Pada masa ini, model bahasa berskala besar autoregresif menggunakan paradigma ramalan token seterusnya telah menjadi popular di seluruh dunia Pada masa yang sama, sejumlah besar imej dan video sintetik di Internet telah menunjukkan kepada kami kuasa penyebaran model.
Baru-baru ini, pasukan penyelidik di MIT CSAIL (salah seorang daripadanya ialah Chen Boyuan, pelajar PhD di MIT) berjaya menyepadukan keupayaan berkuasa model penyebaran jujukan penuh dan model token seterusnya, dan mencadangkan latihan dan pensampelan paradigma: Diffusion Forcing(DF).
Tajuk kertas: Diffusion Forcing: Next-token Prediction Meet Full-Sequence Diffusion
Alamat kertas: https://arxiv.org/pdf/2407.01392.01392 /arxiv.org/pdf/2407.01392 /boyuan.space/diffusion-forcing
Alamat kod: https://github.com/buoyancy99/diffusion-forcing
Seperti yang ditunjukkan di bawah, resapan dengan jelas segi ketekalan dan kestabilan Dua kaedah ialah resapan jujukan dan paksaan guru.
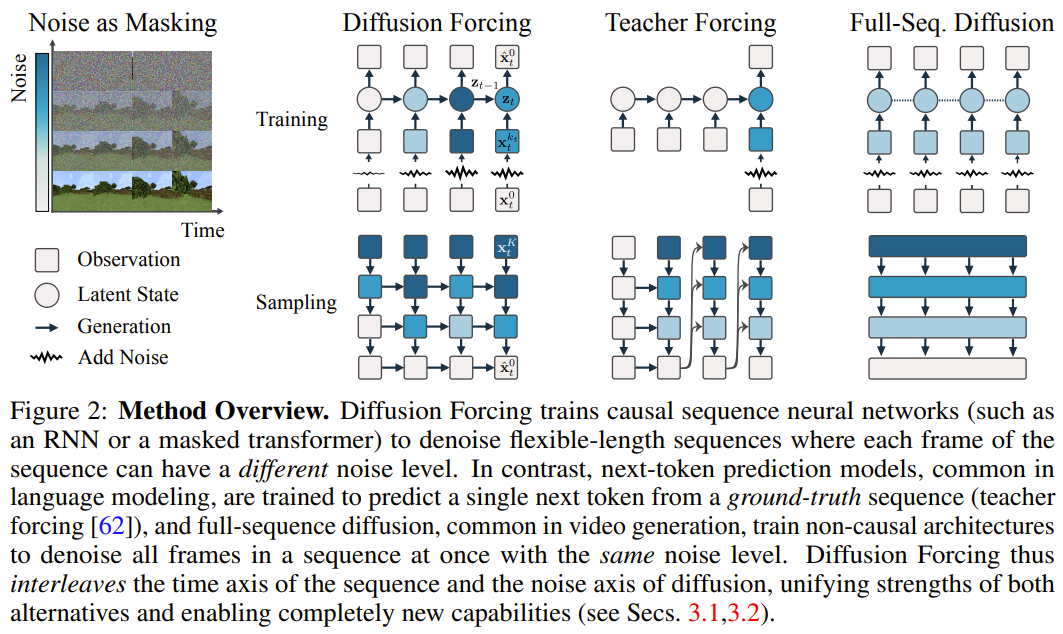
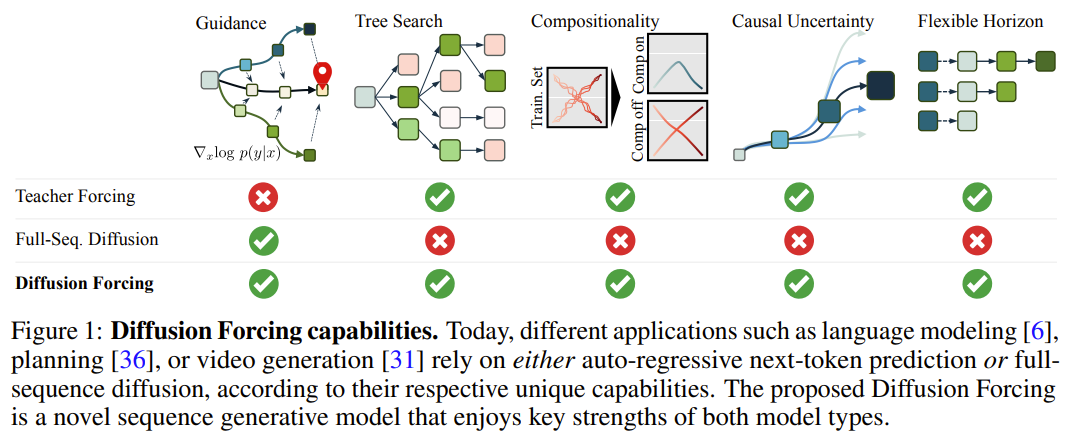
Dalam rangka kerja ini, setiap token dikaitkan dengan tahap hingar bebas rawak, dan model ramalan token seterusnya yang dikongsi atau model ramalan token seterusnya boleh digunakan mengikut skema per-token yang sewenang-wenangnya, bebas, Denoise token. Inspirasi penyelidikan kaedah ini datang dari pemerhatian ini: proses menambah hingar pada token adalah satu bentuk proses penyamaran separa - bunyi sifar bermakna token tidak bertopeng, manakala hingar lengkap adalah sepenuhnya Token Masking. Oleh itu, DF memaksa model untuk mempelajari topeng yang mengalih keluar sebarang set pembolehubah token bising (Rajah 2). Pada masa yang sama, dengan membuat parameter kaedah ramalan sebagai gabungan beberapa model ramalan token seterusnya, sistem secara fleksibel boleh menjana jujukan dengan panjang yang berbeza dan membuat generalisasi kepada trajektori baharu secara gabungan (Rajah 1). Pasukan melaksanakan DF yang digunakan untuk penjanaan jujukan ke dalam Causal Diffusion Forcing (CDF), di mana token masa hadapan bergantung pada token masa lalu melalui seni bina sebab. Mereka melatih model untuk menafikan semua token urutan (di mana setiap token mempunyai tahap hingar bebas) sekaligus. Semasa pensampelan, CDF akan secara beransur-ansur menolak jujukan bingkai hingar Gaussian menjadi sampel bersih, di mana bingkai yang berbeza mungkin mempunyai aras hingar yang berbeza pada setiap langkah denosing. Sama seperti model ramalan token seterusnya, CDF boleh menjana jujukan panjang berubah-ubah, tidak seperti ramalan token seterusnya, prestasi CDF adalah sangat stabil - sama ada ia meramalkan token seterusnya, beribu-ribu token pada masa hadapan, atau malah token berterusan. Selain itu, sama dengan penyebaran jujukan penuh, ia juga boleh menerima bimbingan, membolehkan penjanaan ganjaran yang tinggi. Dengan secara kolaboratif memanfaatkan kausalitas, skop fleksibel dan penjadualan hingar berubah-ubah, CDF mendayakan ciri baharu: Monte Carlo Tree Guidance (MCTG). Berbanding dengan model resapan jujukan penuh bukan sebab, MCTG boleh meningkatkan kadar pensampelan bagi penjanaan ganjaran yang tinggi. Rajah 1 memberikan gambaran keseluruhan keupayaan ini. . atau tidak) sebagai Koleksi tertib yang diindeks oleh t. Kemudian, menggunakan paksaan guru untuk melatih ramalan token seterusnya boleh ditafsirkan sebagai menutup setiap token x_t pada masa t dan meramalkannya berdasarkan x_{1:t−1} lalu. Untuk jujukan, operasi ini boleh digambarkan sebagai: melakukan penyamaran sepanjang garis masa. Kita boleh menganggap resapan ke hadapan urutan penuh (iaitu proses menambah bunyi secara beransur-ansur pada data ) sebagai sejenis penutupan separa, yang boleh dipanggil "melakukan penutupan sepanjang paksi hingar Sebenarnya, selepas menambah hingar dalam langkah K, adalah (mungkin) bunyi putih, dan tiada lagi sebarang maklumat tentang data asal Seperti yang ditunjukkan dalam Rajah 2, pasukan itu mewujudkan perspektif bersatu untuk melihat pada tepi bagi kedua-dua paksi ini . 2. Pemaksaan resapan: Token yang berbeza mempunyai tahap hingar yang berbeza Rangka kerja pemaksaan resapan (DF) boleh digunakan untuk melatih dan sampel token bising dengan panjang jujukan yang sewenang-wenangnya tahap hingar k_t setiap token berubah dengan langkah masa  Makalah ini memfokuskan pada data siri masa, jadi mereka membuat instantiat DF melalui seni bina sebab, dan dengan itu mendapat pemaksaan sebab-sebab (CDF). pelaksanaan minimum yang diperolehi menggunakan rangkaian saraf berulang asas (RNN). RNN dengan berat θ mengekalkan keadaan tersembunyi z_t yang dimaklumkan tentang pengaruh token lalu Ia akan berkembang mengikut dinamik melalui lapisan gelung.Lorsqu'une observation de bruit d'entrée est obtenue, l'état caché est mis à jour de manière markovienne. Quand k_t=0, c'est la mise à jour postérieure du filtrage bayésien ; et quand k_t=K (bruit pur, aucune information), cela équivaut à la modélisation du filtrage bayésien p_θ(z_t | z_{. t−1}). Étant donné l'état caché z_t, le but du modèle d'observation p_θ(x_t^0 | z_t) est de prédire x_t ; le comportement entrée-sortie de cette unité est le même que le modèle de diffusion conditionnelle standard : avec le la variable de condition z_{t−1 } et le jeton bruyant en entrée, prédisent le x_t=x_t^0 silencieux, et prédisent ainsi indirectement le bruit ε^{k_t} via un reparamétrage affine. Par conséquent, nous pouvons directement utiliser la cible de diffusion classique pour entraîner le forçage de diffusion (causal). Selon le résultat de prédiction du bruit ε_θ, l'unité ci-dessus peut être paramétrée. Ensuite, les paramètres θ sont trouvés en minimisant la perte suivante : L'algorithme 1 donne le pseudocode. Le fait est que cette perte capture les éléments clés du filtrage bayésien et de la diffusion conditionnelle. L’équipe a également réinféré les techniques courantes utilisées dans la formation des modèles de diffusion pour le forçage de diffusion, comme détaillé dans l’annexe de l’article original. Ils sont également parvenus à un théorème informel. Théorème 3.1 (informel). La procédure d'entraînement forcé par diffusion (algorithme 1) est une repondération qui optimise la limite inférieure des preuves (ELBO) sur le log-vraisemblance attendue , où la valeur attendue est moyennée sur le niveau de bruit et est bruyante selon un processus direct. De plus, dans des conditions appropriées, l’optimisation (3.1) peut également maximiser simultanément la limite inférieure de vraisemblance de toutes les séquences de niveaux de bruit. Échantillonnage forcé par diffusion et capacité qui en résulteL'algorithme 2 décrit le processus d'échantillonnage, qui est défini comme : dans une grille M × T bidimensionnelle K ∈ [K]^{M×T } spécifie le programme de bruit où les colonnes correspondent aux pas de temps t et les lignes indexées par m déterminent le niveau de bruit. Pour générer la séquence entière de longueur T, le jeton x_{1:T} est d'abord initialisé au bruit blanc, correspondant au niveau de bruit k = K. Il parcourt ensuite la grille ligne par ligne et débruite colonne par colonne de gauche à droite jusqu'à ce que le niveau de bruit atteigne K. Au moment où m = 0 dans la dernière ligne, le bruit du jeton a été nettoyé, c'est-à-dire que le niveau de bruit est K_{0,t} ≡ 0. Ce paradigme d'échantillonnage apportera les nouvelles capacités suivantes :
Makalah ini memfokuskan pada data siri masa, jadi mereka membuat instantiat DF melalui seni bina sebab, dan dengan itu mendapat pemaksaan sebab-sebab (CDF). pelaksanaan minimum yang diperolehi menggunakan rangkaian saraf berulang asas (RNN). RNN dengan berat θ mengekalkan keadaan tersembunyi z_t yang dimaklumkan tentang pengaruh token lalu Ia akan berkembang mengikut dinamik melalui lapisan gelung.Lorsqu'une observation de bruit d'entrée est obtenue, l'état caché est mis à jour de manière markovienne. Quand k_t=0, c'est la mise à jour postérieure du filtrage bayésien ; et quand k_t=K (bruit pur, aucune information), cela équivaut à la modélisation du filtrage bayésien p_θ(z_t | z_{. t−1}). Étant donné l'état caché z_t, le but du modèle d'observation p_θ(x_t^0 | z_t) est de prédire x_t ; le comportement entrée-sortie de cette unité est le même que le modèle de diffusion conditionnelle standard : avec le la variable de condition z_{t−1 } et le jeton bruyant en entrée, prédisent le x_t=x_t^0 silencieux, et prédisent ainsi indirectement le bruit ε^{k_t} via un reparamétrage affine. Par conséquent, nous pouvons directement utiliser la cible de diffusion classique pour entraîner le forçage de diffusion (causal). Selon le résultat de prédiction du bruit ε_θ, l'unité ci-dessus peut être paramétrée. Ensuite, les paramètres θ sont trouvés en minimisant la perte suivante : L'algorithme 1 donne le pseudocode. Le fait est que cette perte capture les éléments clés du filtrage bayésien et de la diffusion conditionnelle. L’équipe a également réinféré les techniques courantes utilisées dans la formation des modèles de diffusion pour le forçage de diffusion, comme détaillé dans l’annexe de l’article original. Ils sont également parvenus à un théorème informel. Théorème 3.1 (informel). La procédure d'entraînement forcé par diffusion (algorithme 1) est une repondération qui optimise la limite inférieure des preuves (ELBO) sur le log-vraisemblance attendue , où la valeur attendue est moyennée sur le niveau de bruit et est bruyante selon un processus direct. De plus, dans des conditions appropriées, l’optimisation (3.1) peut également maximiser simultanément la limite inférieure de vraisemblance de toutes les séquences de niveaux de bruit. Échantillonnage forcé par diffusion et capacité qui en résulteL'algorithme 2 décrit le processus d'échantillonnage, qui est défini comme : dans une grille M × T bidimensionnelle K ∈ [K]^{M×T } spécifie le programme de bruit où les colonnes correspondent aux pas de temps t et les lignes indexées par m déterminent le niveau de bruit. Pour générer la séquence entière de longueur T, le jeton x_{1:T} est d'abord initialisé au bruit blanc, correspondant au niveau de bruit k = K. Il parcourt ensuite la grille ligne par ligne et débruite colonne par colonne de gauche à droite jusqu'à ce que le niveau de bruit atteigne K. Au moment où m = 0 dans la dernière ligne, le bruit du jeton a été nettoyé, c'est-à-dire que le niveau de bruit est K_{0,t} ≡ 0. Ce paradigme d'échantillonnage apportera les nouvelles capacités suivantes :
- Génération autorégressive stable
- Gardez l'avenir incertain
- Capacité de guidage à long terme
Utilisez le forçage de diffusion pour des décisions de séquence flexiblesLa nouvelle capacité de forçage de diffusion apporte également de nouvelles possibilités. Sur cette base, l’équipe a conçu un nouveau cadre pour la prise de décision séquentielle (SDM) et l’a appliqué avec succès aux domaines des robots et des agents autonomes. Tout d'abord, définissez un processus de décision markovien avec p dynamique (s_{t+1}|s_t, a_t), observation p (o_t|s_t) et récompense p (r_t|s_t, a_t) . Le but ici est de former une politique π(a_t|o_{1:t}) pour maximiser la récompense cumulée attendue de la trajectoire . Ici, le jeton x_t = [a_t, r_t, o_{t+1}] est alloué. Une trajectoire est une séquence x_{1:T}, dont la longueur peut être variable ; la méthode d'entraînement est celle présentée dans l'algorithme 1. A chaque étape t du processus d'exécution, il existe un état caché z_{t-1} résumant le jeton sans bruit passé x_{1:t-1}.この隠れた状態に基づいて、アルゴリズム 2 に従って計画 がサンプリングされます。ここで には、予測されたアクション、報酬、および観察が含まれます。 H は前方観測ウィンドウであり、モデル予測制御における将来予測に似ています。計画されたアクションを実行した後、環境は報酬と次の観察、つまり次のトークンを受け取ります。隠れ状態は事後 p_θ(z_t|z_{t−1}, x_t, 0) に従って更新できます。 このフレームワークは戦略とプランナーの両方として使用でき、その利点は次のとおりです:
- を達成できる将来の不確実性を達成するためのカルロ ツリー ガイダンス (MCTG)
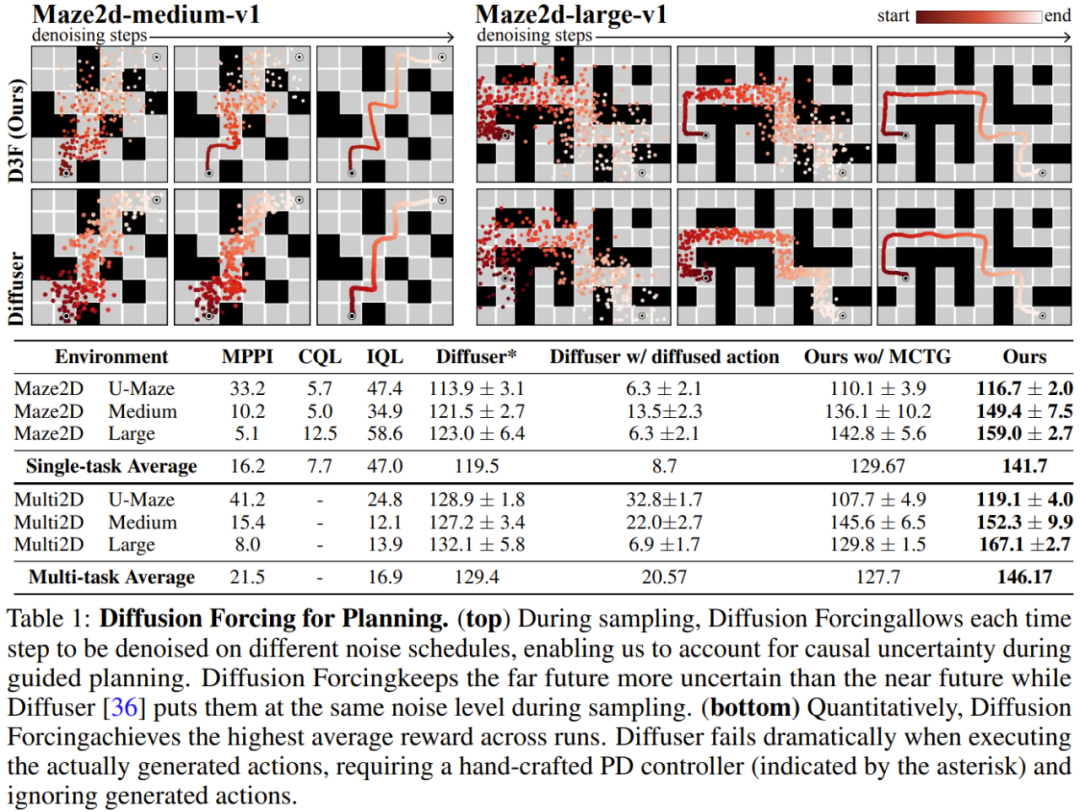
チームは、ビデオと時系列の予測、計画と模倣学習を含む生成シーケンス モデルとしての拡散強制の利点を評価しました。他のアプリケーション。 ビデオ予測: 一貫性のある安定したシーケンス生成と無限の拡張ビデオ生成モデリング タスクでは、Minecraft ゲーム ビデオと DMLab ナビゲーションの成果に基づいて、因果拡散強制のための畳み込み RNN をトレーニングしました。 図 3 は、拡散強制とベースラインの定性的な結果を示しています。 教師による強制とフルシーケンスの拡散ベンチマークはすぐに発散する一方で、拡散強制はトレーニング範囲を超えても安定して展開できることがわかります。 拡散計画: MCTG、因果不確実性、柔軟な範囲制御強制を拡散する機能は、意思決定に独自の利点をもたらすことができます。チームは、標準のオフライン強化学習フレームワークである D4RL を使用して、新しく提案された意思決定フレームワークを評価しました。 表 1 に定性的および定量的な評価結果を示します。ご覧のとおり、Diffusion Enforcement は 6 つの環境すべてで Diffuser およびすべてのベースラインを上回っています。 チームは、サンプリングスキームを変更するだけで、トレーニング時に観察されたシーケンスのサブシーケンスを柔軟に組み合わせることができることを発見しました。 彼らは 2D 軌跡データセットを使用して実験を実施しました。正方形の平面上で、すべての軌跡は 1 つの角から始まり、反対側の角で終わり、一種の十字形を形成します。 上の図 1 に示すように、組み合わせ動作が必要ない場合、DF は完全なメモリを維持し、クロスの分布を複製することができます。組み合わせが必要な場合、モデルを使用して MPC を使用してメモリレスで短い計画を生成し、それによってこの十字のサブ軌道をステッチして V 字型の軌道を取得できます。 拡散強制は、実際のロボットの視覚的動作制御に新たな機会ももたらします。 模倣学習は、専門家によって実証された観察された動作のマッピングを学習する、一般的に使用されるロボット制御手法です。ただし、記憶力が不足していると、長距離タスクの模倣学習が困難になることがよくあります。 DF はこの欠点を軽減するだけでなく、模倣学習をより堅牢にすることもできます。 記憶を模倣学習に使用します。 Franka ロボットを遠隔制御することで、チームはビデオとモーション データ セットを収集しました。図 4 に示すように、タスクは 3 番目の位置を使用してリンゴとオレンジの位置を交換することです。フルーツの初期位置はランダムであるため、可能な目標状態は 2 つあります。 さらに、3 番目の位置にフルーツがある場合、現在の観察から望ましい結果を推測することはできません。どのフルーツを移動するかを決定するために、戦略は初期構成を覚えていなければなりません。Contrairement aux méthodes de clonage de comportement couramment utilisées, DF peut naturellement intégrer des souvenirs dans son propre état caché. Il a été constaté que DF atteignait un taux de réussite de 80 %, tandis que la stratégie de diffusion (actuellement le meilleur algorithme d’apprentissage par imitation sans mémoire) échouait. De plus, DF peut également gérer le bruit de manière plus robuste et faciliter la pré-formation des robots. Prévision de séries chronologiques : le forçage de diffusion est un excellent modèle de séquence généralePour les tâches de prévision de séries chronologiques multivariées, les recherches de l'équipe montrent que DF est suffisant pour rivaliser avec les modèles de diffusion précédents et le modèle basé sur les transformateurs. comparable. Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux. Atas ialah kandungan terperinci Penjanaan video tanpa had, perancangan dan membuat keputusan, penyebaran paksa penyepaduan ramalan token seterusnya dan penyebaran jujukan penuh. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



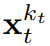 est obtenue, l'état caché est mis à jour de manière markovienne.
est obtenue, l'état caché est mis à jour de manière markovienne. 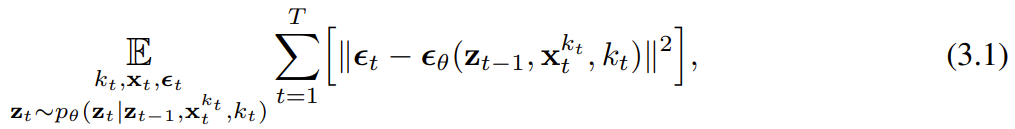

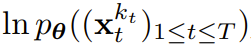 , où la valeur attendue est moyennée sur le niveau de bruit et
, où la valeur attendue est moyennée sur le niveau de bruit et 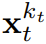 est bruyante selon un processus direct. De plus, dans des conditions appropriées, l’optimisation (3.1) peut également maximiser simultanément la limite inférieure de vraisemblance de toutes les séquences de niveaux de bruit.
est bruyante selon un processus direct. De plus, dans des conditions appropriées, l’optimisation (3.1) peut également maximiser simultanément la limite inférieure de vraisemblance de toutes les séquences de niveaux de bruit. 
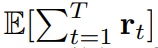 . Ici, le jeton x_t = [a_t, r_t, o_{t+1}] est alloué. Une trajectoire est une séquence x_{1:T}, dont la longueur peut être variable ; la méthode d'entraînement est celle présentée dans l'algorithme 1.
. Ici, le jeton x_t = [a_t, r_t, o_{t+1}] est alloué. Une trajectoire est une séquence x_{1:T}, dont la longueur peut être variable ; la méthode d'entraînement est celle présentée dans l'algorithme 1. 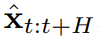 がサンプリングされます。ここで
がサンプリングされます。ここで 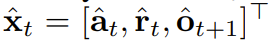 には、予測されたアクション、報酬、および観察が含まれます。 H は前方観測ウィンドウであり、モデル予測制御における将来予測に似ています。計画されたアクションを実行した後、環境は報酬と次の観察、つまり次のトークンを受け取ります。隠れ状態は事後 p_θ(z_t|z_{t−1}, x_t, 0) に従って更新できます。
には、予測されたアクション、報酬、および観察が含まれます。 H は前方観測ウィンドウであり、モデル予測制御における将来予測に似ています。計画されたアクションを実行した後、環境は報酬と次の観察、つまり次のトークンを受け取ります。隠れ状態は事後 p_θ(z_t|z_{t−1}, x_t, 0) に従って更新できます。