempelajari perwakilan ciri visual. Faktor teras yang mempengaruhi prestasi pembelajaran kontrastif ialah bilangan pasangan kontras, yang membolehkan model belajar daripada lebih banyak sampel negatif, yang ditunjukkan dalam dua kaedah yang paling mewakili SimCLR [2] dan MoCo [3] masing-masing saiz bank memori. Walau bagaimanapun, dalam tugasan pengecaman visual long-tail, disebabkan oleh
ketidakseimbangan kategori, keuntungan yang dibawa dengan menambah bilangan pasangan kontrastif akan menghasilkan kesan pengurangan marginal yang serius Ini kerana kebanyakan pasangan kontrastif terdiri daripada kategori kepala . Terdiri daripada sampel, sukar untuk menutup kategori ekor. Sebagai contoh, dalam set data Imagenet long-tail, jika saiz kelompok (bank memori) ditetapkan kepada 4096 dan 8192 biasa, maka terdapat purata 212 dan 89
kategori dalam setiap kelompok (memori bank) masing-masing Saiz sampel adalah kurang daripada satu.Oleh itu, idea teras kaedah ProCo ialah: pada set data ekor panjang, dengan memodelkan pengedaran setiap jenis data, menganggar parameter dan pensampelan daripadanya untuk membina pasangan yang berbeza, memastikan semua kategori boleh bertudung. Tambahan pula, apabila bilangan sampel cenderung kepada infiniti, penyelesaian analitik yang dijangkakan bagi kehilangan kontrastif boleh diperolehi secara ketat secara teori, supaya ia boleh digunakan secara langsung sebagai sasaran pengoptimuman untuk mengelakkan pensampelan pasangan kontrastif yang tidak cekap dan mencapai bilangan kontrastif yang tidak terhingga. berpasangan. Walau bagaimanapun, terdapat beberapa kesukaran utama dalam merealisasikan idea di atas:
Bagaimana untuk memodelkan pengedaran setiap jenis data.
Cara menganggarkan parameter taburan dengan cekap, terutamanya untuk kategori ekor dengan bilangan sampel yang kecil.
Bagaimana untuk memastikan penyelesaian analitikal yang dijangkakan bagi kehilangan kontrastif wujud dan boleh dikira.
Malah, masalah di atas boleh diselesaikan dengan model kebarangkalian bersatu, iaitu taburan kebarangkalian yang mudah dan berkesan dipilih untuk memodelkan taburan ciri, supaya anggaran kemungkinan maksimum boleh digunakan untuk menganggarkan parameter dengan cekap. pengagihan dan mengira Jangkakan penyelesaian analitikal untuk kerugian kontrastif.
Memandangkan ciri pembelajaran kontras diedarkan pada hipersfera unit, penyelesaian yang boleh dilaksanakan ialah memilih taburan von Mises-Fisher (vMF) pada sfera sebagai taburan ciri (taburan ini serupa dengan taburan normal pada sfera) . Anggaran kebarangkalian maksimum bagi parameter taburan vMF mempunyai penyelesaian analitik anggaran dan hanya bergantung pada statistik momen urutan pertama bagi ciri Oleh itu, parameter taburan boleh dianggarkan dengan cekap dan jangkaan kerugian kontrastif boleh diperolehi dengan ketat, dengan itu. mencapai perbandingan bilangan pasangan kontrastif yang tidak terhad.
図 1 ProCo アルゴリズムは、さまざまなバッチの特性に基づいてサンプルの分布を推定します。無制限の数のサンプルをサンプリングすることで、予測されるコントラスト損失の分析解を得ることができ、教師ありコントラスト学習の固有の依存性を効果的に排除できます。バッチサイズ(メモリバンク)のサイズ。
手法の詳細
以下では、分布仮定、パラメータ推定、最適化目標、理論分析の 4 つの側面から ProCo 手法を詳しく紹介します。
分布仮定
前に述べたように、対照学習の特徴は単位超球に制限されます。したがって、これらの特徴に従う分布はフォン ミーゼス フィッシャー (vMF) 分布であり、その確率密度関数は次のように仮定できます。 
ここで、z は p 次元特徴の単位ベクトル、I は修正された第 1 種ベッセル関数、
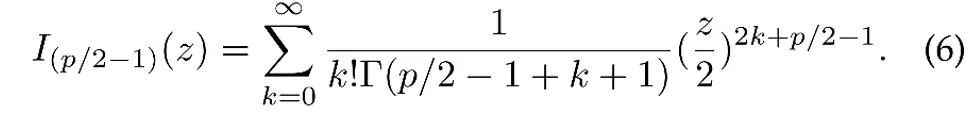
パラメータ推定
上記の分布仮定に基づくと、データ特徴の全体的な分布は混合 vMF 分布であり、各カテゴリが vMF 分布に対応します。
は、トレーニング セット内のカテゴリ y の頻度に対応する、各カテゴリの事前確率を表します。特徴量分布の平均ベクトル  と集中パラメータ
と集中パラメータ  は最尤推定により推定されます。
は最尤推定により推定されます。 
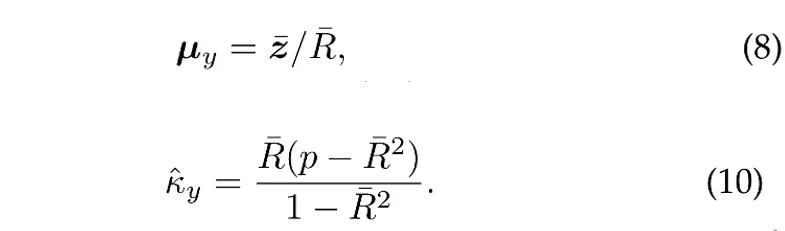
はサンプルです。平均値、 はサンプル平均値の係数の長さです。さらに、過去のサンプルを利用するために、ProCo はテール カテゴリのパラメータを効果的に推定できるオンライン推定手法を採用しています。
はサンプル平均値の係数の長さです。さらに、過去のサンプルを利用するために、ProCo はテール カテゴリのパラメータを効果的に推定できるオンライン推定手法を採用しています。 
最適化の目的
推定されたパラメーターに基づいて、混合 vMF 分布からサンプリングして対照的なペアを構築するのが簡単なアプローチですが、各トレーニング反復で vMF 分布から大量のサンプルをサンプリングするのは非効率です。したがって、本研究では理論的にサンプル数を無限大に拡張し、最適化目標として期待されるコントラスト損失関数の解析解を直接厳密に導出する。
ProCo 手法の有効性を理論的に検証するために、研究者らはその一般化誤差限界と過剰リスク限界を分析しました。分析を簡略化するために、ここでは 2 つのカテゴリ、つまり y∈{-1,+1} のみがあると仮定します。分析は、一般化誤差限界が主にトレーニング サンプルの数とデータの分散によって制御されることを示しています。この発見は、関連研究 [6][7] の理論分析と一致しており、ProCo 損失が追加の要因を導入せず、一般化誤差限界を増加させないことを保証しており、これによりこの方法の有効性が理論的に保証されています。 
さらに、この方法は、特徴分布とパラメーター推定に関する特定の仮定に依存しています。モデルのパフォーマンスに対するこれらのパラメーターの影響を評価するために、研究者らは、ProCo 損失の超過リスク限界も分析しました。これは、推定パラメーターを使用した予想リスクと、実際の分布にある予想リスクとの偏差を測定します。パラメーター。

これは、ProCo 損失の過剰リスクが主にパラメーター推定誤差の一次項によって制御されていることを示しています。
実験結果
中核となるモチベーションの検証として、研究者たちはまず、異なるバッチサイズで異なる対照学習法のパフォーマンスを比較しました。ベースラインには、バランス対照学習 [5] (BCL) が含まれています。これは、ロングテール認識タスクでも SCL に基づいて改良された方法です。具体的な実験設定は、教師あり対比学習 (SCL) の 2 段階のトレーニング戦略に従います。つまり、まず表現学習トレーニングにコントラスト損失のみを使用し、次にフリーズ バックボーンを使用したテスト用に線形分類器をトレーニングします。
下の図は、CIFAR100-LT (IF100) データセットでの実験結果を示しています。BCL と SupCon のパフォーマンスはバッチ サイズによって明らかに制限されますが、ProCo はこの機能を導入することでバッチ サイズに対する SupCon の影響を効果的に排除します。各カテゴリの依存関係を分散することで、異なるバッチ サイズでも最高のパフォーマンスを実現します。
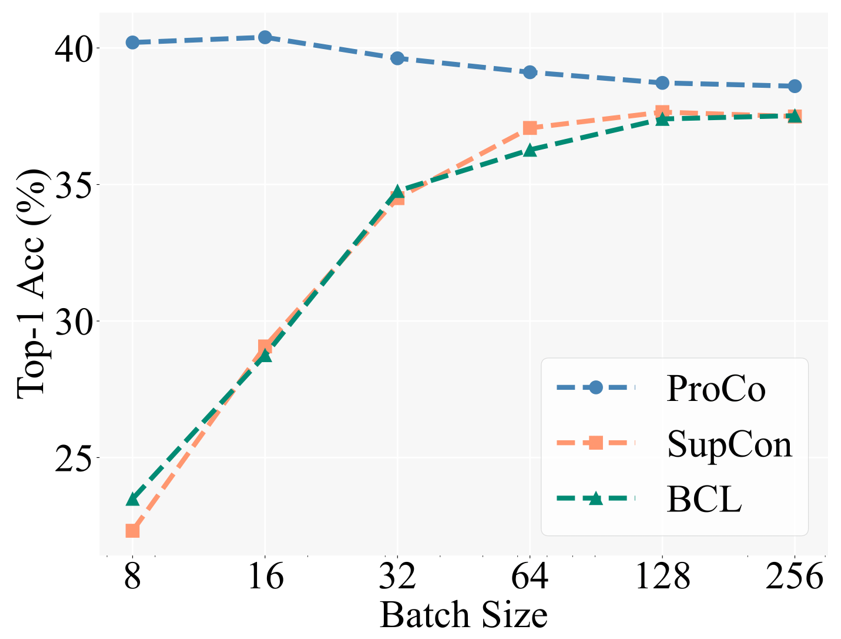
さらに、研究者らは、ロングテール認識タスク、ロングテール半教師あり学習、ロングテール物体検出、バランスの取れたデータセットに関する実験も実施しました。ここでは主に大規模ロングテールデータセットImagenet-LTとiNaturalist2018の実験結果を示します。まず、90 エポックのトレーニング スケジュールの下で、対照学習を改善する同様の方法と比較して、ProCo は 2 つのデータ セットと 2 つのバックボーンで少なくとも 1% のパフォーマンス向上を実現しました。

さらに、次の結果は、ProCo が 400 エポック スケジュールの下で、iNaturalist2018 データセットで SOTA パフォーマンスを達成し、他の非 A の組み合わせと競合できることも検証しました。蒸留 (NCL) やその他の方法を含む、対照的な学習方法の説明。 「視覚表現の対比学習のための単純なフレームワーク」機械学習に関する国際会議、2020 年

-
S . Sra、「フォン ミーゼス フィッシャー分布のパラメーター近似に関する短いメモ: および is (x) の高速実装」、計算統計学、2012 年。
J. Zhu ら、「ロングテール視覚認識のためのバランスの取れた対照学習」、CVPR、2022 年。 - W. Jitkrittum ら、「ELM: ロングテール学習のための埋め込みとロジット マージン」 arXiv プレプリント、2022。
- A. K. Menon、他、ICLR、2021。
Atas ialah kandungan terperinci TPAMI 2024 |. ProCo: Pembelajaran kontrastif ekor panjang bagi pasangan kontras tak terhingga. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI