
Rumah >Peranti teknologi >AI >Pasukan Jia Jiaya bekerjasama dengan Universiti Cambridge Tsinghua dan lain-lain untuk mempromosikan paradigma penilaian baharu untuk mengesan 'skor tinggi dan tenaga rendah' dalam model besar dalam satu saat
Pasukan Jia Jiaya bekerjasama dengan Universiti Cambridge Tsinghua dan lain-lain untuk mempromosikan paradigma penilaian baharu untuk mengesan 'skor tinggi dan tenaga rendah' dalam model besar dalam satu saat

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-07-19 13:55:25503semak imbas

MR-Ben telah menilai dengan teliti banyak model sumber terbuka dan sumber tertutup barisan pertama dalam dan luar negara, seperti GPT4-Turbo, Cluade3.5-Sonnet, Mistral-Large, Zhipu-GLM4, Moonshot-v1, Yi-Large, Qwen2 -70B , Deepseek-V2, dsb., dan menjalankan analisis terperinci.
Manakah model besar yang kelihatan cantik akan "dialih keluar", dan model manakah yang mempunyai permukaan paling kukuh? Pada masa ini, semua kod dan data kerja ini adalah sumber terbuka, mari kita lihat!
Halaman Projek: https://randolph-zeng.github.io/Mr-Ben.github.io/
Halaman Arxiv: https://arxiv.org/abs/2406.13975
Github Repo: https://github.com /dvlab-research/Mr-Ben
MR-Ben memecahkan "skor tinggi dan tenaga rendah" model besar dalam beberapa saat
Selepas bidang kecerdasan buatan memasuki detik GPT, ahli akademik dan industri bekerjasama, dan model baharu dikeluarkan setiap bulan atau pun setiap minggu.
Model besar muncul tanpa henti. Apakah piawaian yang digunakan untuk mengukur keupayaan khusus model besar? Arah arus perdana semasa ialah menggunakan ujian piawai manusia - soalan aneka pilihan dan mengisi soalan kosong untuk menjalankan penilaian model yang besar. Terdapat banyak faedah menggunakan kaedah ujian ini, yang boleh diringkaskan seperti berikut:
• Ujian piawai mudah diukur dan dinilai, dan piawaiannya jelas, dan apa yang betul adalah apa yang betul dan yang salah adalah salah.
• Penunjuk adalah intuitif, dan mudah untuk membandingkan dan memahami markah yang diperoleh dalam peperiksaan kemasukan kolej domestik atau peperiksaan kemasukan kolej Amerika SAT.
• Keputusan kuantitatif adalah topikal semula jadi (contohnya, keupayaan GPT4 untuk lulus dengan mudah Peperiksaan Pensijilan Bar A.S. sangat menarik perhatian).
Tetapi jika anda mendalami kaedah latihan model besar, anda akan mendapati kaedah rantaian pemikiran langkah demi langkah untuk menjana jawapan akhir ini tidak "dipercayai".
Soalan muncul tepat dalam proses jawapan langkah demi langkah!
Model pra-latihan telah melihat trilion unsur perkataan semasa pra-latihan Sukar untuk mengatakan sama ada model yang dinilai telah melihat data yang sepadan dan boleh menjawab soalan dengan betul dengan "menghafal soalan". Dalam jawapan langkah demi langkah, kami tidak tahu sama ada model memilih pilihan yang betul berdasarkan pemahaman dan penaakulan yang betul, kerana kaedah penilaian bergantung terutamanya pada menyemak jawapan akhir.
Walaupun komuniti akademik terus menaik taraf dan mengubah set data seperti GSM8K dan MMLU, seperti memperkenalkan versi berbilang bahasa set data MGSM pada GSM8K dan memperkenalkan soalan yang lebih sukar berdasarkan MMLU, masih tiada cara untuk menyingkirkan masalah memilih atau mengisi tempat kosong.
Selain itu, set data ini semuanya menghadapi masalah ketepuan yang serius Nilai model bahasa yang besar pada penunjuk ini telah memuncak dan mereka secara beransur-ansur kehilangan perbezaannya.
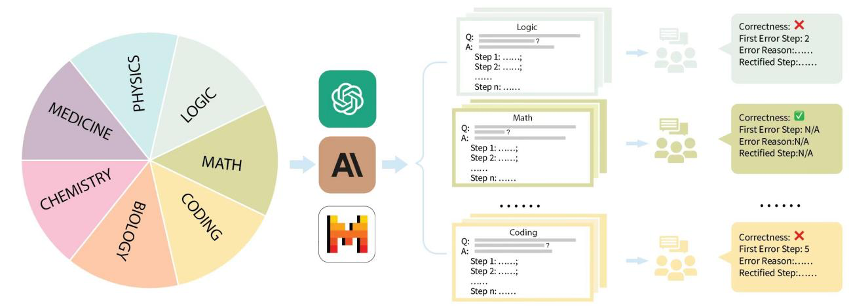
Untuk tujuan ini, pasukan Jiajiaya bekerjasama dengan banyak universiti terkenal seperti MIT, Tsinghua dan Cambridge, dan bekerjasama dengan syarikat anotasi ketua domestik untuk menganotasi set data penilaian MR-Ben untuk proses penaakulan masalah yang kompleks.
MR-Ben telah melakukan transformasi paradigma "penggredan" berdasarkan soalan daripada set data pra-latihan dan ujian model besar seperti GSM8K, MMLU, LogiQA, MHPP dan model besar lain yang dihasilkan sukar, lebih berbeza dan lebih realistik. Ia mencerminkan keupayaan penaakulan model!
Kerja pasukan Jiajiaya kali ini juga membuat penambahbaikan yang disasarkan untuk menangani masalah penilaian yang sedia ada:
Adakah anda tidak takut kebocoran data akan membawa kepada hafalan model berskala besar bagi soalan, mengakibatkan markah meningkat? Tidak perlu mencari semula soalan atau mengubah bentuk soalan untuk menguji keteguhan model MR-Ben secara langsung menukar model daripada identiti pelajar penjawab kepada mod "penggredan" proses jawapan, membolehkan yang besar. model untuk menjadi guru untuk menguji Sejauh manakah ia menguasai mata pengetahuan!
Tidakkah anda bimbang bahawa model itu tidak mempunyai kesedaran tentang proses penyelesaian masalah, dan mungkin mempunyai "ilusi" atau salah faham, dan mendapat jawapan yang salah? MR-Ben secara langsung merekrut sekumpulan pencatat sarjana dan kedoktoran peringkat tinggi untuk menganotasi dengan teliti proses penyelesaian masalah bagi sejumlah besar soalan. Tunjukkan secara terperinci sama ada proses penyelesaian masalah adalah betul, lokasi ralat, dan sebab ralat, dan bandingkan keputusan penggredan model besar dan keputusan penggredan pakar manusia untuk menguji pengetahuan model tentang pengetahuan mata.
Secara khusus, pasukan Jiajiaya menganjurkan set data penilaian arus perdana di pasaran seperti GSM8K, MMLU, LogiQA, MHPP dan set data lain, dan membahagikannya kepada beberapa kategori seperti matematik, fizik, kimia, biologi, kod, logik, perubatan , dsb., dan juga membezakan tahap kesukaran yang berbeza. Untuk setiap kategori dan setiap soalan yang dikumpul, pasukan dengan teliti mengumpul proses penyelesaian masalah langkah demi langkah yang sepadan, dan telah dilatih serta diberi anotasi oleh pakar anotasi sarjana dan kedoktoran profesional.
다음으로, MR-Ben의 작업에 제시된 구체적인 예를 결합하여 최종 답변을 생성하는 단계별 방법과 관련 평가가 왜 신뢰할 수 없는지 살펴보겠습니다.
평가된 "채점" 모델로서 GPT4-Turbo는 두 번째 단계에 숨겨진 계산 오류를 찾지 못했습니다:
E.1 수학
제목: 고등학교 수학
질문: 4로 나누어지는 가장 작은 정수는 무엇입니까? 3으로 나누면 나머지 1, 3으로 나누면 나머지 2, 5로 나누면 나머지 2?
옵션: [A] 67 [B] 43 [C] 57 [D] 37
답변: D
샘플링 모델: Claude2
모델 해결 단계:
- 1단계: 다음과 같은 경우 옵션 A(67)를 확인하세요. 67을 4로 나누면 나머지는 1이 아니라 3이 됩니다. 따라서 67은 정답이 아닙니다.
- 2단계: 옵션 B 확인(43) 43을 4로 나누면 나머지가 1입니다. 43을 3으로 나누면 나머지는 2가 아니라 3이 됩니다. 따라서 43은 정답이 아닙니다.
- 3단계: 옵션 C 확인(57) 57을 4로 나누면 나머지가 1이 됩니다. 57을 3으로 나누면 나머지는 2가 아닌 0이 됩니다. 따라서 57은 정답이 아닙니다.
- 4단계: 옵션 D(37)를 확인하세요. 37을 4로 나누면 나머지가 1이 됩니다. 37을 3으로 나누면 나머지는 1이다. 37을 5로 나누면 나머지는 2입니다.
-
5단계: 옵션 D(37)가 모든 조건을 충족하며 정답입니다.
답변: 옵션 D
인간 주석
모델 답변 정확성: 틀림
첫 번째 잘못된 단계: 2단계
모델 답변 오류 이유:
2단계에서 모델은 43을 4로 나눈 나머지가 1이라고 잘못 계산했습니다. 3개 중. 모델에서는 43을 4로 나누면 나머지가 1이지만 나머지는 3이 되어야 한다고 가정합니다. 여기에 계산 오류가 있습니다.수정 후 첫 번째 올바른 단계: 2단계
43을 4로 나누면 나머지가 1이 됩니다. 43을 3으로 나누면 나머지는 1이다. 43을 5로 나누면 나머지는 2가 아니라 3이 됩니다. 따라서 43은 정답이 아닙니다.
평가 모델: gpt-4-turbo
모델 답변:
-1단계: 67을 4와 3으로 나눈 나머지를 확인하고, 4로 나누고 나머지 3이라는 조건을 충족하는지 확인합니다. 올바른 검증.
- 2단계: 43을 4, 3, 5로 나눈 나머지를 확인하고, 5의 나머지가 조건을 충족하지 않는다는 점을 제외하고 1, 3, 5의 나머지가 예상과 정확히 일치하는지 확인합니다.
-3단계: 단계 57을 4와 3으로 나눈 나머지를 계산하면 나머지는 각각 1과 0입니다. 57을 3으로 나누면 나머지가 기준을 충족하지 않습니다.
-4단계: 37을 4, 3, 5로 나눈 나머지를 확인하고 확인합니다. 예상되는 나머지가 모두 정확하고 37이 문제의 모든 조건을 충족하는 것으로 나타났습니다.풀이 과정이 맞나요? 맞나요
첫 번째 오류 단계: 해당 없음
첫 번째 오류 단계의 이유: 해당 없음
질문이 나오고 해결 과정이 결정되는 것을 보면 알 수 있습니다. , 평가 언어 모델 방식은 모델이 답변 과정을 '표시'하고, 정답인지 오답인지 판단하고, 오류의 위치와 원인을 지적하는 방식으로 변환됩니다. 주석 결과와 비교하여 해결 과정의 정확성과 잠재적인 오류 위치를 계산할 수 있습니다. 모델 오류 단계 및 이유에 대한 평가는 주석자가 제공한 오류 이유에 대한 설명과 모델의 오류 이유에 대한 설명을 비교하여 모델이 올바른지 여부를 판단하기 위해 GPT4에 넘겨질 수 있습니다.
평가 방법 중 MR-Ben이 제안하는 방법은 모델이 문제 해결 과정의 각 단계의 전제, 가정, 논리를 상세하게 분석하고, 추론 과정을 미리 검토하여 올바른지 여부를 판단하는 것입니다. 현재 단계는 올바른 답변으로 이어질 수 있습니다. fenye1. 이 "채점" 평가 방법은 단순히 질문에 대답하는 평가 방법보다 훨씬 어렵지만 모델의 문제 기억으로 인해 발생하는 잘못된 점수 문제를 효과적으로 피할 수 있습니다. 문제만 외울 수 있는 학생이 자격을 갖춘 채점 교사가 되기는 어렵습니다.
- 둘째, MR-Ben은 수동적이고 정밀한 주석 프로세스 제어를 사용하여 다수의 고품질 주석을 달성했으며, 영리한 프로세스 설계를 통해 평가 방법을 직관적으로 정량화할 수 있습니다.
- Jiajiaya 팀은 또한 가장 대표적인 10가지 언어 모델과 다양한 버전을 테스트했습니다. 비공개 소스 대형 언어 모델 중에서 GPT4-Turbo가 가장 좋은 성능을 가지고 있음을 알 수 있습니다(비록 "채점" 중에 계산 오류는 발견되지 않았지만). 대부분의 주제에는 데모(k=1)가 있고 데모는 없습니다. .(k=0)이 다른 모델보다 앞서 있습니다.
**MR-Ben 데이터 세트에 대한 일부 오픈 소스 대형 언어 모델의 평가 결과
가장 강력한 오픈 소스 대형 언어 모델 중 일부의 효과가 일부 상용 모델, 심지어 가장 강력한 폐쇄 소스까지 따라잡았다는 것을 알 수 있습니다 모델은 MR-Ben에 있습니다. Ben 데이터 세트의 성능은 아직 포화되지 않았으며 서로 다른 모델 간의 차이가 큽니다.
또한 MR-Ben의 원본 논문에는 다음과 같은 더 흥미로운 분석과 결과가 있습니다.
Qwen과 Deepseek에서 출시한 오픈 소스 모델은 글로벌 계층에서도 PK 폐쇄 소스 모델보다 열등하지 않습니다.
다양한 비공개 소스 모델의 가격 책정 전략과 실제 성능은 매우 흥미롭습니다. 사용 시나리오의 추론 능력을 고민하는 친구들은 가격과 성능을 기준으로 자신이 선호하는 모델을 찾아 사용할 수 있습니다.
저자원 시나리오에서는 소형 모델에도 많은 특징이 있습니다. MR-Ben 평가에서 Phi-3-mini는 소형 모델 중에서 수백억 개의 매개변수를 가진 대형 모델보다 훨씬 높거나 동일하다는 점을 보여주었습니다. 데이터 중요성을 미세 조정하는 능력.
MR-Ben 장면에는 복잡한 논리적 분석과 단계별 추론이 포함되어 있습니다. Few-shot 모드에서 컨텍스트가 너무 길면 모델이 혼란스러워지고 성능이 저하됩니다.
MR-Ben은 다양한 프롬프트 전략 간의 차이를 확인하기 위해 많은 세대-반사-재생 절제 실험을 평가한 결과 저수준 모델에는 효과가 없으며 GPT4-Turbo와 같은 고수준 모델에는 효과가 없다는 것을 발견했습니다. 분명한. 이에 반해 중급 모델의 경우 잘못된 것은 항상 수정되고, 올바른 것은 수정되기 때문에 효과가 약간 향상된다.
MR-Ben이 평가한 대상을 지식 기반, 논리, 계산, 알고리즘 유형으로 대략 구분한 후, 모델마다 추론 유형에 따라 장단점이 있습니다.
Jiajiaya 팀은 github에 원클릭 평가 방법을 업로드했습니다. 복잡한 추론에 관심이 있는 모든 친구들은 자신의 모델을 평가하고 제출할 수 있습니다. 팀은 적시에 해당 리더보드를 업데이트할 것입니다.
그나저나 공식 스크립트를 사용한 원클릭 평가 비용은 약 1200만 토큰에 불과하므로 프로세스가 매우 원활하므로 시도해 보세요!
Reference
수학 단어 문제를 해결하기 위한 검증기 교육(https://arxiv.org/abs/2110.14168)
대규모 멀티태스킹 언어 이해 측정(https://arxiv.org/abs/2009.03300)
LogiQA: 도전 논리적 추론을 통한 기계 독해를 위한 데이터 세트(https://arxiv.org/abs/2007.08124)
MHPP: 기본 코드 생성을 넘어서는 언어 모델의 기능 및 한계 탐색(https://arxiv.org/abs/2405.11430)
인공 일반 지능의 불꽃: GPT-4를 사용한 초기 실험(https://arxiv.org/abs/2303.12712)
Qwen 기술 보고서(https://arxiv.org/abs/2309.16609)
DeepSeek-V2: A Strong, 경제적이고 효율적인 전문가 혼합 언어 모델(https://arxiv.org/abs/2405.04434)
교과서만 있으면 됩니다(https://arxiv.org/abs/2306.11644)
대형 언어 모델은 스스로 학습할 수 없습니다. 올바른 추론(https://arxiv.org/abs/2310.01798)
Atas ialah kandungan terperinci Pasukan Jia Jiaya bekerjasama dengan Universiti Cambridge Tsinghua dan lain-lain untuk mempromosikan paradigma penilaian baharu untuk mengesan 'skor tinggi dan tenaga rendah' dalam model besar dalam satu saat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Semua yang anda perlu tahu tentang pengguna ChatGPT-4
- Ciptaan 3D sebenar ada di sini, anda mesti menggunakan tangan anda untuk memberi isyarat! AI tidak boleh mengambil kerja saya kali ini, bukan?
- Versi Google ChatGPT tiba-tiba dilancarkan ke dalam beta awam! Keputusan ujian sebenar di sini Permohonan untuk pengalaman diluluskan dengan cepat.
- Untuk melawan ChatGPT, Google melancarkan versi beta Bard