Model bahasa besar (LLM) semakin banyak digunakan dalam pelbagai bidang. Walau bagaimanapun, proses penjanaan teks mereka mahal dan lambat. Ketidakcekapan ini dikaitkan dengan algoritma penyahkodan autoregresif: penjanaan setiap perkataan (token) memerlukan pas ke hadapan, memerlukan akses kepada LLM dengan berbilion hingga ratusan bilion parameter. Ini menyebabkan penyahkodan autoregresif tradisional menjadi lebih perlahan. Baru-baru ini, Universiti Waterloo, Institut Vektor Kanada, Universiti Peking dan institusi lain bersama-sama mengeluarkan EAGLE, yang bertujuan untuk meningkatkan kelajuan inferens model bahasa besar sambil memastikan pengedaran teks output model yang konsisten. Kaedah ini mengekstrapolasi vektor ciri peringkat atas kedua LLM, yang boleh meningkatkan kecekapan penjanaan dengan ketara. 
- Laporan teknikal: https://sites.google.com/view/eagle-llm
-
Kod (menyokong Apache komersial 2.0): https://github.com/SafeAILab/EAGLE
EAGLE mempunyai ciri-ciri berikut:
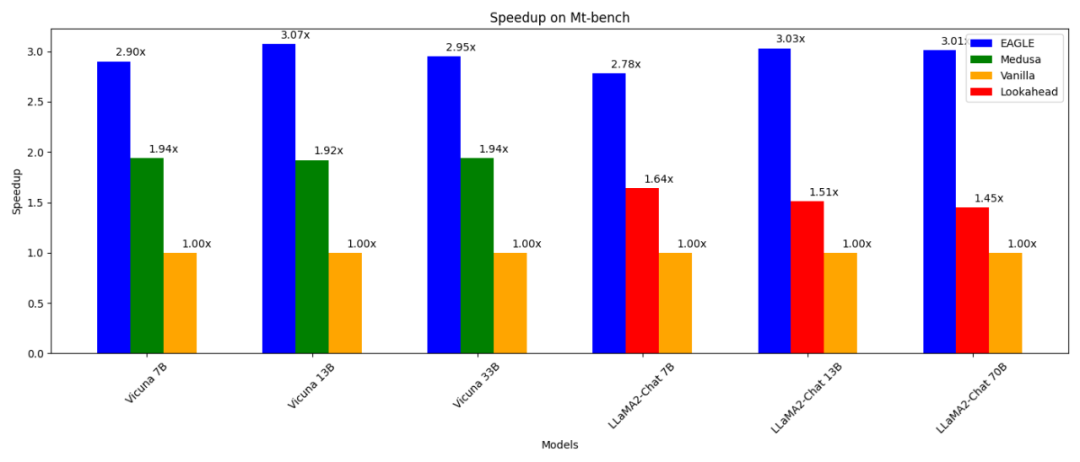
- 3 kali lebih pantas daripada penyahkodan autoregresif biasa (13B); daripada Medusa Decode (13B) 1.6 kali lebih cepat; boleh Gunakan bersama-sama dengan teknologi selari lain seperti vLLM, DeepSpeed, Mamba, FlashAttention, kuantisasi dan pengoptimuman perkakasan.
-
Salah satu cara untuk mempercepatkan penyahkodan autoregresif ialah pensampelan spekulatif. Teknik ini menggunakan model draf yang lebih kecil untuk meneka berbilang perkataan seterusnya melalui penjanaan autoregresif standard. LLM asal kemudiannya mengesahkan perkataan tekaan ini secara selari (memerlukan hanya satu pas ke hadapan untuk pengesahan). Jika model draf meramalkan perkataan α dengan tepat, satu laluan ke hadapan bagi LLM asal boleh menjana perkataan α+1.
Dalam persampelan spekulatif, tugas model draf adalah untuk meramal perkataan seterusnya berdasarkan urutan perkataan semasa. Menyelesaikan tugas ini menggunakan model dengan bilangan parameter yang jauh lebih kecil adalah amat mencabar dan selalunya menghasilkan hasil yang tidak optimum. Tambahan pula, model draf dalam pendekatan pensampelan spekulatif standard secara bebas meramalkan perkataan seterusnya tanpa memanfaatkan maklumat semantik kaya yang diekstrak oleh LLM asal, mengakibatkan potensi ketidakcekapan.
Keterbatasan ini memberi inspirasi kepada perkembangan EAGLE. EAGLE menggunakan ciri kontekstual yang diekstrak oleh LLM asal (iaitu, output vektor ciri oleh lapisan atas kedua model). EAGLE dibina berdasarkan prinsip pertama berikut:
Jujukan vektor ciri boleh dimampatkan, jadi lebih mudah untuk meramalkan vektor ciri berikutnya berdasarkan vektor ciri sebelumnya. EAGLE melatih pemalam ringan yang dipanggil Auto-regresi Head yang, bersama-sama dengan lapisan pembenaman perkataan, meramalkan ciri seterusnya daripada lapisan atas kedua model asal berdasarkan jujukan ciri semasa. Kepala pengelasan beku LLM asal kemudiannya digunakan untuk meramalkan perkataan seterusnya. Ciri mengandungi lebih banyak maklumat daripada urutan perkataan, menjadikan tugas mengundurkan ciri lebih mudah daripada tugas meramal perkataan. Secara ringkasnya, EAGLE mengekstrapolasi pada tahap ciri, menggunakan kepala autoregresif kecil, dan kemudian menggunakan kepala pengelasan beku untuk menjana urutan perkataan yang diramalkan. Selaras dengan kerja yang serupa seperti Persampelan Spekulatif, Medusa dan Lookahead, EAGLE memfokuskan pada kependaman inferens per-kiu dan bukannya keseluruhan pemprosesan sistem.
EAGLE - kaedah untuk meningkatkan kecekapan penjanaan model bahasa besar
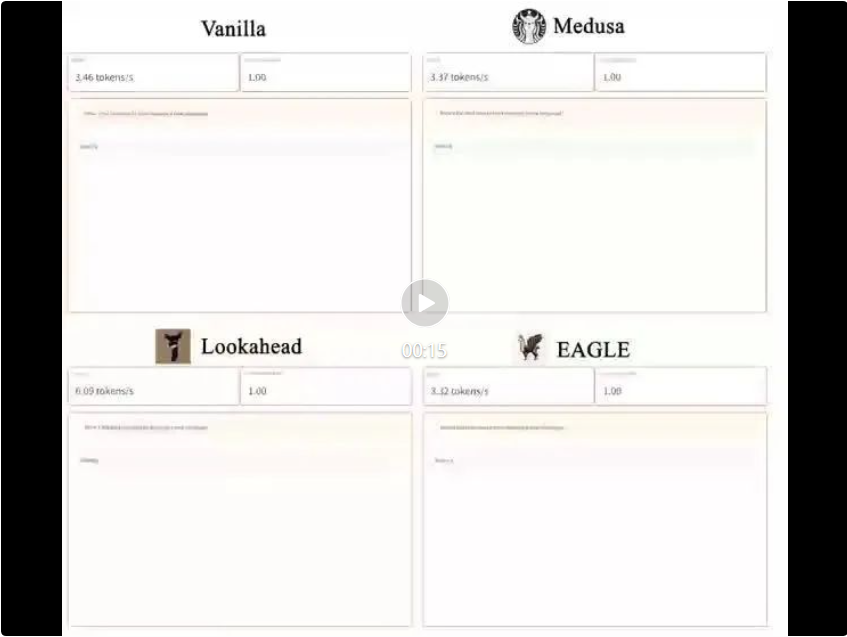
Angka di atas menunjukkan perbezaan dalam input dan output antara EAGLE dan pensampelan spekulatif standard, Medusa dan Lookahead. Rajah di bawah menunjukkan aliran kerja EAGLE. Dalam hantaran hadapan LLM asal, EAGLE mengumpul ciri dari lapisan atas kedua. Ketua autoregresif mengambil ciri ini dan penyusunan perkataan perkataan yang dijana sebelum ini sebagai input dan mula meneka perkataan seterusnya. Selepas itu, kepala pengelasan beku (LM Head) digunakan untuk menentukan taburan perkataan seterusnya, membolehkan EAGLE membuat sampel daripada taburan ini. Dengan mengulangi pensampelan beberapa kali, EAGLE melakukan proses penjanaan seperti pokok, seperti yang ditunjukkan di sebelah kanan rajah di bawah. Dalam contoh ini, hantaran hadapan tiga kali ganda EAGLE "meneka" pokok 10 perkataan.
EAGLE menggunakan kepala autoregresif ringan untuk meramalkan ciri LLM asal. Untuk memastikan ketekalan pengedaran teks yang dijana, EAGLE kemudiannya mengesahkan struktur pokok yang diramalkan. Proses pengesahan ini boleh diselesaikan menggunakan pas hadapan. Melalui kitaran ramalan dan pengesahan ini, EAGLE dapat menjana perkataan teks dengan cepat. Kos melatih kepala autoregresif adalah sangat kecil. EAGLE dilatih menggunakan set data ShareGPT, yang mengandungi kurang daripada 70,000 pusingan dialog. Bilangan parameter boleh dilatih bagi kepala autoregresif juga sangat kecil. Seperti yang ditunjukkan dalam warna biru dalam imej di atas, kebanyakan komponen dibekukan. Satu-satunya latihan tambahan yang diperlukan ialah kepala autoregresif, iaitu struktur Transformer satu lapisan dengan parameter 0.24B-0.99B. Ketua autoregresif boleh dilatih walaupun sumber GPU adalah terhad. Contohnya, regresi autoregresif Vicuna 33B boleh dilatih dalam 24 jam pada pelayan RTX 3090 8 kad. Mengapa menggunakan pembenaman perkataan untuk meramalkan ciri? Medusa hanya menggunakan ciri lapisan atas kedua untuk meramalkan perkataan seterusnya, perkataan seterusnya... Tidak seperti Medusa, EAGLE juga secara dinamik menggunakan pembenaman perkataan yang dijadikan sampel sebagai bahagian input kepala autoregresif untuk membuat ramalan. Maklumat tambahan ini membantu EAGLE mengendalikan rawak yang tidak dapat dielakkan dalam proses pensampelan. Pertimbangkan contoh dalam imej di bawah, dengan mengandaikan perkataan gesaan ialah "I". LLM memberikan kebarangkalian bahawa "Saya" diikuti dengan "am" atau "selalu". Medusa tidak mempertimbangkan sama ada "am" atau "sentiasa" dijadikan sampel, dan secara langsung meramalkan kebarangkalian perkataan seterusnya di bawah "I". Oleh itu, matlamat Medusa adalah untuk meramalkan perkataan seterusnya untuk "Saya" atau "Saya sentiasa" diberikan hanya "Saya". Disebabkan sifat rawak proses pensampelan, input yang sama "I" kepada Medusa mungkin mempunyai perkataan seterusnya yang berbeza keluaran "sedia" atau "mula", mengakibatkan kekurangan pemetaan yang konsisten antara input dan output. Sebaliknya, input kepada EAGLE termasuk pemasukan perkataan hasil sampel, memastikan pemetaan yang konsisten antara input dan output. Perbezaan ini membolehkan EAGLE meramalkan perkataan seterusnya dengan lebih tepat dengan mengambil kira konteks yang ditetapkan oleh proses pensampelan.
Struktur penjanaan seperti pokokBerbeza daripada rangka kerja pengesahan tekaan lain seperti pensampelan spekulatif, Lookahead dan Medusa, EAGLE mengguna pakai struktur perkataan seperti "generasi tekaan" seperti pokok mencapai kecekapan penyahkodan yang lebih Tinggi. Seperti yang ditunjukkan dalam rajah, proses penjanaan persampelan spekulatif standard dan Lookahead adalah linear atau berantai. Memandangkan konteks tidak boleh dibina semasa peringkat meneka, kaedah Medusa menjana pokok melalui produk Cartesian, menghasilkan graf bersambung sepenuhnya antara lapisan bersebelahan. Pendekatan ini selalunya menghasilkan kombinasi yang tidak bermakna, seperti "Saya mula." Sebaliknya, EAGLE mencipta struktur pokok yang lebih jarang. Struktur pokok yang jarang ini menghalang pembentukan urutan yang tidak bermakna dan memfokuskan sumber pengkomputeran pada kombinasi perkataan yang lebih munasabah.
Pelbagai pusingan pensampelan spekulatifKaedah pensampelan spekulatif standard mengekalkan ketekalan pengedaran semasa proses "meneka perkataan". Untuk menyesuaikan diri dengan senario teka perkataan seperti pokok, EAGLE memanjangkan kaedah ini ke dalam bentuk rekursif berbilang pusingan. Pseudokod untuk berbilang pusingan pensampelan spekulatif dibentangkan di bawah. Semasa proses penjanaan pokok, EAGLE merekodkan kebarangkalian yang sepadan dengan setiap perkataan sampel. Melalui berbilang pusingan persampelan spekulatif, EAGLE memastikan bahawa pengedaran akhir yang dijana setiap perkataan adalah konsisten dengan LLM asal.
下圖展示了 EAGLE 在 Vicuna 33B 上關於不同任務中的加速效果。涉及大量固定模板的 「程式設計」(coding)任務顯示出最佳的加速效能。
歡迎大家體驗 EAGLE,並透過 GitHub issue 回饋建議:https://github.com/SafeAILab/EAGLE/issuesAtas ialah kandungan terperinci Kecekapan inferens model besar telah dipertingkatkan sebanyak 3 kali tanpa kerugian, dan Universiti Waterloo, Universiti Peking dan institusi lain mengeluarkan EAGLE. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn



 Jujukan vektor ciri boleh dimampatkan, jadi lebih mudah untuk meramalkan vektor ciri berikutnya berdasarkan vektor ciri sebelumnya.
Jujukan vektor ciri boleh dimampatkan, jadi lebih mudah untuk meramalkan vektor ciri berikutnya berdasarkan vektor ciri sebelumnya. 



