
Rumah >Peranti teknologi >AI >Pasukan perisikan Universiti Peking mencadangkan navigasi dipacu permintaan untuk menyelaraskan keperluan manusia dan menjadikan robot lebih cekap
Pasukan perisikan Universiti Peking mencadangkan navigasi dipacu permintaan untuk menyelaraskan keperluan manusia dan menjadikan robot lebih cekap

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-07-16 11:27:391169semak imbas
Bayangkan jika robot dapat memahami keperluan anda dan bekerja keras untuk memenuhinya, bukankah itu bagus?
Jika anda mahu robot membantu anda, anda biasanya perlu memberikan arahan yang lebih tepat, tetapi pelaksanaan sebenar arahan itu mungkin tidak sesuai. Jika kita mempertimbangkan persekitaran sebenar, apabila robot diminta untuk mencari item tertentu, item itu mungkin sebenarnya tidak wujud dalam persekitaran semasa, dan robot tidak dapat mencarinya tetapi adakah mungkin terdapat item lain dalam persekitaran, yang manakah berkaitan dengan pengguna? Adakah item yang diminta mempunyai fungsi yang serupa dan juga boleh memenuhi keperluan pengguna? Ini adalah faedah menggunakan "keperluan" sebagai arahan tugas.
Baru-baru ini, pasukan Universiti Peking Dong Hao mencadangkan tugas navigasi baharu - Navigasi dipacu Permintaan (DDN), telah diterima oleh NeurIPS 2023. Dalam tugasan ini, robot dikehendaki mencari barangan yang memenuhi keperluan pengguna berdasarkan arahan permintaan yang diberikan oleh pengguna. Pada masa yang sama, pasukan Dong Hao juga mencadangkan pembelajaran ciri-ciri atribut item berdasarkan arahan permintaan, yang secara berkesan meningkatkan kadar kejayaan robot dalam mencari item.

Alamat kertas: https://arxiv.org/pdf/2309.08138.pdf
Laman utama projek: https://sites.google.com/view/demand-driven-navigation/home


Pengguna hanya perlu memberi arahan mengikut keperluan mereka sendiri, tanpa mengambil kira apa yang ada di tempat kejadian.

- Keperluan yang diterangkan dalam bahasa semula jadi mempunyai ruang penerangan yang lebih besar dan boleh mengemukakan keperluan yang lebih tepat dan tepat.
- Untuk melatih robot seperti itu, adalah perlu untuk mewujudkan hubungan pemetaan antara arahan permintaan dan item supaya persekitaran boleh memberi isyarat latihan. Untuk mengurangkan kos, pasukan Dong Hao mencadangkan kaedah penjanaan "separa automatik" berdasarkan model bahasa yang besar: mula-mula gunakan GPT-3.5 untuk menjana keperluan yang boleh dipenuhi oleh item yang sedia ada di tempat kejadian, dan kemudian menapisnya secara manual. yang tidak memenuhi syarat. Reka bentuk algoritma
-
Memandangkan item yang boleh memenuhi keperluan yang sama mempunyai atribut yang sama, jika ciri-ciri atribut item tersebut boleh dipelajari, robot nampaknya boleh menggunakan ciri-ciri atribut ini untuk mencari item. Sebagai contoh, untuk keperluan "Saya dahaga", item yang diperlukan harus mempunyai atribut "menghilangkan dahaga", dan "jus" dan "teh" kedua-duanya mempunyai atribut ini. Apa yang perlu diperhatikan di sini ialah item mungkin mempamerkan atribut yang berbeza di bawah keperluan yang berbeza Contohnya, "air" boleh mempamerkan kedua-dua atribut "membersihkan pakaian" (di bawah keperluan "mencuci pakaian") dan Mendedahkan sifat ". menghilangkan dahaga" (di bawah keperluan "Saya dahaga").
Peringkat pembelajaran atribut
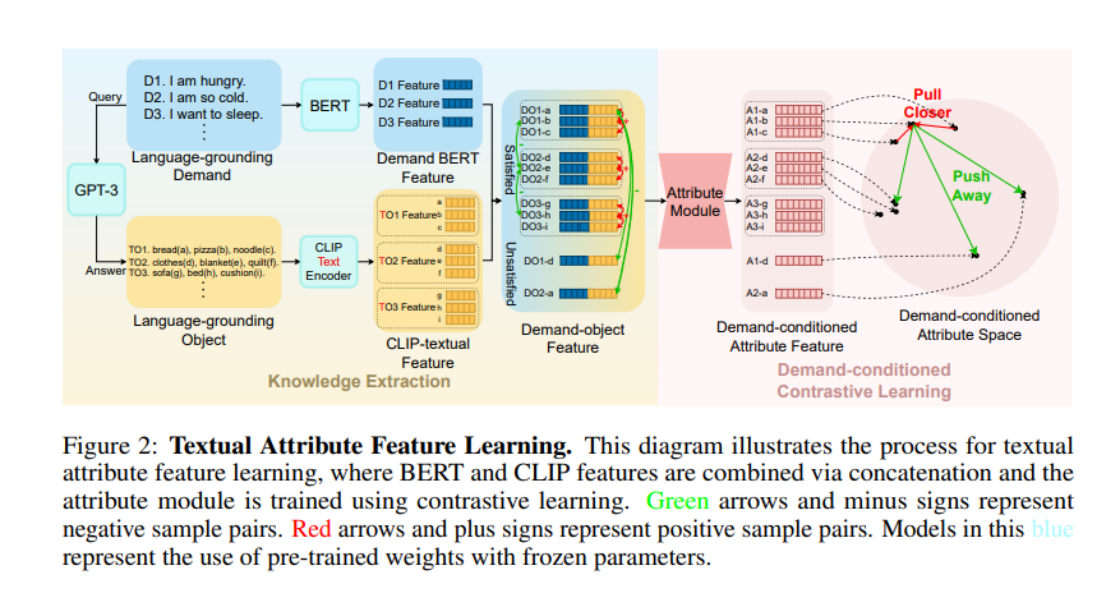
Jadi, bagaimana untuk membuat model memahami keperluan "menghilangkan dahaga" dan "membersihkan pakaian"? Ia adalah akal fikiran yang agak stabil untuk mencatat atribut yang dipaparkan oleh item di bawah keperluan tertentu. Dalam beberapa tahun kebelakangan ini, dengan peningkatan beransur-ansur model bahasa besar (LLM), pemahaman tentang akal budi masyarakat manusia yang ditunjukkan oleh LLM adalah menakjubkan. Oleh itu, pasukan Universiti Peking Dong Hao memutuskan untuk mempelajari akal ini daripada LLM. Mereka mula-mula meminta LLM untuk menjana banyak arahan permintaan (dipanggil Language-grounding Demand, LGD dalam rajah), dan kemudian bertanya LLM item mana yang boleh memenuhi arahan permintaan ini (dipanggil Language-grounding Object, LGO dalam rajah).
Ia harus diperhatikan di sini bahawa pendirian bahasa awalan menekankan bahawa permintaan/objek ini dapat diperoleh dari LLM dan tidak bergantung pada senario tertentu; bersepadu rapat dengan persekitaran tertentu (seperti ProcThor, Replica dan set data pemandangan lain).
Kemudian untuk mendapatkan sifat LGO di bawah LGD, penulis menggunakan BERT untuk mengekod LGD, CLIP-Text-Encoder untuk mengekod LGO, dan kemudian menyambungkannya untuk mendapatkan Ciri-ciri objek Permintaan. Menyedari bahawa terdapat "persamaan" semasa memperkenalkan atribut item pada mulanya, penulis menggunakan persamaan ini untuk menentukan "sampel positif dan negatif" dan kemudian menggunakan pembelajaran kontrastif untuk melatih "atribut item". Khususnya, untuk dua Ciri Objek Permintaan yang disambung, jika item yang sepadan dengan dua ciri boleh memenuhi keperluan yang sama, maka kedua-dua ciri tersebut adalah sampel positif antara satu sama lain (contohnya, kedua-dua item a dan item b dalam gambar adalah boleh memenuhi keperluan D1, maka DO1-a dan DO1-b adalah sampel positif antara satu sama lain); Selepas pengarang memasukkan Ciri-ciri objek Permintaan ke dalam Modul Atribut seni bina TransformerEncoder, mereka berlatih dengan InfoNCE Loss.
Fasa pembelajaran strategi navigasi
Melalui pembelajaran perbandingan, Modul Atribut telah mempelajari akal yang disediakan oleh LLM Dalam fasa pembelajaran strategi navigasi, parameter Modul Atribut diimport secara langsung, dan kemudian algoritma A*. dipelajari menggunakan pembelajaran tiruan. Pada langkah masa tertentu, pengarang menggunakan model DETR untuk membahagikan item dalam medan pandangan semasa untuk mendapatkan Objek Pembumian Dunia, yang kemudiannya dikodkan oleh CLIP-Visual-Endocer. Proses lain adalah serupa dengan peringkat pembelajaran atribut. Akhir sekali, ciri BERT, ciri imej global dan ciri atribut arahan yang diperlukan disambungkan, dimasukkan ke dalam model Transformer, dan akhirnya tindakan dikeluarkan.
Perlu diingat bahawa pengarang menggunakan CLIP-Text-Encoder dalam peringkat pembelajaran atribut, dan dalam peringkat pembelajaran dasar navigasi, pengarang menggunakan CLIP-Visual-Encoder. Di sini, keupayaan penjajaran visual dan teks yang berkuasa bagi model CLIP digunakan dengan bijak untuk memindahkan akal fikiran teks yang dipelajari daripada LLM kepada penglihatan pada setiap langkah masa.
Hasil eksperimen
Percubaan dijalankan pada simulator AI2Thor dan set data ProcThor Keputusan eksperimen menunjukkan bahawa kaedah ini jauh lebih tinggi daripada varian sebelumnya bagi pelbagai algoritma navigasi item visual dan algoritma yang disokong oleh model bahasa yang besar.
VTN ialah algoritma navigasi perbendaharaan kata tertutup yang hanya boleh melaksanakan tugas navigasi pada item pratetap. Penulis telah membuat beberapa variasi algoritmanya Walau bagaimanapun, sama ada ciri BERT bagi arahan yang diperlukan digunakan sebagai input atau hasil penghuraian GPT arahan digunakan sebagai input, keputusan algoritma tidak begitu ideal. Apabila beralih kepada ZSON, algoritma navigasi perbendaharaan kata terbuka, disebabkan oleh kesan penjajaran yang lemah CLIP antara arahan permintaan dan gambar, beberapa varian ZSON tidak dapat menyelesaikan tugasan Navigasi permintaan. Walau bagaimanapun, sesetengah algoritma berdasarkan carian heuristik + LLM mempunyai kecekapan penerokaan yang rendah disebabkan oleh kawasan pemandangan yang besar bagi set data Procthor, dan kadar kejayaannya tidak terlalu tinggi. Algoritma LLM tulen, seperti GPT-3-Prompt dan MiniGPT-4, mempamerkan keupayaan penaakulan yang lemah untuk lokasi yang tidak kelihatan di tempat kejadian, mengakibatkan ketidakupayaan untuk menemui item yang memenuhi keperluan dengan cekap.
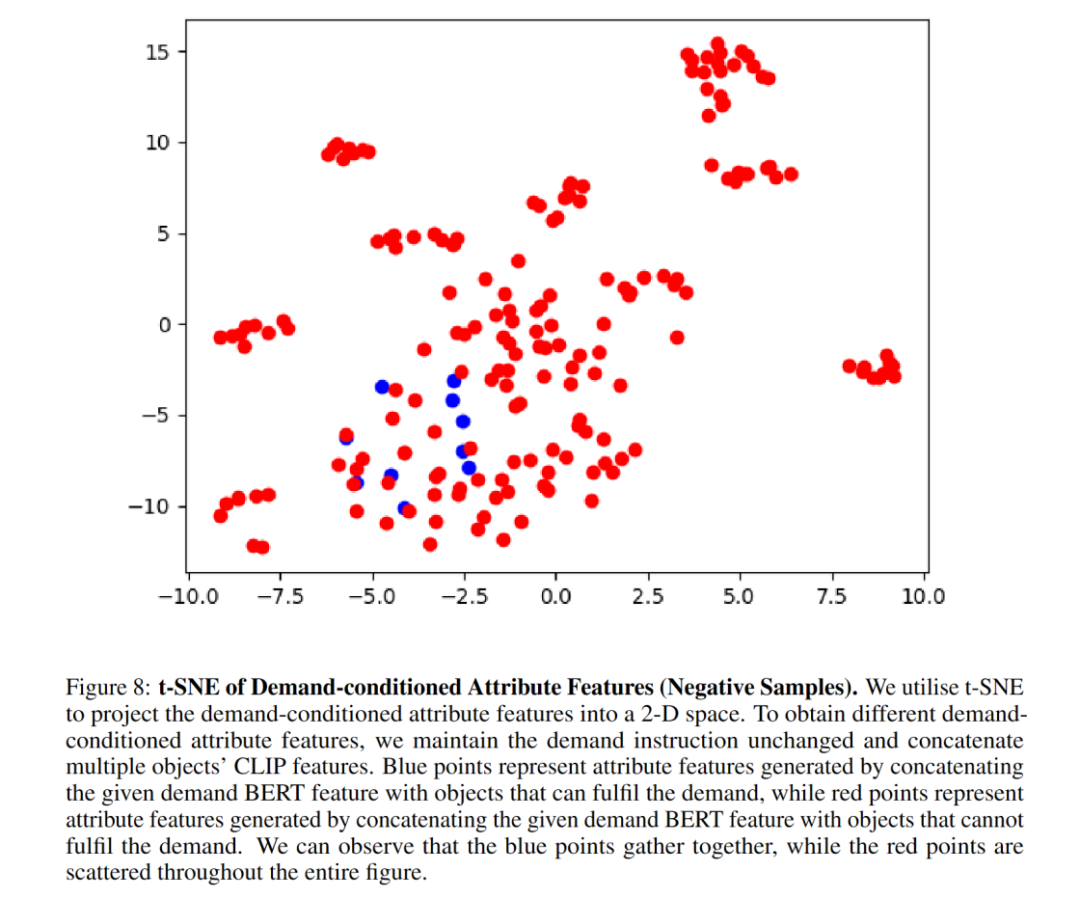
Percubaan ablasi menunjukkan bahawa Modul Atribut meningkatkan kadar kejayaan navigasi dengan ketara. Penulis menunjukkan bahawa graf t-SNE dengan baik menunjukkan bahawa Modul Atribut berjaya mempelajari ciri atribut item melalui pembelajaran kontrastif bersyarat permintaan. Selepas menggantikan seni bina Modul Atribut dengan MLP, prestasi menurun, menunjukkan bahawa seni bina TransformerEncoder lebih sesuai untuk menangkap ciri atribut. BERT boleh mengekstrak ciri-ciri arahan yang diperlukan, yang meningkatkan generalisasi arahan yang tidak kelihatan. Di sini terdapat beberapa visualisasi:
Penulis yang sepadan dalam kajian ini, Dr. Dong Hao, kini menjadi penolong profesor di Pusat Penyelidikan Pengkomputeran Frontier Peking Universiti, penyelia kedoktoran, dan sarjana muda seni liberal dan sarjana intelektual, beliau mengasaskan dan mengetuai Peking University Hyperplane Lab pada 2019. Beliau telah menerbitkan lebih daripada 40 kertas kerja dalam persidangan/jurnal antarabangsa terkemuka seperti NeurIPS, ICLR, CVPR, ICCV , ECCV, dsb. Google Scholar Ia telah disebut lebih daripada 4,700 kali dan telah memenangi Anugerah Perisian Sumber Terbuka Terbaik ACM MM dan Anugerah Projek Cemerlang OpenI. Beliau juga pernah berkhidmat sebagai pengerusi lapangan dan timbalan ahli lembaga editorial bagi persidangan antarabangsa terkemuka seperti NeurIPS, CVPR, AAAI, dan ICRA untuk beberapa kali, menjalankan beberapa projek nasional dan wilayah, dan mempengerusikan Generasi Baharu Kementerian Sains dan Teknologi. Projek utama Kecerdasan Buatan 2030. Pengarang pertama kertas kerja, Wang Hongzhen, kini merupakan pelajar kedoktoran tahun kedua di Sekolah Sains Komputer, Universiti Peking. Minat penyelidikannya memberi tumpuan kepada robotik, penglihatan komputer dan psikologi Dia berharap untuk bermula dari aspek tingkah laku manusia, kognisi dan motivasi untuk menyelaraskan hubungan antara manusia dan robot.
Pautan rujukan:[1] https://zsdonghao.github.io/




 Penulis yang sepadan dalam kajian ini, Dr. Dong Hao, kini menjadi penolong profesor di Pusat Penyelidikan Pengkomputeran Frontier Peking Universiti, penyelia kedoktoran, dan sarjana muda seni liberal dan sarjana intelektual, beliau mengasaskan dan mengetuai Peking University Hyperplane Lab pada 2019. Beliau telah menerbitkan lebih daripada 40 kertas kerja dalam persidangan/jurnal antarabangsa terkemuka seperti NeurIPS, ICLR, CVPR, ICCV , ECCV, dsb. Google Scholar Ia telah disebut lebih daripada 4,700 kali dan telah memenangi Anugerah Perisian Sumber Terbuka Terbaik ACM MM dan Anugerah Projek Cemerlang OpenI. Beliau juga pernah berkhidmat sebagai pengerusi lapangan dan timbalan ahli lembaga editorial bagi persidangan antarabangsa terkemuka seperti NeurIPS, CVPR, AAAI, dan ICRA untuk beberapa kali, menjalankan beberapa projek nasional dan wilayah, dan mempengerusikan Generasi Baharu Kementerian Sains dan Teknologi. Projek utama Kecerdasan Buatan 2030.
Penulis yang sepadan dalam kajian ini, Dr. Dong Hao, kini menjadi penolong profesor di Pusat Penyelidikan Pengkomputeran Frontier Peking Universiti, penyelia kedoktoran, dan sarjana muda seni liberal dan sarjana intelektual, beliau mengasaskan dan mengetuai Peking University Hyperplane Lab pada 2019. Beliau telah menerbitkan lebih daripada 40 kertas kerja dalam persidangan/jurnal antarabangsa terkemuka seperti NeurIPS, ICLR, CVPR, ICCV , ECCV, dsb. Google Scholar Ia telah disebut lebih daripada 4,700 kali dan telah memenangi Anugerah Perisian Sumber Terbuka Terbaik ACM MM dan Anugerah Projek Cemerlang OpenI. Beliau juga pernah berkhidmat sebagai pengerusi lapangan dan timbalan ahli lembaga editorial bagi persidangan antarabangsa terkemuka seperti NeurIPS, CVPR, AAAI, dan ICRA untuk beberapa kali, menjalankan beberapa projek nasional dan wilayah, dan mempengerusikan Generasi Baharu Kementerian Sains dan Teknologi. Projek utama Kecerdasan Buatan 2030. 



Atas ialah kandungan terperinci Pasukan perisikan Universiti Peking mencadangkan navigasi dipacu permintaan untuk menyelaraskan keperluan manusia dan menjadikan robot lebih cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI