
Rumah >Peranti teknologi >AI >Bagaimana untuk mencipta model sumber terbuka yang boleh mengalahkan GPT-4o? Mengenai Llama 3.1 405B, Meta ditulis dalam kertas ini
Bagaimana untuk mencipta model sumber terbuka yang boleh mengalahkan GPT-4o? Mengenai Llama 3.1 405B, Meta ditulis dalam kertas ini

- PHPzasal
- 2024-07-24 18:42:031064semak imbas
Selepas mengalami "kebocoran tidak sengaja" dua hari lebih awal, akhirnya Llama 3.1 dikeluarkan secara rasmi malam tadi. Llama 3.1 memanjangkan panjang konteks kepada 128K dan tersedia dalam versi 8B, 70B dan 405B, sekali lagi secara bersendirian meningkatkan bar untuk persaingan pada trek model besar. Bagi komuniti AI, kepentingan paling penting Llama 3.1 405B ialah ia menyegarkan had atas keupayaan model asas sumber terbuka, pegawai Meta berkata dalam satu siri tugasan, prestasinya adalah setanding dengan yang terbaik tertutup model sumber. Jadual di bawah menunjukkan prestasi model Siri Llama 3 semasa pada penanda aras utama. Ia boleh dilihat bahawa prestasi model 405B sangat hampir dengan GPT-4o.
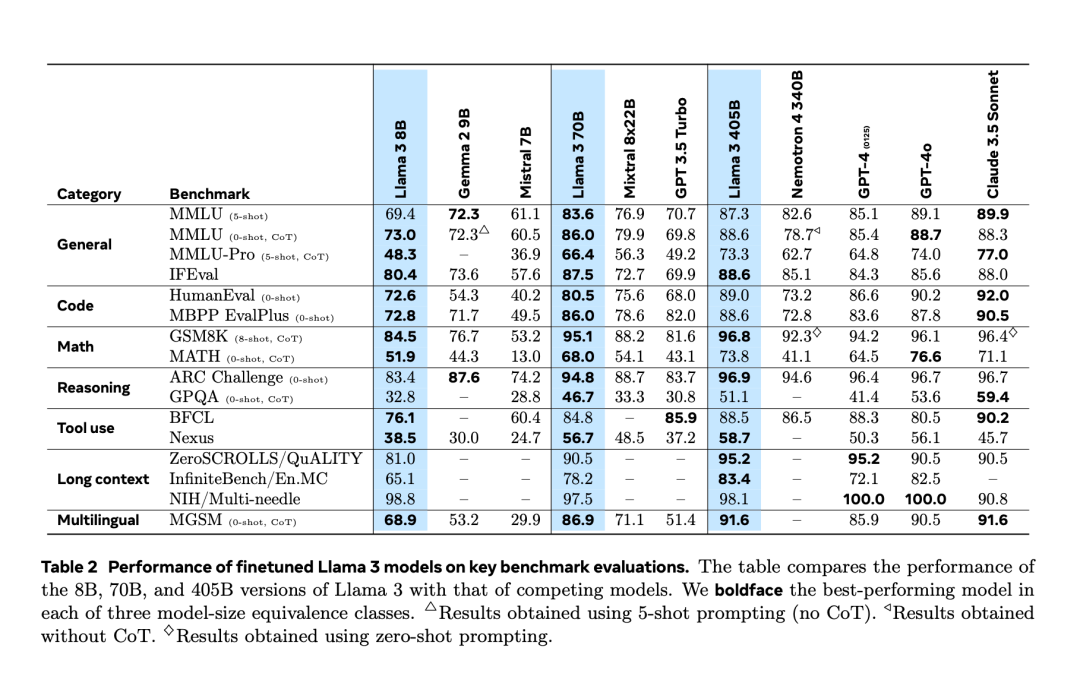

Meta meningkatkan prapemprosesan model Llama dan saluran paip Curation bagi data pra-latihan, serta jaminan kualiti dan kaedah penapisan data selepas latihan.
Meta percaya bahawa terdapat tiga tuil utama untuk pembangunan model asas berkualiti tinggi: pengurusan data, skala dan kerumitan.- Data: Meta telah menambah baik kuantiti dan kualiti data pra-latihan dan pasca-latihan berbanding versi Llama terdahulu. Llama 3 telah dilatih terlebih dahulu pada korpus kira-kira 15 trilion token berbilang bahasa, manakala Llama 2 hanya menggunakan 1.8 trilion token.
- Model terlatih jauh lebih besar daripada model Llama sebelumnya: model bahasa perdana menggunakan 3.8 x 10^25 operasi titik terapung (FLOP) untuk pra-latihan, melebihi versi terbesar Llama 2 sebanyak hampir 50 kali.
- Pengurusan Kerumitan: Menurut undang-undang Penskalaan, model utama Meta telah mengira saiz optimum, tetapi masa latihan model yang lebih kecil telah jauh melebihi masa optimum yang dikira. Keputusan menunjukkan bahawa model yang lebih kecil ini mengatasi model pengiraan optimum untuk belanjawan inferens yang sama. Dalam fasa pasca latihan, Meta menggunakan model perdana 405B untuk meningkatkan lagi kualiti model yang lebih kecil seperti 70B dan 8B.
- Untuk menyokong inferens pengeluaran berskala besar bagi model 405B, Meta mengkuantifikasikan 16-bit (BF16) kepada 8-bit (FP8), mengurangkan keperluan pengiraan dan membolehkan model berjalan pada satu nod pelayan.
- Pra-latihan 405B pada token 15.6T (3.8x10^25 FLOP) merupakan cabaran utama, Meta mengoptimumkan keseluruhan susunan latihan dan menggunakan lebih 16K H100 GPU.
- 1 Semasa latihan, Meta menambah baik model Sembang melalui berbilang pusingan penjajaran, termasuk penalaan halus (SFT), pensampelan penolakan dan pengoptimuman pilihan langsung. Kebanyakan sampel SFT dihasilkan daripada data sintetik.
- 研究者在設計中做出了一些選擇,以最大化模型開發過程的可擴展性。例如,選擇標準的密集 Transformer 模型架構,只進行了少量調整,而不是採用專家混合模型,以最大限度地提高訓練的穩定性。同樣,採用相對簡單的後訓練程序,基於監督微調(SFT)、拒絕採樣(RS)和直接偏好優化(DPO),而不是更複雜的強化學習演算法, 因為後者往往穩定性較差且更難擴展。
- 作為 Llama 3 開發過程的一部分,Meta 團隊也開發了模型的多模態擴展,使其具備影像辨識、視訊辨識和語音理解的能力。這些模型仍在積極開發中,尚未準備好發布,但論文展示了對這些多模態模型進行初步實驗的結果。
- Meta 更新了許可證,允許開發者使用 Llama 模型的輸出結果來增強其他模型。
- 在這篇論文的最後,我們也看到了長長的貢獻者名單:fenye1. 這一系列因素,最終造就了今天的 Llama 3 系列。
- 當然,對於普通開發者來說,如何利用 405B 規模的 Llama 模型是一項挑戰,需要大量的計算資源和專業知識。
- 發布之後,Llama 3.1 的生態系統已準備就緒,超過25 個合作夥伴提供了可與最新模型搭配使用的服務,包括亞馬遜雲端科技、NVIDIA、Databricks、Groq、Dell、Azure、Google Cloud 和Snowflake 等。
更多技術細節,可參考原論文。
Atas ialah kandungan terperinci Bagaimana untuk mencipta model sumber terbuka yang boleh mengalahkan GPT-4o? Mengenai Llama 3.1 405B, Meta ditulis dalam kertas ini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI