
Rumah >Peranti teknologi >AI >Dengan kecekapan tinggi dan tidak memerlukan label, pasukan Google menggunakan AI untuk melombong data klinikal, meningkatkan penemuan gen dan ramalan penyakit serta diterbitkan dalam sub-jurnal Nature
Dengan kecekapan tinggi dan tidak memerlukan label, pasukan Google menggunakan AI untuk melombong data klinikal, meningkatkan penemuan gen dan ramalan penyakit serta diterbitkan dalam sub-jurnal Nature

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-07-19 21:45:12534semak imbas

Editor |. ScienceAI
Sistem penjagaan kesihatan moden menjana sejumlah besar data klinikal berdimensi tinggi (HDCD), seperti peta fungsi paru-paru, photoplethysmography (PPG), rakaman elektrokardiogram (ECG), imbasan CT dan pengimejan ini data tidak boleh diringkaskan dengan satu nombor binari atau berterusan.
Memahami kaitan antara genom kita dan HDCD bukan sahaja akan meningkatkan pemahaman kita tentang penyakit ini tetapi juga akan menjadi kritikal kepada pembangunan rawatan untuk penyakit itu.
Baru-baru ini, pasukan genomik di Google Research telah mencapai kemajuan dalam menggunakan HDCD untuk mencirikan penyakit dan ciri biologi.
Pasukan penyelidik mencadangkan model pembelajaran mendalam tanpa pengawasan, Pembelajaran Perwakilan untuk Penemuan Gen Penyematan Dimensi Rendah (REGLE), untuk menemui perkaitan antara varian genetik dan HDCD.
REGLE, sebagai kaedah penemuan gen baru, boleh mengeksploitasi maklumat tersembunyi dalam data klinikal berdimensi tinggi, cekap dari segi pengiraan, tidak memerlukan label penyakit dan boleh menyepadukan maklumat daripada pengetahuan yang ditentukan pakar.
Secara keseluruhannya, REGLE mengandungi maklumat yang berkaitan secara klinikal melebihi apa yang ditangkap oleh tandatangan yang ditetapkan pakar sedia ada, membolehkan penemuan gen dan ramalan penyakit yang lebih baik.
Penyelidikan berkaitan bertajuk "Pembelajaran perwakilan tanpa pengawasan pada data klinikal berdimensi tinggi meningkatkan penemuan dan ramalan genomik" dan telah diterbitkan dalam "Nature Genetics" pada 8 Julai.

Pautan kertas: https://www.nature.com/articles/s41588-024-01831-6
Mendedahkan maklumat tersembunyi dalam HDCD
sambungan genes HDCDpendekatan mudah adalah untuk melaksanakan GWAS pada setiap koordinat data Sebagai contoh, anda boleh mengkaji perubahan dalam nilai setiap piksel dalam imej perubatan. Pendekatan ini adalah mahal dari segi pengiraan dan mempunyai kuasa yang rendah untuk mengesan perkaitan yang ketara disebabkan oleh korelasi yang tinggi antara koordinat jiran dan beban ujian berganda yang besar.
Pendekatan yang lebih biasa ialah memfokuskan pada sebilangan kecil ciri yang ditentukan pakar (EDF) yang diekstrak daripada HDCD sebagai ciri sasaran atau fenotip untuk GWAS. EDF boleh memasukkan ciri yang diketahui secara klinikal seperti kapasiti vital paksa (FVC) daripada spirometri atau volum hembusan paksa dalam 1 saat (FEV1).
Walaupun EDF ini adalah ciri penting yang ditemui oleh pakar, diandaikan bahawa ia mungkin tidak menangkap sepenuhnya isyarat yang dikodkan dalam HDCD, jadi menjalankan GWAS pada isyarat ini mungkin tidak mengeksploitasi potensi penuh HDCD.
REGLE menyasarkan untuk mengatasi batasan ini menggunakan model pengekod auto variasi (VAE). Kaedah ini terdiri daripada tiga langkah utama:
(1) Pelajari perwakilan tidak linear, dimensi rendah, terurai (iaitu, pengekodan atau pembenaman) HDCD melalui VAE
(2) Menjalankan GWAS secara bebas untuk setiap koordinat yang dikodkan
; (3) Gunakan skor risiko poligenik (PRS) daripada koordinat pengekodan sebagai skor genetik untuk fungsi biologi umum, dan kemudian berpotensi menggabungkan skor ini untuk mencipta PRS untuk penyakit atau sifat tertentu (diberikan sebilangan kecil label penyakit). 
Ilustrasi: tiga langkah REGLE. (Sumber: Kertas)
Mengesan lokus genetik novel untuk paru-paru dan fungsi peredaran darahPara penyelidik menunjukkan kuasa REGLE menggunakan dua modaliti data klinikal berdimensi tinggi: spirometri, yang mengukur fungsi paru-paru, dan spirometri, yang mengukur fungsi kardiovaskular PPG. Kedua-duanya boleh dikumpulkan secara tidak invasif dan agak murah di klinik atau pada peranti boleh pakai pengguna, dan kedua-dua modaliti mempunyai ciri yang terkenal).
Berbanding dengan kajian perkaitan seluruh genom dengan spirometri dan tandatangan PPG dengan dimensi yang sama, kajian REGLE tentang pengekodan yang dipelajari memulihkan majoriti lokus (lokus) genetik yang diketahui yang dikaitkan dengan fungsi paru-paru dan peredaran darah, sambil turut mengesan ke tapak lain (contohnya , tapak penting PPG meningkat sebanyak 45%). Jika tapak ini disahkan dalam analisis lanjut dan eksperimen makmal basah, mereka berpotensi untuk menjadi sasaran dadah baharu.
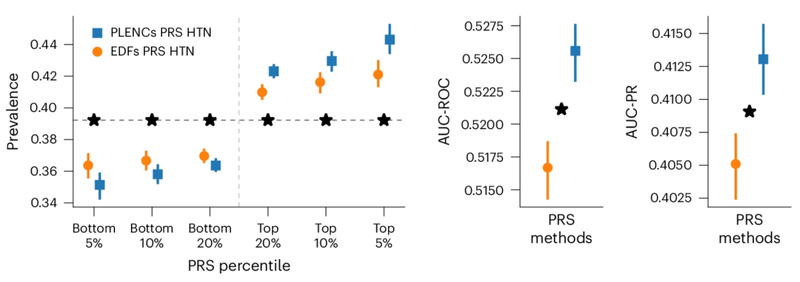
🎜Skor Risiko Genetik Yang Dipertingkatkan🎜🎜Skor risiko poligenik (PRS) ialah ringkasan anggaran kesan banyak varian genetik pada sifat tertentu, dinyatakan sebagai nombor tunggal. PRS yang dicipta oleh kajian persatuan seluruh genom mengenai pembenaman REGLE boleh digabungkan menggunakan hanya beberapa tanda tangan penyakit untuk menjana PRS untuk penyakit tertentu itu. 🎜Les chercheurs ont observé que le PRS de la fonction pulmonaire créé à partir du codage de la spirométrie améliorait la prévision de la BPCO et de l'asthme par rapport aux méthodes existantes telles que les fonctionnalités définies par des experts, l'ACP et le PRS, et surpassait la fonctionnalité PRS aux deux extrémités du spectre de risque. Stratifier les groupes à risque plus efficacement. Améliorations statistiquement significatives de plusieurs mesures (AUC-ROC, AUC-PR et corrélation de Pearson) dans plusieurs ensembles de données indépendants (COPDGene, eMERGE III, Indiana Biobank et EPIC-Norfolk) pour l'asthme et la BPCO, comme suit.

De même, le PRS dérivé de l'intégration REGLE du PPG améliore les prévisions de l'hypertension et de la pression artérielle systolique (PAS). L'hypertension et la SBP PRS générées par le codage PPG et les signatures PPG ont été évaluées dans trois ensembles de données indépendants (COPDGene, eMERGE III et EPIC-Norfolk), ainsi que dans l'ensemble de tests UK Biobank.
Observé que sur plusieurs ensembles de données, il existe une tendance constante à l'amélioration de l'utilisation du PRS à partir du codage PPG par rapport à l'utilisation du PRS à partir de fonctionnalités définies par des experts, à la fois pour l'hypertension et la PAS.

Incorporations partiellement interprétables
Tirant parti des propriétés génératives de REGLE, nous étudions l'effet des coordonnées de codage sur la spirométrie en fixant la valeur des caractéristiques définies par les experts et en modifiant une coordonnée de codage tout en conservant l'autre. Coordonnées d'encodage nulles. Effet de forme. Ensuite, la carte de spirométrie correspondante est générée en utilisant uniquement la partie décodeur du modèle entraîné.
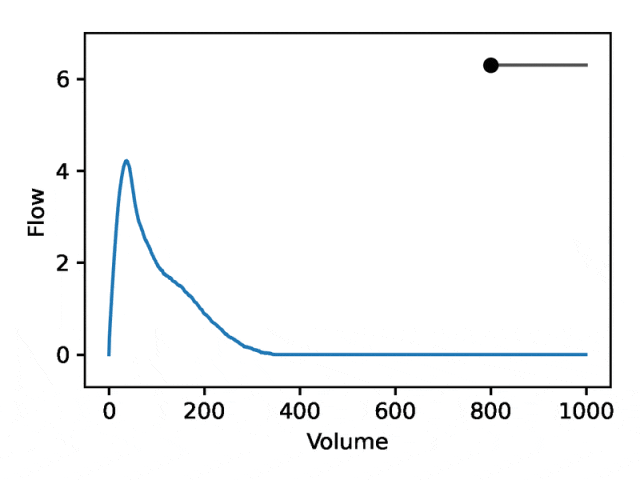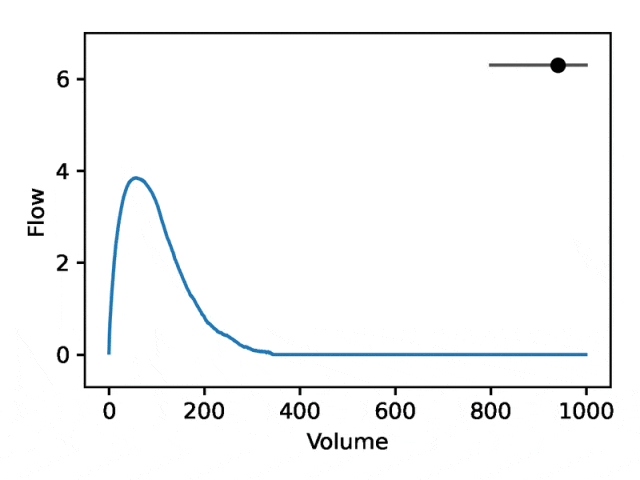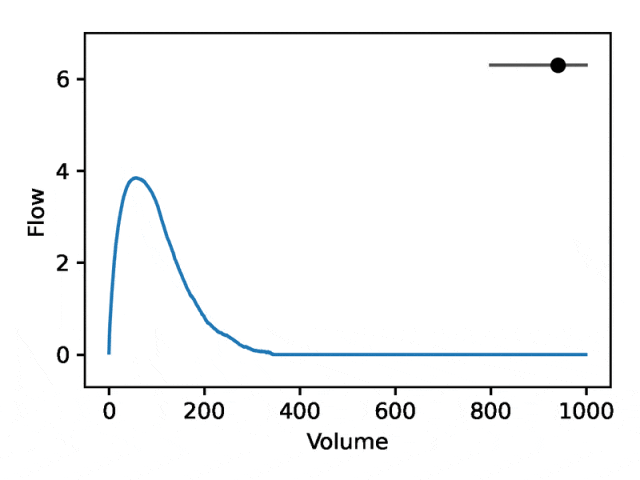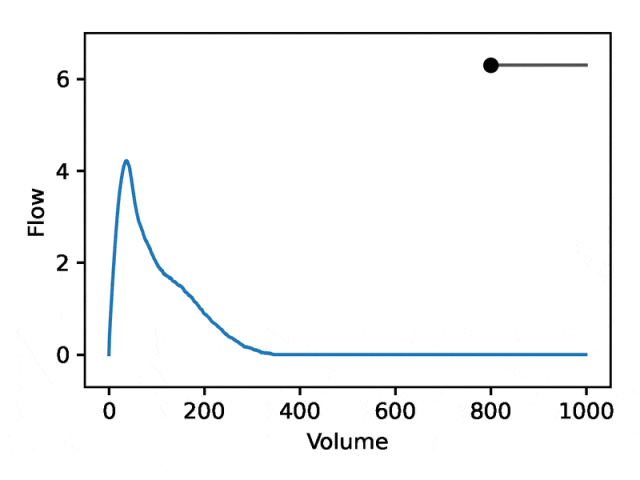
Une spirométrie débit-volume typique se compose de deux parties distinctes : (1) la section relativement courte pour atteindre le débit de pointe, où le débit augmente de façon monotone avec l'augmentation du volume (2) la partie principale de la section de spirométrie, où le débit diminue ; de manière monotone.
L'image ci-dessous montre que changer la première coordonnée équivaut à agrandir ou réduire la deuxième partie (pente négative) tout en gardant la première partie relativement fixe. En fait, la concavité dans la deuxième partie de la courbe, que les pneumologues appellent un creux, est un indicateur d'obstruction des voies respiratoires qui n'est pas bien représentée par l'EDF standard.
Élucider la base génétique des traits et des maladies humaines
REGLE est une méthode d'apprentissage non supervisée qui effectue une analyse génétique, améliore la découverte de nouveaux locus et prédit les risques. Étant donné que les EDF sont difficiles à découvrir manuellement à grande échelle, l’apprentissage non supervisé des représentations HDCD est intéressant pour la découverte du génome.
Le framework REGLE prend également en charge l'utilisation raisonnée de ces fonctionnalités dans la modélisation en modifiant les architectures VAE traditionnelles. REGLE est démontré dans deux modalités de données cliniques (spirométrie et PPG), qui peuvent être mesurées en routine en milieu clinique ou de manière passive et non invasive via des smartphones ou des appareils portables.
REGLE fournit un mécanisme pour identifier les influences génétiques sur la fonction des organes sans données étiquetées et permet l'incorporation de fonctionnalités expertes dans le modèle. Il permet également de créer des PRS spécifiques à une maladie ou à un trait en utilisant peu d'étiquettes. À l’avenir, des approches comme celle-ci seront de plus en plus utilisées pour élucider davantage les bases génétiques des caractéristiques et des maladies humaines.
Contenu de référence : https://research.google/blog/harnessing-hidden-genetic-information-in-clinical-data-with-regle/
Atas ialah kandungan terperinci Dengan kecekapan tinggi dan tidak memerlukan label, pasukan Google menggunakan AI untuk melombong data klinikal, meningkatkan penemuan gen dan ramalan penyakit serta diterbitkan dalam sub-jurnal Nature. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI