
Rumah >Peranti teknologi >AI >Meninggalkan pengekod visual, model besar berbilang mod 'versi asli' ini juga setanding dengan kaedah arus perdana
Meninggalkan pengekod visual, model besar berbilang mod 'versi asli' ini juga setanding dengan kaedah arus perdana

- WBOYasal
- 2024-07-18 19:21:11371semak imbas

Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Yizuo Diao Haiwen ialah pelajar kedoktoran di Universiti Teknologi Dalian, dan penyelianya ialah Profesor Lu Huchuan. Sedang berkhidmat di Institut Penyelidikan Kepintaran Buatan Beijing Zhiyuan, pengajarnya ialah Dr. Wang Xinlong. Minat penyelidikannya ialah visi dan bahasa, pemindahan model besar yang cekap, model besar berbilang modal, dsb. Pengarang bersama pertama Cui Yufeng lulus dari Universiti Beihang dan merupakan penyelidik algoritma di Pusat Penglihatan Institut Penyelidikan Kepintaran Buatan Zhiyuan Beijing. Minat penyelidikannya ialah model multimodal, model generatif, dan visi komputer, dan kerja utamanya adalah dalam siri Emu.
Baru-baru ini, penyelidikan mengenai model besar berbilang modal sedang giat dijalankan, dan industri telah melabur lebih banyak lagi dalam hal ini. Model hangat telah dilancarkan di luar negara, seperti GPT-4o (OpenAI), Gemini (Google), Phi-3V (Microsoft), Claude-3V (Anthropic), dan Grok-1.5V (xAI). Pada masa yang sama, domestik GLM-4V (Wisdom Spectrum AI), Step-1.5V (Step Star), Emu2 (Beijing Zhiyuan), Intern-VL (Shanghai AI Laboratory), Qwen-VL (Alibaba), dll. Model berkembang .
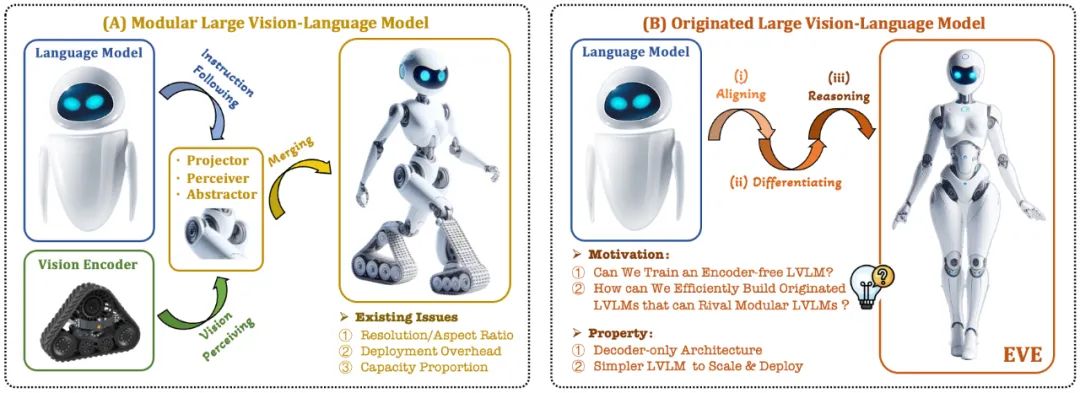
Model bahasa visual (VLM) semasa biasanya bergantung pada pengekod visual (Vision Encoder, VE) untuk mengekstrak ciri visual, dan kemudian menggabungkan arahan pengguna dengan model bahasa besar (LLM) untuk memproses dan menjawab dalam pengekod visual dan pemisahan Latihan untuk model bahasa yang besar. Pemisahan ini menyebabkan pengekod visual memperkenalkan isu bias induksi visual apabila antara muka dengan model bahasa yang besar, seperti peleraian imej dan nisbah bidang yang terhad, serta semantik visual yang kuat. Memandangkan kapasiti pengekod visual terus berkembang, kecekapan penggunaan model besar berbilang mod dalam memproses isyarat visual juga amat terhad. Di samping itu, cara mencari konfigurasi kapasiti optimum pengekod visual dan model bahasa besar telah menjadi semakin kompleks dan mencabar.
Dalam konteks ini, beberapa idea yang lebih canggih muncul dengan cepat:
Bolehkah kita mengalih keluar pengekod visual, iaitu membina secara langsung model besar berbilang mod asli tanpa pengekod visual?
Bagaimana untuk mengembangkan model bahasa besar dengan cekap dan lancar menjadi model besar berbilang modal asli tanpa pengekod visual?
Bagaimana untuk merapatkan jurang prestasi antara rangka kerja berbilang modal asli tanpa pengekod dan paradigma berbilang modal berasaskan pengekod arus perdana?
Adept AI mengeluarkan model siri Fuyu pada penghujung tahun 2023 dan membuat beberapa percubaan berkaitan, tetapi tidak mendedahkan sebarang strategi latihan, sumber data dan maklumat peralatan. Pada masa yang sama, terdapat jurang prestasi yang ketara antara model Fuyu dan algoritma arus perdana dalam penunjuk penilaian teks visual awam. Dalam tempoh yang sama, beberapa percubaan rintis yang kami jalankan menunjukkan bahawa walaupun skala data pra-latihan ditingkatkan secara besar-besaran, model besar multi-modal asli tanpa pengekod masih menghadapi masalah yang sukar seperti kelajuan penumpuan yang perlahan dan prestasi yang lemah.
Sebagai tindak balas kepada cabaran ini, pasukan visi Institut Penyelidikan Zhiyuan, bersama-sama Universiti Teknologi Dalian, Universiti Peking dan universiti domestik lain, melancarkan generasi baharu model bahasa visual tanpa pengekod EVE. Melalui strategi latihan yang diperhalusi dan penyeliaan visual tambahan, EVE menyepadukan perwakilan visual-linguistik, penjajaran dan inferens ke dalam seni bina penyahkod tulen bersatu. Menggunakan data yang tersedia secara umum, EVE berprestasi baik pada berbilang penanda aras visual-linguistik, bersaing dengan kaedah multimodal berasaskan pengekod arus perdana dengan kapasiti yang sama dan dengan ketara mengatasi prestasi rakan Fuyu-8B. EVE dicadangkan untuk menyediakan laluan yang telus dan cekap untuk pembangunan seni bina berbilang modal asli untuk penyahkod tulen.


Alamat kertas: https://arxiv.org/abs/2406.11832
Kod projek: https://github.com/baaivision ://huggingface.co/BAAI/EVE-7B-HD-v1.0
- 1
Model bahasa visual asli: memecahkan paradigma tetap model berbilang modal arus perdana, mengalih keluar pengekod visual dan boleh mengendalikan sebarang nisbah aspek imej. Ia dengan ketara mengatasi jenis model Fuyu-8B yang sama dalam pelbagai tanda aras bahasa visual dan hampir dengan seni bina bahasa visual berasaskan pengekod visual arus perdana.
Data rendah dan kos latihan: Pra-latihan model EVE hanya menyaring data awam daripada OpenImages, SAM dan LAION, dan menggunakan 665,000 data arahan LLaVA dan tambahan 1.2 juta data dialog visual untuk membina masing-masing Regular dan high- versi resolusi EVE-7B. Latihan mengambil masa kira-kira 9 hari untuk diselesaikan pada dua nod 8-A100 (40G), atau kira-kira 5 hari pada empat nod 8-A100.
Penjelajahan yang telus dan cekap: EVE cuba meneroka laluan yang cekap, telus dan praktikal ke model bahasa visual asli, memberikan idea baharu dan pengalaman berharga untuk pembangunan seni bina model bahasa visual penyahkod tulen generasi baharu model multimodal masa hadapan membuka arah penerokaan baharu.
- 2.2 Patch Aligning Layer
- Record bentuk 2D patch yang sah; Modul (CA3), menyepadukan ciri visual rangkaian berbilang lapisan untuk mencapai penjajaran halus dengan output pengekod visual. 3. Strategi latihan ;
-
Fasa pra-latihan generatif: meningkatkan lagi keupayaan model untuk memahami kandungan visual-linguistik dan mencapai peralihan yang lancar daripada model bahasa tulen kepada model berbilang modal
Fasa penalaan halus: selanjutnya menyeragamkan model untuk mengikut arahan bahasa dan kebolehan mempelajari corak perbualan yang memenuhi keperluan pelbagai tanda aras bahasa visual.
Dalam peringkat pra-latihan, 33 juta data awam daripada SA-1B, OpenImages dan LAION telah ditapis, dan hanya sampel imej dengan resolusi lebih tinggi daripada 448×448 dikekalkan. Khususnya, untuk menangani masalah redundansi yang tinggi dalam imej LAION, 50,000 kluster telah dihasilkan dengan menggunakan k-means clustering pada ciri imej yang diekstrak oleh EVA-CLIP, dan 300 imej yang paling hampir dengan setiap pusat kluster telah dipilih, dan akhirnya memilih 15 juta sampel imej LAION. Selepas itu, perihalan imej berkualiti tinggi telah dijana semula menggunakan Emu2 (17B) dan LLaVA-1.5 (13B).
Dalam peringkat penalaan halus diselia, gunakan set data penalaan halus LLaVA-mix-665K untuk melatih versi standard EVE-7B, dan menyepadukan data bercampur seperti AI2D, Synthdog, DVQA, ChartQA, DocVQA, Vision-Flan dan Bunny-695K Ditetapkan untuk berlatih untuk mendapatkan versi resolusi tinggi EVE-7B. Peningkatan prestasi selanjutnya: Eksperimen mendapati bahawa pra-latihan hanya menggunakan data visual-linguistik telah mengurangkan keupayaan bahasa model dengan ketara (skor SQA menurun daripada 65.3% kepada 63.0%), tetapi prestasi multi-modal model itu bertambah baik secara beransur-ansur. Ini menunjukkan bahawa terdapat bencana dalaman yang melupakan pengetahuan bahasa apabila model bahasa besar dikemas kini. Adalah disyorkan untuk menyepadukan data pra-latihan bahasa tulen dengan sewajarnya atau menggunakan gabungan strategi pakar (KPM) untuk mengurangkan gangguan antara modaliti visual dan bahasa.
Imaginasi seni bina tanpa pengekod: Dengan strategi dan latihan yang sesuai dengan data berkualiti tinggi, model bahasa visual tanpa pengekod boleh menandingi model dengan pengekod. Jadi di bawah kapasiti model yang sama dan data latihan besar-besaran, apakah prestasi kedua-duanya? Kami membuat spekulasi bahawa dengan mengembangkan kapasiti model dan jumlah data latihan, seni bina tanpa pengekod boleh mencapai atau bahkan mengatasi seni bina berasaskan pengekod, kerana yang pertama memasukkan imej hampir tanpa kehilangan dan mengelakkan bias apriori pengekod visual.
Pembinaan model berbilang modal asli: EVE menunjukkan sepenuhnya cara membina model berbilang modal asli dengan cekap dan stabil, yang membuka ketelusan untuk penyepaduan seterusnya lebih banyak modaliti (seperti audio, video, pengimejan terma, kedalaman, dll) dan laluan praktikal. Idea teras adalah untuk menyelaraskan modaliti ini melalui model bahasa besar yang beku sebelum memperkenalkan latihan bersatu berskala besar, dan menggunakan pengekod mod tunggal yang sepadan dan penjajaran konsep bahasa untuk penyeliaan.
2. Struktur model
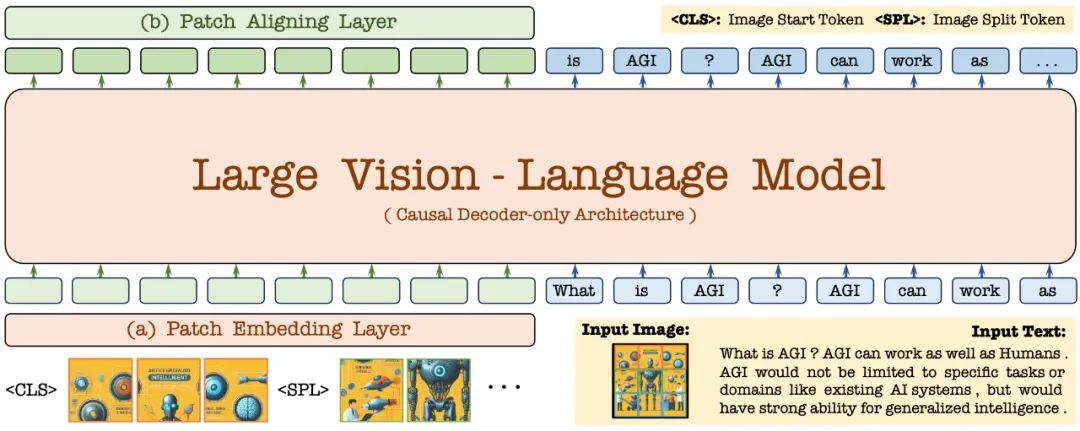
Pertama, ia dimulakan melalui model bahasa Vicuna-7B, supaya ia mempunyai pengetahuan bahasa yang kaya dan keupayaan mengikuti arahan yang berkuasa. Atas dasar ini, pengekod visual dalam dialih keluar, lapisan pengekodan visual ringan dibina, input imej dikodkan dengan cekap dan tanpa kehilangan, dan input ke dalam penyahkod bersatu bersama-sama dengan arahan bahasa pengguna. Selain itu, lapisan penjajaran visual melakukan penjajaran ciri dengan pengekod visual umum untuk meningkatkan pengekodan dan perwakilan maklumat visual yang terperinci. . Berinteraksi dalam medan penerimaan terhad untuk mempertingkatkan ciri tempatan setiap tampung;
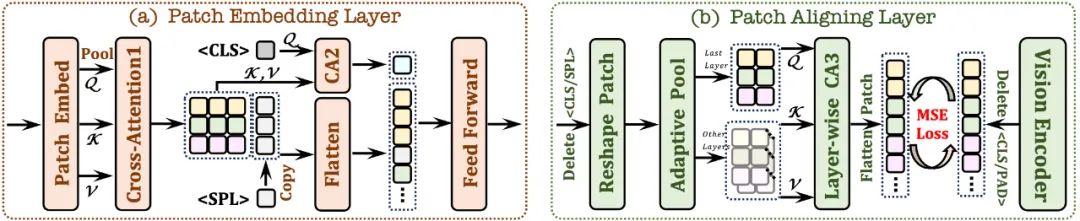
token dan digabungkan dengan modul perhatian silang (CA2) untuk menyediakan maklumat global bagi setiap ciri tampung yang berikutnya; Token
yang boleh dipelajari disisipkan pada penghujung baris untuk membantu rangkaian memahami struktur spatial dua dimensi imej.Model EVE dengan ketara mengatasi model Fuyu-8B yang serupa dalam pelbagai penanda aras bahasa visual, dan berprestasi setanding dengan pelbagai model bahasa visual berasaskan pengekod arus perdana. Walau bagaimanapun, disebabkan penggunaan sejumlah besar data bahasa visual untuk latihan, terdapat cabaran dalam bertindak balas dengan tepat kepada arahan tertentu, dan prestasinya dalam beberapa ujian penanda aras perlu dipertingkatkan. Apa yang menarik ialah melalui strategi latihan yang cekap, EVE tanpa pengekod boleh mencapai prestasi yang setanding dengan model bahasa visual berasaskan pengekod, secara asasnya menyelesaikan masalah fleksibiliti saiz input, kecekapan penggunaan dan modaliti model padanan kapasiti.
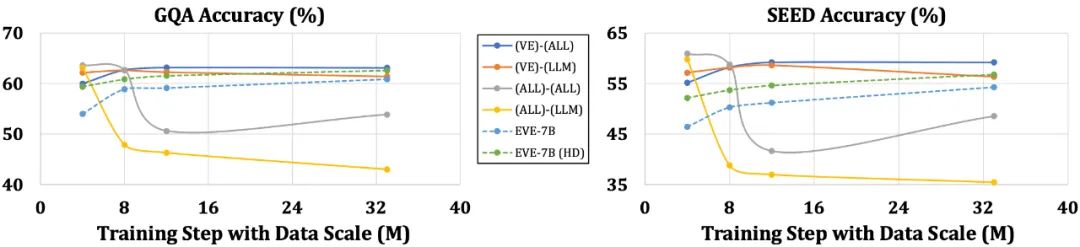
Berbanding dengan model dengan pengekod, yang terdedah kepada masalah seperti penyederhanaan struktur bahasa dan kehilangan pengetahuan yang kaya, EVE telah menunjukkan peningkatan secara beransur-ansur dan stabil dalam prestasi apabila saiz data meningkat, secara beransur-ansur menghampiri prestasi pengekod tahap model berasaskan. Ini mungkin kerana pengekodan dan penjajaran modaliti visual dan bahasa dalam rangkaian bersatu adalah lebih mencabar, menjadikan model bebas pengekod kurang terdedah kepada overfitting berbanding model dengan pengekod.
5. Apakah pendapat rakan sebaya anda?
Ali Hatamizadeh, penyelidik kanan di NVIDIA, berkata bahawa EVE menyegarkan dan cuba mencadangkan naratif baharu, yang berbeza daripada pembinaan standard penilaian yang kompleks dan penambahbaikan model bahasa visual yang progresif.

Armand Joulin, penyelidik utama di Google Deepmind, berkata adalah menarik untuk membina model bahasa visual penyahkod tulen.

Jurutera pembelajaran mesin Apple Prince Canuma berkata bahawa seni bina EVE sangat menarik dan merupakan tambahan yang baik kepada set projek MLX VLM.

6 Tinjauan Masa Depan
Sebagai model bahasa visual asli tanpa pengekod, EVE kini telah mencapai hasil yang menggalakkan. Di sepanjang laluan ini, terdapat beberapa arah menarik yang patut diterokai pada masa hadapan:
Atas ialah kandungan terperinci Meninggalkan pengekod visual, model besar berbilang mod 'versi asli' ini juga setanding dengan kaedah arus perdana. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI