
Rumah >Peranti teknologi >AI >Pada persidangan robotik teratas RSS 2024, penyelidikan robot humanoid China memenangi anugerah kertas terbaik
Pada persidangan robotik teratas RSS 2024, penyelidikan robot humanoid China memenangi anugerah kertas terbaik

- 王林asal
- 2024-07-22 14:56:45894semak imbas
최근 네덜란드 델프트공과대학교에서 로봇공학 분야의 유명 학회인 RSS(Robotics: Science and Systems) 2024가 성공적으로 마무리되었습니다.
컨퍼런스 규모는 NeurIPS, CVPR 등 최고의 AI 컨퍼런스와 비교할 수 없지만 RSS는 지난 몇 년간 큰 발전을 이루었으며 올해는 거의 900명이 참가했습니다. 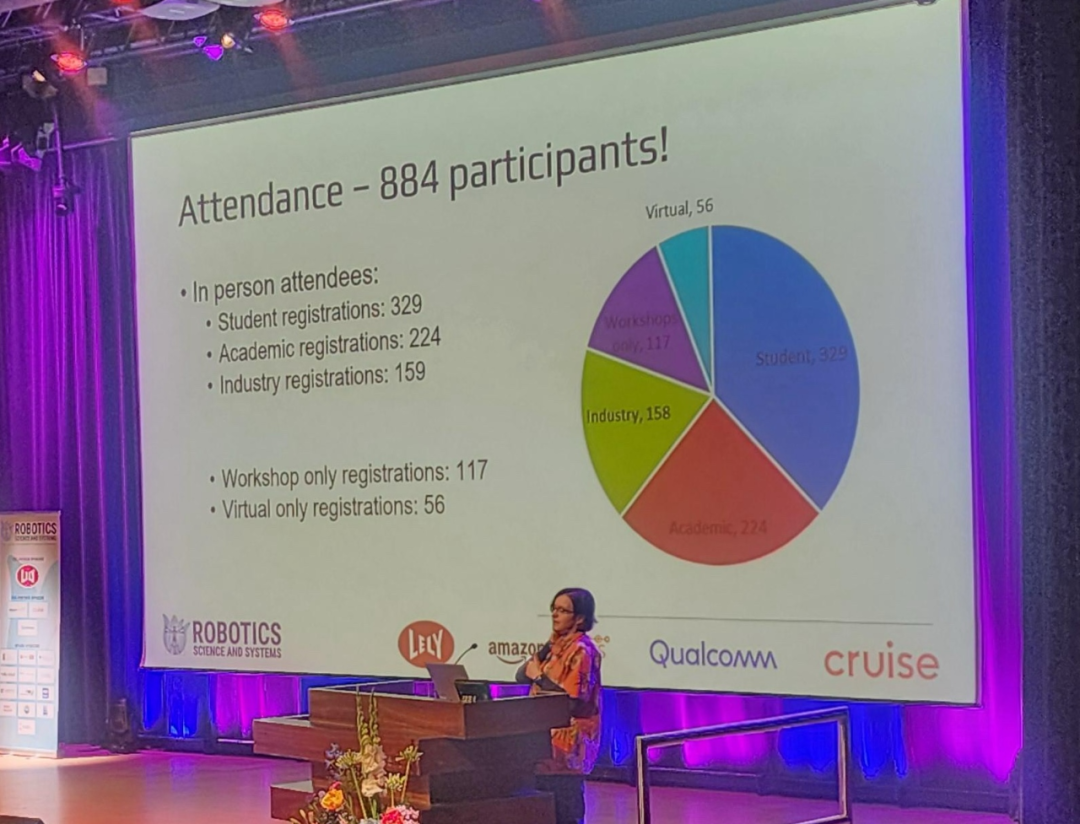
컨퍼런스 마지막 날에는 Best Paper, Best Student Paper, Best System Paper, Best Demo Paper 등 여러 상이 동시에 발표되었습니다. 또한 컨퍼런스에서는 'Early Career Spotlight Award'와 'Time Test Award'도 선정했습니다.
칭화대학교와 베이징 싱동 시대 과학 기술 유한 회사의 휴머노이드 로봇 연구가 최우수 논문상을 수상했으며, 중국 학자 Ji Zhang이 이번 시험상을 수상했다는 점은 주목할 만합니다.
다음은 수상 논문에 대한 정보입니다.
Best Demo Paper Award

논문 제목: CropFollow++ 시연: 키포인트를 사용한 강력한 캐노피 아래 탐색
저자: Arun Narenthiran Siv 아쿠마르 , Mateus Valverde Gasparino, Michael McGuire, Vitor Akihiro Hisano Higuti, M. Ugur Akcal, Girish Chowdhary
기관: UIUC, Earth Sense
논문 링크: https://enriquecoronadozu.github.io/rssproceedings2024/rss20/ p023.pdf
본 논문에서 연구자들은 의미론적 핵심 포인트를 사용하여 농작물 캐노피 농업 로봇을 위한 경험 기반의 강력한 시각적 탐색 시스템을 제안합니다.
작물 캐노피 아래에서 자동 탐색은 작은 작물 행 간격(~0.75미터), 다중 경로 오류로 인한 RTK-GPS 정확도 감소, 과도한 혼란으로 인한 LiDAR 측정 소음으로 인해 어렵습니다. CropFollow라는 초기 작업에서는 학습 기반의 엔드 투 엔드 지각 시각적 탐색 시스템을 제안하여 이러한 문제를 해결했습니다. 그러나 이 접근 방식에는 해석 가능한 표현이 부족하고 신뢰도가 부족하여 폐색 중 이상치 예측에 대한 민감도가 부족하다는 한계가 있습니다.
이 기사의 CropFollow++ 시스템은 모듈식 인식 아키텍처와 학습된 의미론적 핵심 포인트 표현을 소개합니다. CropFollow에 비해 CropFollow++는 더 모듈화되고 해석이 더 쉬우며 폐색 감지에 더 큰 신뢰도를 제공합니다. CropFollow++는 각각 1.9km에 걸쳐 13번 대 33번의 충돌이 필요한 까다로운 후기 시즌 현장 테스트에서 CropFollow보다 훨씬 더 나은 성능을 보였습니다. 또한 다양한 현장 조건에서 여러 개의 작물 아래 캐노피 덮개 자르기 로봇(총 길이 25km)에 CropFollow++를 대규모로 배포하여 배운 주요 교훈에 대해서도 논의합니다.

논문 제목: 상태 추정 없이 픽셀에서 민첩한 비행 시연
저자: smail Geles, Leonard Bauersfeld, Angel Romero, Jiaxu Xing, Davide Scaramuzza
논문 링크: https://enriquecoron 아도즈 .github.io/rssproceedings2024/rss20/p082.pdf
쿼드콥터 드론은 가장 민첩한 비행 로봇 중 하나입니다. 최근 일부 연구에서 학습 기반 제어 및 컴퓨터 비전이 발전했지만 자율 드론은 여전히 명시적인 상태 추정에 의존합니다. 반면에 인간 조종사는 드론에 탑재된 카메라가 제공하는 1인칭 비디오 스트림에만 의존하여 플랫폼을 한계까지 밀어붙이고 보이지 않는 환경에서도 꾸준히 비행할 수 있습니다.
이 기사에서는 픽셀을 제어 명령에 직접 매핑하면서 고속으로 일련의 문을 자율적으로 탐색할 수 있는 최초의 비전 기반 쿼드콥터 드론 시스템을 보여줍니다. 전문 드론 레이서와 마찬가지로 시스템은 명시적인 상태 추정을 사용하지 않고 대신 인간과 동일한 제어 명령(집단 추력 및 신체 속도)을 사용합니다. 연구원들은 최대 40km/h의 속도와 최대 2g의 가속도에서 민첩한 비행을 시연했습니다. 이는 강화 학습(RL)을 통해 비전 기반 정책을 교육함으로써 달성됩니다. 비대칭 Actor-Critic을 사용하면 특권적인 정보를 얻고 훈련을 용이하게 할 수 있습니다. 이미지 기반 RL 훈련 중 계산 복잡성을 극복하기 위해 게이트의 내부 가장자리를 센서 추상화로 사용합니다. 이 간단하면서도 강력한 작업 관련 표현은 훈련 중에 이미지를 렌더링하지 않고도 시뮬레이션할 수 있습니다. 배포 과정에서 연구원들은 Swin Transformer를 기반으로 한 도어 감지기를 사용했습니다.
이 문서의 방법은 표준 기성 하드웨어를 사용하여 자율적이고 민첩한 비행을 달성할 수 있습니다. 이번 시연은 드론 경주에 중점을 두었지만, 이 접근 방식은 경쟁을 넘어서는 의미를 가지며 구조화된 환경에서 실제 응용 프로그램에 대한 향후 연구의 기반이 될 수 있습니다.
최고 시스템 논문상

論文のタイトル: ユニバーサル操作インターフェース: 野生ロボットを使用しない野生ロボットの教育
Cheng Chi、Zhenjia Xu、Chuer Pan、Eric Cousineau、Benjamin Burchfiel、Siyuan Feng、Russ Tedrake、Shuran Song
機関: スタンフォード大学、コロンビア大学、トヨタ研究所
論文リンク: https://arxiv.org/pdf/2402.10329
この記事では、Universal Manipulation Interface (UMI) を紹介します。野生の人間が実証したスキルを展開可能なロボット ポリシーに直接転送する、データ収集およびポリシー学習フレームワーク。 UMI は、ハンドヘルド グリッパーと慎重なインターフェイス設計を利用して、困難な双腕操作や動的操作のデモンストレーションに、ポータブルで低コストの情報豊富なデータ収集を提供します。展開可能なポリシー学習を促進するために、UMI は、推論時間遅延マッチングおよび相対軌跡アクション表現機能を備えた、慎重に設計されたポリシー インターフェイスを採用しています。学習されたポリシーはハードウェアに依存せず、複数のロボット プラットフォームに展開できます。これらの機能により、UMI フレームワークは新しいロボット操作機能を解放し、各タスクのトレーニング データを変更するだけで、動的、双腕、正確、長視野動作のゼロショット一般化を可能にします。研究者らは、UMI Zero RFで学習したポリシーが、さまざまな人間のデモンストレーションでトレーニングされたときに新しい環境やオブジェクトに一般化されるという包括的な実世界の実験を通じて、UMIの多用途性と有効性を実証しました。

論文タイトル: Khronos: A Unified Approach for Spatio-Temporal Metric-Semantic SLAM in Dynamic Environs
著者: Lukas Schmid、Marcus Abate、Yun Chang、Luca Carlone
論文リンク: https://arxiv.org/pdf/2402.13817
非常に動的で変化する環境を認識して理解することは、ロボットの自律性にとって重要な能力です。ロボットのポーズを正確に推定できる動的 SLAM 手法の開発ではかなりの進歩が見られましたが、ロボット環境の高密度の時空間表現の構築には十分な注意が払われてきませんでした。シナリオとその時間の経過に伴う進化を詳細に理解することは、ロボットの長期的な自律性にとって重要であり、人間や他のエージェントと共有される環境で効果的に動作するなど、長期的な推論を必要とするタスクにも重要です。したがって、短期および長期の制約を受けることになります。
この課題に対処するために、この研究では時空間計量意味論的 SLAM (SMS) 問題を定義し、問題を効果的に分解して解決するためのフレームワークを提案します。我々は、提案された因数分解が、時空間知覚システムの自然な組織化を示唆していることを示します。この場合、高速なプロセスはアクティブな時間枠内の短期的なダイナミクスを追跡し、別の遅いプロセスは因子グラフを使用して環境の長期的な変化への応答を表現します。推論。研究者らは、効率的な時空間認識方法であるクロノスを提供し、それが短期および長期のダイナミクスの既存の説明を統合し、リアルタイムで高密度の時空間マップを構築できることを実証しました。
論文で提供されているシミュレーションと実際の結果は、クロノスによって構築された時空間マップが 3 次元シーンの時間的変化を正確に反映でき、クロノスが複数の指標でベースラインを上回っていることを示しています。
最優秀学生論文賞

論文タイトル: Controlled Slidingによる動的オンパームマニピュレーション
著者: William Yang、Michael Posa
機関: ペンシルバニア大学
論文リンク: https://arxiv.org/pdf/2405.08731
現在、非掴み動作を実行するロボットの研究は、滑りによって引き起こされる可能性のある問題を回避するために主に静的接触に焦点を当てています。しかし、「手の滑り」の問題を根本的に解消する、つまり接触時の滑りを制御することができれば、ロボットの新たな行動領域が広がります。
この論文では、研究者らは、さまざまな混合接触モードを包括的に考慮する必要がある、挑戦的な動的非把握操作タスクを提案しています。研究者らは、最新の暗黙的接触モデル予測制御 (MPC) テクノロジーを使用して、ロボットがさまざまなタスクを完了するためのマルチモーダルな計画を実行できるようにしました。この論文では、MPC の単純化されたモデルを低レベルの追跡コントローラーと統合する方法と、暗黙的接触 MPC を動的タスクのニーズに適応させる方法について詳しく説明します。

印象的なのは、摩擦および剛体接触モデルは不正確であることが多いことが知られているにもかかわらず、この論文のアプローチはタスクを迅速に完了しながら、これらの不正確さに敏感に対応することができます。さらに、研究者らは、ロボットがタスクを完了するのを支援するために、基準軌道やモーションプリミティブなどの一般的な補助ツールを使用しなかった。これは、この方法の多用途性をさらに強調している。暗黙的接触 MPC テクノロジーが 3 次元空間での動的操作タスクに適用されたのはこれが初めてです。
.Institusi : CMU, ETH Zurich, Switzerland 
- Pautan kertas: https://arxiv.org/pdf/2401.17583
- Apabila robot berkaki empat bergerak melalui persekitaran yang bersepah, mereka perlu mempunyai kedua-dua fleksibiliti dan keselamatan. Mereka perlu dapat menyelesaikan tugas dengan cepat sambil mengelakkan perlanggaran dengan orang atau halangan. Walau bagaimanapun, penyelidikan sedia ada selalunya hanya menumpukan pada satu aspek: sama ada mereka bentuk pengawal konservatif dengan kelajuan tidak lebih daripada 1.0 m/s untuk keselamatan, atau mengejar fleksibiliti tetapi mengabaikan masalah perlanggaran yang boleh membawa maut. Kertas kerja ini mencadangkan rangka kerja kawalan yang dipanggil "Agile and Secure". Rangka kerja ini membolehkan robot berkaki empat mengelakkan halangan dan orang dengan selamat sambil mengekalkan fleksibiliti, mencapai jalan kaki tanpa perlanggaran.
- ABS merangkumi dua set strategi: satu adalah untuk mengajar robot bagaimana untuk ulang-alik secara fleksibel dan lincah antara halangan, dan satu lagi adalah untuk mengajar robot bagaimana untuk pulih dengan cepat jika ia menghadapi masalah untuk memastikan bahawa robot tidak jatuh atau terkena sesuatu. Kedua-dua strategi saling melengkapi. Dalam sistem ABS, penukaran strategi dikawal oleh rangkaian nilai pengelakan perlanggaran berdasarkan teori kawalan pembelajaran. Rangkaian ini bukan sahaja menentukan masa untuk menukar strategi, tetapi juga menyediakan fungsi objektif untuk strategi pemulihan, memastikan robot sentiasa kekal selamat dalam sistem kawalan gelung tertutup. Dengan cara ini, robot boleh bertindak balas secara fleksibel kepada pelbagai situasi dalam persekitaran yang kompleks.
- Untuk melatih strategi dan rangkaian ini, penyelidik telah menjalankan latihan yang meluas dalam persekitaran simulasi, termasuk strategi tangkas, rangkaian nilai mengelakkan perlanggaran, strategi pemulihan dan rangkaian perwakilan persepsi luaran, dsb. Modul terlatih ini boleh diaplikasikan secara langsung ke dunia nyata Dengan persepsi dan keupayaan pengkomputeran robot itu sendiri, sama ada robot itu berada di dalam atau dalam ruang luar yang terhad, sama ada ia menghadapi halangan tidak bergerak atau boleh alih, ia boleh Bertindak dengan cepat dan selamat dalam lingkungan. rangka kerja ABS. Sekiranya anda ingin mengetahui lebih lanjut, anda boleh merujuk kepada pengenalan sebelum ini untuk kertas ini di laman web ini. .
Institusi: Texas Universiti Austin
Pautan kertas: https://arxiv.org/pdf/2405.03666
Jika anda ingin mengajar robot cara melakukan sesuatu dengan dua tangan pada masa yang sama, seperti membuka kotak di pada masa yang sama, ia sebenarnya adalah kesukaran yang sangat sukar. Kerana robot itu perlu mengawal banyak sendi pada masa yang sama, ia juga perlu memastikan bahawa pergerakan kedua-dua tangan diselaraskan. Bagi manusia, orang belajar tindakan baru dengan memerhati orang lain, kemudian mencubanya sendiri dan terus memperbaiki. Dalam kertas kerja ini, penyelidik merujuk kepada kaedah pembelajaran manusia supaya robot dapat mempelajari kemahiran baru dengan menonton video dan memperbaikinya dalam amalan.
Para penyelidik mendapat inspirasi daripada kajian psikologi dan biomekanik Mereka membayangkan pergerakan kedua-dua tangan sebagai rantai khas yang boleh berputar seperti skru, yang dipanggil "tindakan spiral." Berdasarkan ini, mereka membangunkan sistem yang dipanggil ScrewMimic. Sistem ini boleh membantu robot lebih memahami demonstrasi manusia dan memperbaiki tindakan melalui penyeliaan diri. Melalui eksperimen, para penyelidik mendapati bahawa sistem ScrewMimic boleh membantu robot mempelajari kemahiran operasi dua tangan yang kompleks daripada video, dan mengatasi dalam prestasi sistem yang belajar dan bertambah baik secara langsung dalam ruang tindakan asal. 

- Institusi: Beijing Xingdong Era Technology Co., Ltd., Universiti Tsinghua
Lien papier : https://enriquecoronadozu.github.io/rssproceedings2024/rss20/p058.pdf
La technologie actuelle ne peut permettre aux robots humanoïdes de marcher que sur un sol plat et un terrain aussi simple. Cependant, il reste difficile de les laisser se déplacer librement dans des environnements complexes, comme de véritables scènes extérieures. Dans cet article, les chercheurs proposent une nouvelle méthode appelée apprentissage de modèle mondial de débruitage (DWL).
DWL est un cadre d'apprentissage par renforcement de bout en bout pour le contrôle des mouvements des robots humanoïdes. Ce cadre permet au robot de s'adapter à une variété de terrains inégaux et difficiles, tels que la neige, les pentes et les escaliers. Il convient de mentionner que ces robots ne nécessitent qu’un seul processus d’apprentissage et peuvent relever divers défis de terrain dans le monde réel sans formation spéciale supplémentaire.

Cette recherche a été réalisée conjointement par Beijing Xingdong Era Technology Co., Ltd. et l'Université Tsinghua. Fondée en 2023, Xingdong Era est une entreprise technologique incubée par l'Institut de recherche en informations croisées de l'Université Tsinghua qui développe des technologies et des produits d'intelligence incarnée et de robots humanoïdes généraux. Le fondateur est Chen Jianyu, professeur adjoint et directeur de doctorat à l'Institut de recherche en informations croisées de l'Université Tsinghua. , axé sur l'application de pointe de l'intelligence artificielle générale (AGI), s'engage dans le développement de robots humanoïdes universels capables de s'adapter à un large éventail de domaines, de scénarios multiples et d'une intelligence élevée.

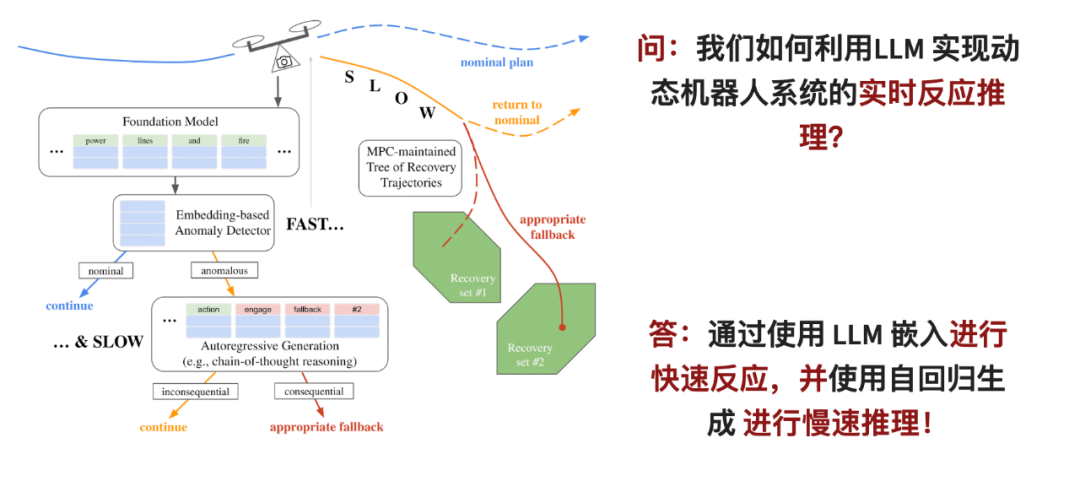
Titre de l'article : Détection d'anomalies en temps réel et planification réactive avec de grands modèles de langage
Auteurs : Rohan Sinha, Amine Elhafsi, Christopher Agia, Matt Foutter, Edward Schmerling, Marco Pavone
Institution :Stanford University
Lien papier : https://arxiv.org/pdf/2407.08735
Les grands modèles de langage (LLM), dotés de capacités de généralisation sans tir, ce qui les rend prometteurs pour les robots de détection et d'exclusion. Techniques pour défaillance hors distribution des systèmes. Cependant, pour que les modèles de langage à grande échelle fonctionnent réellement, deux problèmes doivent être résolus : premièrement, LLM nécessite que de nombreuses ressources informatiques soient appliquées en ligne ; deuxièmement, le jugement de LLM doit être intégré dans le système de contrôle de sécurité du robot.
Dans cet article, les chercheurs ont proposé un cadre de raisonnement en deux étapes : pour la première étape, ils ont conçu un détecteur d'anomalies rapide qui peut analyser rapidement les observations du robot dans l'espace de compréhension du LLM si des problèmes sont détectés, la suivante ; l’étape de sélection alternative est entrée. À ce stade, les capacités d'inférence de LLM sont utilisées pour effectuer une analyse plus approfondie.
L'étape entrée correspond au point de branchement de la stratégie de contrôle prédictif du modèle, qui peut suivre et évaluer simultanément différents plans alternatifs pour résoudre le problème de latence des raisonneurs lents. Une fois que le système détecte une anomalie ou un problème, cette stratégie sera activée immédiatement pour garantir la sécurité des actions du robot.
Le classificateur d'anomalies rapide présenté dans cet article surpasse l'inférence autorégressive utilisant des modèles GPT de pointe, même lors de l'utilisation de modèles de langage relativement petits. Cela permet au moniteur en temps réel proposé dans l'article d'améliorer la fiabilité des robots dynamiques avec des ressources et un temps limités, comme dans les quadricoptères et les voitures sans conducteur.

Titre du papier: Configuration Espace Distance Fields for Manipulation Planning
author: Yiming Li, Xuemin Chi, Amirreza Razmjoo, Sylvain Calion
Institution: Suisse I Diap Institute, Lausanne, Institut fédéral de technologie de Suisse, Université du Zhejiang
Lien papier : https://arxiv.org/pdf/2406.01137
Le champ de distance signé (SDF) est une représentation de forme implicite populaire en robotique, qui fournit des informations géométriques sur objets et obstacles et peut être facilement combiné avec des techniques de contrôle, d’optimisation et d’apprentissage. SDF est généralement utilisé pour représenter les distances dans l'espace des tâches, ce qui correspond à la notion de distance perçue par les humains dans le monde 3D.
Dans le domaine des robots, SDF est souvent utilisé pour représenter l'angle de chaque articulation du robot. Les chercheurs savent généralement quelles zones de l'espace angulaire des articulations du robot sont sûres, c'est-à-dire que les articulations du robot peuvent pivoter vers ces zones sans collision. Cependant, ils n’expriment pas souvent ces zones de sécurité en termes de champs de distance.
이 논문에서 연구원들은 구성 공간 거리 필드(줄여서 CDF)라고 부르는 로봇 구성 공간을 최적화하기 위해 SDF를 사용할 수 있는 가능성을 제안합니다. SDF를 사용하는 것과 유사하게 CDF는 효율적인 관절 각도 거리 조회 및 파생 항목(관절 각속도)에 대한 직접 액세스를 제공합니다. 일반적으로 로봇 계획은 두 단계로 나뉩니다. 먼저 작업 공간에서 동작이 대상과 얼마나 떨어져 있는지 확인한 다음 역기구학을 사용하여 관절이 어떻게 회전하는지 계산합니다. 그러나 CDF는 이 두 단계를 하나의 단계로 결합하여 로봇의 관절 공간에서 직접 문제를 해결하므로 더 간단하고 효율적입니다. 논문에서 연구진은 어떤 시나리오에도 확장할 수 있는 CDF를 계산하고 융합하는 효율적인 알고리즘을 제안했습니다.
또한 그들은 다층 퍼셉트론(MLP)을 사용하여 간결하고 연속적인 표현을 얻고 계산 효율성을 향상시키는 해당 신경 CDF 표현을 제안했습니다. 이 논문에서는 로봇이 비행기의 장애물을 피하도록 하고, 7축 로봇 Franka가 일부 행동 계획 작업을 완료하도록 하는 등 CDF의 효과를 보여주는 몇 가지 구체적인 예를 제공합니다. 이러한 예는 CDF의 효율성을 보여줍니다.机 CDF 방식의 로봇 팔은 상자 작업으로 구성됩니다.

Early Professional SPOTLIGHT 컨퍼런스에서도 Early Professional Spotlight Award를 수상한 사람이 바로 Stefan Leutenegger입니다. 알 수 없는 환경.
Stefan Leutenegger는 뮌헨 기술 대학(TUM)의 컴퓨팅 정보 기술 대학(CIT)의 조교수이며 뮌헨 로봇 공학 및 기계 지능 연구소( MIRMI) 및 뮌헨 데이터 과학 연구소(MDSI)는 뮌헨 기계 학습 센터(MCML)와 연계되어 있으며 다이슨 로봇 공학 연구소의 회원이었습니다. 그가 이끄는 스마트 로봇 연구소(SRL)는 인식, 모바일 로봇, 드론 및 기계 학습의 교차점에 대한 연구에 전념하고 있습니다. 또한 Stefan은 Imperial College London 컴퓨터학과의 방문 강사이기도 합니다.
그는 로봇과 드론을 위한 측위 및 매핑 솔루션의 상용화를 목표로 하는 스핀아웃 회사인 SLAMcore를 공동 창립했습니다. Stefan은 ETH 취리히에서 기계 공학 학사 및 석사 학위를 취득했으며 2014년 "무인 태양열 항공기: 효율적이고 견고한 자율 운영을 위한 설계 및 알고리즘"이라는 논문으로 박사 학위를 받았습니다.
 Test of Time Award
Test of Time Award
논문 링크: https://www.ri.cmu.edu/pub_files/2014/7/Ji_LidarMapping_RSS2014_v8.pdf
이 10년 된 논문은 double A의 6-DOF 이동을 활용하는 방법을 제안합니다. 축 라이더 주행 데이터의 주행 거리 측정 및 매핑을 위한 실시간 방법입니다. 이 문제를 해결하기 어려운 이유는 거리 측정 데이터가 서로 다른 시간에 수신되고, 움직임 추정 오류로 인해 결과 포인트 클라우드가 잘못 등록될 수 있기 때문입니다. 일관된 3D 맵은 오프라인 배치 방법으로 구축할 수 있으며, 종종 시간 경과에 따른 드리프트를 수정하기 위해 루프 폐쇄를 사용합니다. 본 논문의 방법은 고정밀 범위 측정이나 관성 측정이 필요하지 않으며 낮은 드리프트와 낮은 계산 복잡성을 달성할 수 있습니다.
이 수준의 성능을 달성하는 열쇠는 복잡한 동시 위치 지정 및 매핑 문제를 두 가지 알고리즘으로 분할하여 많은 수의 변수를 동시에 최적화하는 것입니다. 한 알고리즘은 라이더 속도를 추정하기 위해 높은 빈도로 범위 지정을 수행하지만 정확도는 낮습니다. 다른 알고리즘은 포인트 클라우드의 정밀한 일치 및 등록을 위해 훨씬 더 낮은 주파수에서 작동합니다. 이 두 가지 알고리즘을 결합하면 실시간으로 그리는 방법이 가능해집니다. 연구진은 광범위한 실험과 KITTI 속도 벤치마크를 통해 이를 평가했으며, 그 결과 이 방법이 오프라인 배치 방법의 SOTA 정확도 수준을 달성할 수 있는 것으로 나타났습니다. 
)를 참고해주세요.
Atas ialah kandungan terperinci Pada persidangan robotik teratas RSS 2024, penyelidikan robot humanoid China memenangi anugerah kertas terbaik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI