
Rumah >Peranti teknologi >AI >Selepas menukar kepada lebih daripada 30 dialek, kami gagal lulus ujian model pertuturan besar China Telecom
Selepas menukar kepada lebih daripada 30 dialek, kami gagal lulus ujian model pertuturan besar China Telecom

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-07-15 17:44:571122semak imbas
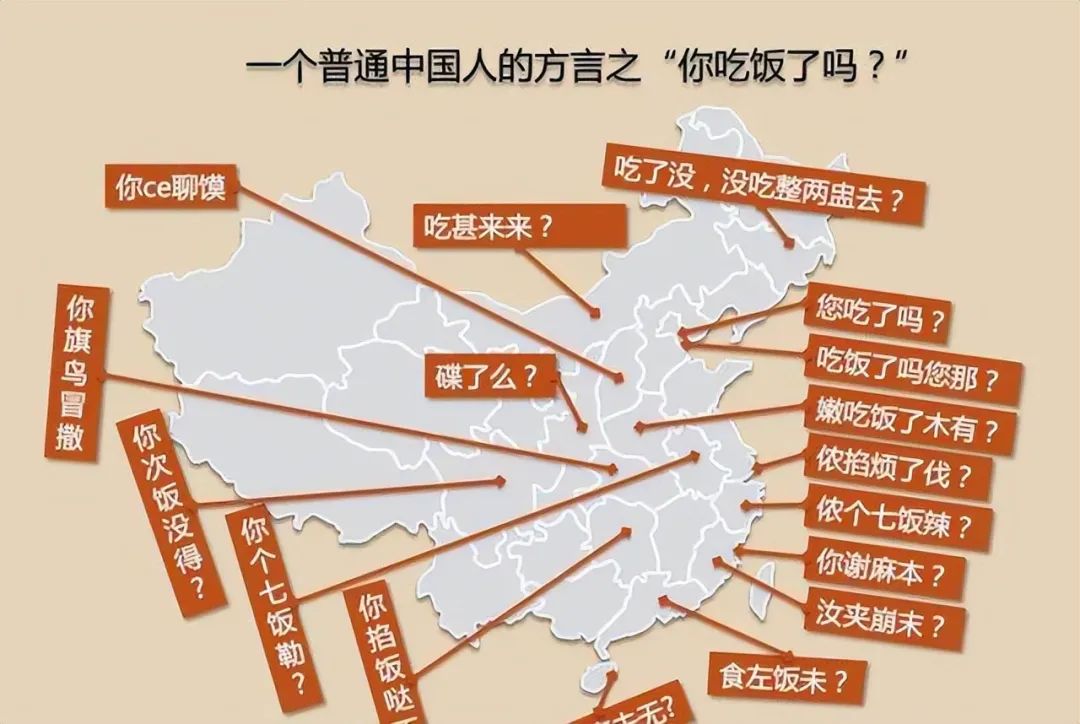
Tidak kira dari bandar mana anda berasal, saya percaya anda mempunyai "dialek kampung halaman" anda sendiri dalam ingatan anda: Dialek Wu lembut dan halus, dialek Guanzhong ringkas dan tebal, dialek Sichuan lucu dan lucu, Kantonis pelik dan tidak terkawal. ..
Dari satu segi, Dialek bukan sahaja kebiasaan bahasa, tetapi juga hubungan emosi dan identiti budaya. Banyak perkataan baharu yang kita temui semasa melayari Internet berasal daripada dialek tempatan dari pelbagai tempat.
Semestinya kadangkala dialek juga menjadi "penghalang" komunikasi.
Dalam kehidupan sebenar, kita sering melihat "ayam bercakap seperti itik" disebabkan oleh dialek, seperti ini: 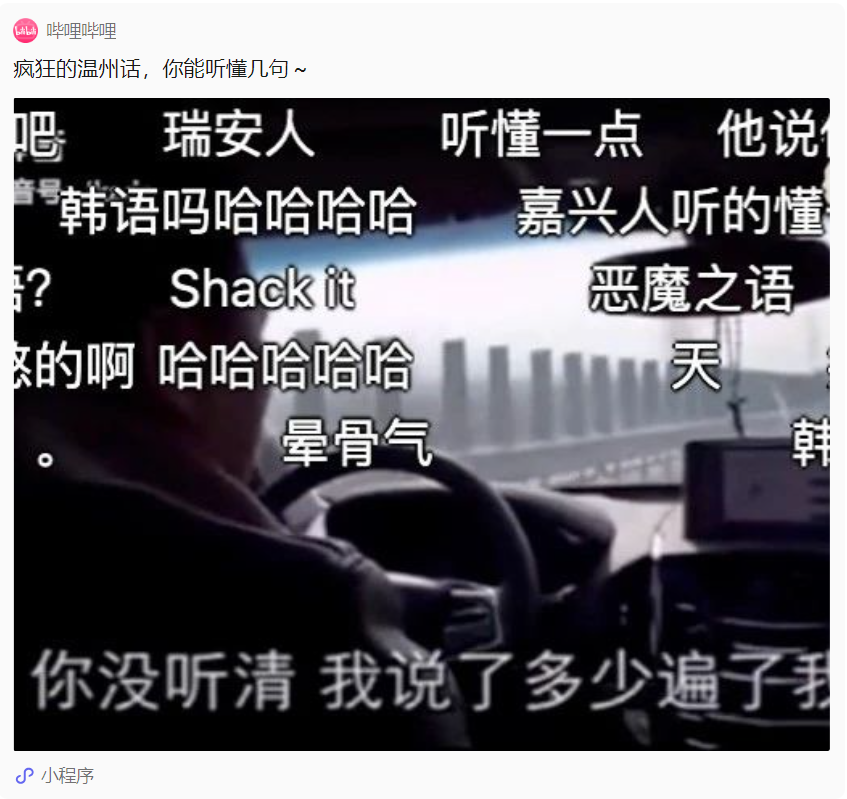
Jika anda memberi perhatian kepada trend terkini dalam kalangan teknologi, anda akan tahu bahawa pembantu suara AI semasa sudah boleh mencapai Tahap "tindak balas masa nyata" adalah lebih cepat daripada tindak balas manusia. Selain itu, AI telah dapat memahami sepenuhnya emosi manusia dan boleh meluahkan pelbagai emosi dengan sendirinya.
Atas dasar ini, jika pembantu suara dapat mengenali dan memahami setiap dialek, ia boleh memecahkan sepenuhnya halangan komunikasi dan berkomunikasi dengan mana-mana kumpulan tanpa halangan.
Malah, seseorang telah pun melakukan perkara ini: Baru-baru ini, Institut Penyelidikan Kecerdasan Buatan Telekom China (TeleAI) mengeluarkan "Model Pengecaman Pertuturan Berbilang Dialek Super Xingchen" pertama dalam industri yang menyokong 30 dialek untuk diadun secara bebas dan serentak memahami bahasa Kantonis, Shanghai, Sichuan, Wenzhou dan dialek tempatan yang lain Ia merupakan model pengecaman pertuturan besar yang menyokong kebanyakan dialek di China.
Sebagai contoh, dalam senario persidangan berikut, berhadapan dengan input daripada pelbagai dialek, ketepatan pengecaman model pengecaman pertuturan berbilang dialek besar Xingchen mencapai tahap terkemuka dalam industri.
Mula-mula, wakil dari syarikat Guangdong bercakap dalam bahasa Kantonis: 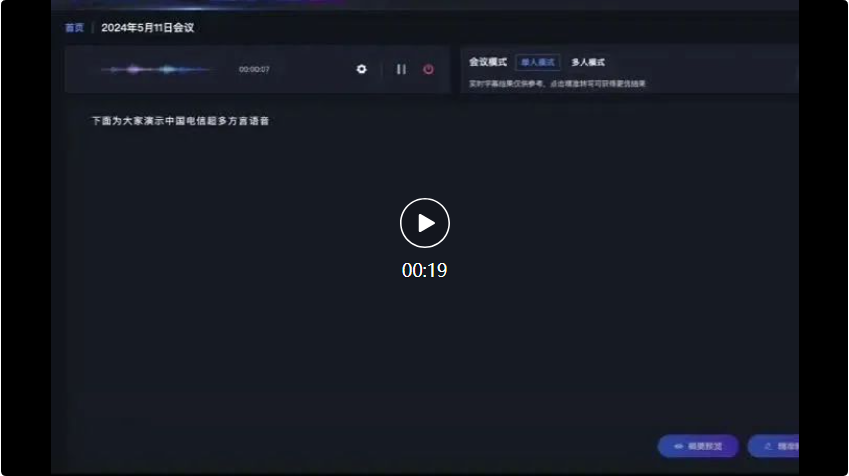
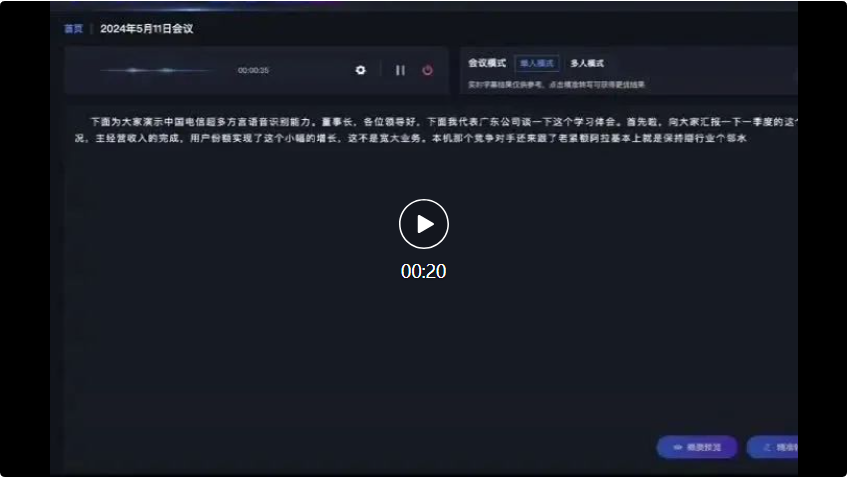 Dalam dialog berikutnya antara dialek Sichuan dan dialek model berbilang dialek Shanxi reco besar, dialek berbilang dialek X. juga boleh mengecam dan menukar dengan tepat kepada rekod teks:
Dalam dialog berikutnya antara dialek Sichuan dan dialek model berbilang dialek Shanxi reco besar, dialek berbilang dialek X. juga boleh mengecam dan menukar dengan tepat kepada rekod teks: 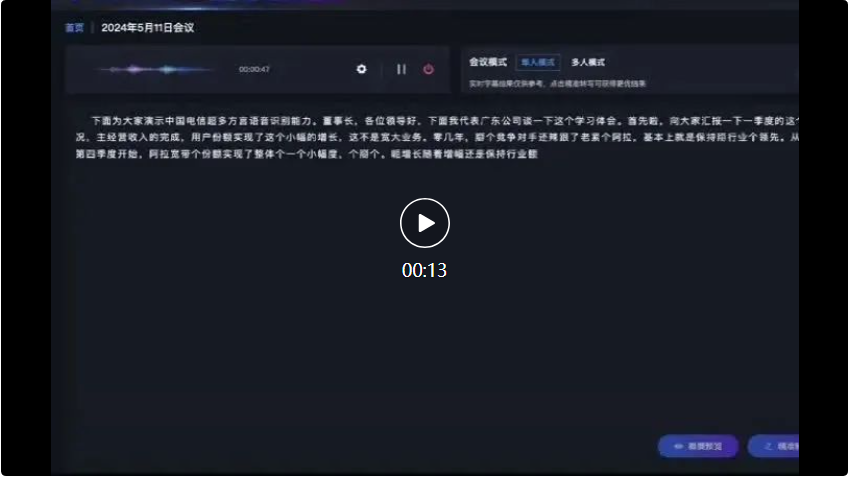
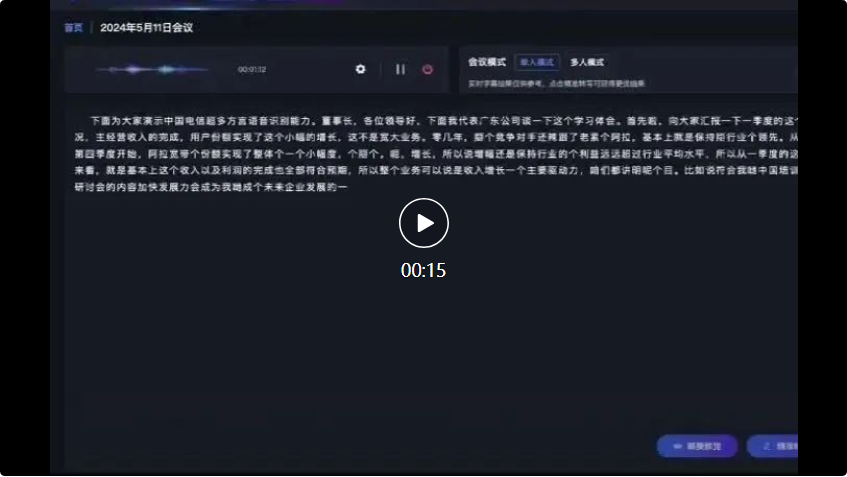
Sesiapa yang telah bercakap dengan pembantu suara tahu bahawa ketepatan pengecaman pertuturan untuk bahasa Mandarin adalah agak baik, tetapi Apabila berhadapan dengan loghat atau dialek yang kuat, pengiktirafan itu ketepatan akan menurun dengan ketara, atau bahkan "meletakkan mahkota dalam topi".
Untuk menyelesaikan masalah ini, model pengecaman pertuturan tradisional adalah untuk melatih model dialek secara berasingan untuk setiap dialek Ini menyebabkan keperluan untuk mengekalkan beberapa model dialek di sebalik aplikasi yang sama, dan adalah mustahil untuk mengenali pelbagai dialek melalui satu. model. Walau bagaimanapun, yang terakhir adalah perkara yang paling diperlukan dalam senario kehidupan sebenar.
China Telecom, yang telah terlibat secara mendalam dalam bidang suara, memutuskan untuk mencabar cadangan ini: mencipta model pengecaman pertuturan besar yang lebih "universal".
Lebih daripada 30 dialek, bagaimana untuk mendapatkan model besar?
Bukan semudah yang dibayangkan untuk membiarkan model besar mempelajari lebih daripada 30 dialek sekali gus - cabaran juga wujud dari segi data, algoritma dan kuasa pengkomputeran.
Di satu pihak, disebabkan jumlah data dialek yang jarang, kesan melatih model dialek sahaja tanpa menggunakan maklumat biasa dalam data dialek lain selalunya tidak memuaskan.
Selepas bertahun-tahun terkumpul dalam bidang pertuturan, TeleAI telah membina pangkalan data dialek berkualiti tinggi dengan lebih daripada 30 jenis dan lebih daripada 300,000 jam pangkalan data dialek berada di barisan hadapan industri dari segi kekayaan dan kualiti yang tinggi. Data pertuturan berkualiti tinggi merupakan nilai tambah yang besar untuk penyelidik, yang membolehkan model menyusun dan meringkaskan dialek dengan lebih cekap dan sistematik. Dalam jangka panjang, membina pangkalan data dialek berkualiti tinggi juga merupakan asas untuk perlindungan dan penyelidikan dialek.
Satu lagi cabaran datang daripada teknologi pengecaman pertuturan. Cara membuat pengguna bercakap dengan model besar secara semula jadi seperti bercakap dengan ahli keluarga, tanpa perlu sengaja menukar ke bahasa Mandarin, tanpa perlu meningkatkan kelantangan atau memperlahankan kelajuan bercakap, adalah matlamat baharu yang sedang diusahakan oleh industri.
Dipimpin oleh Li Xuelong, CTO China Telecom dan Pengarah Institut Penyelidikan Kepintaran Buatan, TeleAI membangunkan model pengecaman pertuturan Xingchen berskala besar secara bebas. Pasukan ini mempelopori algoritma latihan bersama "penyulingan + pengembangan", yang menyelesaikan masalah keruntuhan pra-latihan di bawah set data berbilang senario berskala ultra-besar dan keadaan parameter berskala besar, dan mencapai latihan yang stabil bagi model 80-lapisan . Pada masa yang sama, melalui pra-latihan pertuturan berskala ultra besar dan pemodelan bersama berbilang dialek, satu model menyokong pengecaman pertuturan campuran percuma bagi 30 dialek.

Model besar pengecaman pertuturan Xingchen juga merupakan model pengecaman pertuturan besar sumber terbuka pertama industri berdasarkan perwakilan pertuturan diskret Melalui paradigma pemodelan baharu "dari pertuturan kepada token kepada teks", kadar bit penghantaran pertuturan semasa inferens dikurangkan Dikurangkan sebanyak berpuluh-puluh kali.
Dengan prestasi yang sangat terkemuka, model besar pengecaman pertuturan Xingchen sebelum ini telah memenangi beberapa kejohanan pertandingan berwibawa antarabangsa di peringkat antarabangsa.
Sebagai contoh, dalam trek ASR (Pengiktirafan Pertuturan Automatik, Pengecaman Pertuturan Automatik) bagi Cabaran Pemodelan Unit Pertuturan Diskret Interspeech 2024, persidangan pidato antarabangsa yang berwibawa, pasukan model besar pengecaman pertuturan Xingchen mendahului Universiti Johns Hopkins, Card Well -universiti dan syarikat terkenal di dalam dan luar negara, termasuk Universiti Mellon dan NVIDIA, memenangi kejuaraan trek dalam satu masa.
Penyelesaian sistem yang dicadangkan oleh pasukan dalam pertandingan ini sangat tersendiri: ia menggunakan reka bentuk "tiga peringkat" semasa latihan, termasuk strategi pelarasan perwakilan model pra-latihan bahagian hadapan (Model Depan), pengekstrakan perwakilan dan proses pendiskretan (Proses Token Dsicrete) dan proses latihan model pengecaman berbilang bahasa (Model ASR Diskret), manakala hanya dua proses terakhir digunakan dalam peringkat inferens.
Kaedah pendiskrisian perwakilan membolehkan model mengekalkan maklumat berkaitan tugasan dalam pertuturan sambil mengalih keluar maklumat lain yang tidak berkaitan untuk mencapai tujuan mengurangkan kadar bit penghantaran inferens pertuturan, mengurangkan penggunaan ingatan dan meningkatkan kecekapan latihan. Ia juga menyediakan penyelesaian pertuturan disediakan dalam arahan pembinaan model bersatu, pemodelan model pelbagai mod dan perlindungan privasi pembesar suara untuk pelbagai tugas (seperti ASR, TTS, pengecaman pembesar suara, dll.).
Mengenai tugas KeSpeech, set data pengecaman pertuturan berbilang dialek yang terkenal dalam industri, model besar pengecaman pertuturan Xingchen memecahkan rekod sebanyak 20% mendahului keputusan terbaik sebelumnya, mencapai ketepatan perkataan sebanyak 92.97%. Dalam tugas pengecaman pertuturan Babel telefon Kantonis sumber rendah yang dipegang oleh NIST (Institut Piawaian dan Teknologi Kebangsaan), model besar pengecaman pertuturan Xingchen juga mencapai keputusan terbaik dalam industri.
Dari segi cabaran kuasa pengkomputeran biasa, pasukan R&D model besar pengecaman pertuturan Xingchen juga mempunyai kelebihan. China Telecom ialah pengendali domestik pertama yang memasuki bidang pengkomputeran awan dan telah mengumpulkan sejumlah besar teknologi teras untuk pembinaan kuasa pengkomputeran dan penjadualan kuasa pengkomputeran. Di samping itu, China Telecom telah beroperasi secara berturut-turut beberapa pusat pengkomputeran pintar awam yang memenuhi keperluan latihan model besar, seperti Pusat Pengkomputeran Pintar Beijing-Tianjin-Hebei dan Pusat Pengkomputeran Pintar Tengah-Selatan.
Berdasarkan kelebihan ini, model pengecaman pertuturan berbilang dialek besar Xingchen telah dilahirkan, memecahkan dilema bahawa model tunggal hanya boleh mengenali dialek tunggal tertentu. Dalam pelbagai ujian penanda aras, model besar pengecaman pertuturan super pelbagai dialek Xingchen telah menunjukkan keupayaan yang sangat baik:
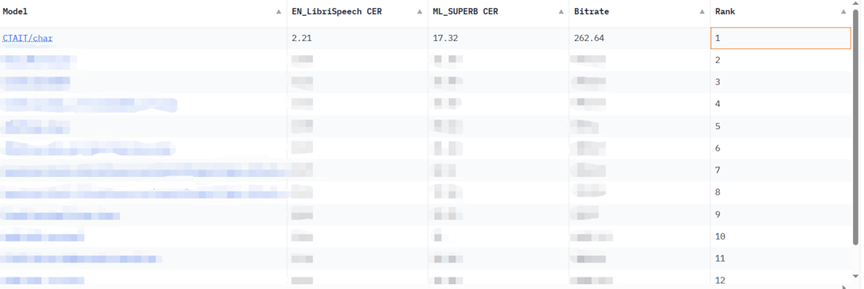
 Dalam jangka panjang, keupayaan pelbagai dialek model pengecaman pertuturan berbilang dialek berskala besar Xingchen boleh menjadi berharga dalam pelbagai senario kehidupan sosial yang sangat luas. Mengambil senario
Dalam jangka panjang, keupayaan pelbagai dialek model pengecaman pertuturan berbilang dialek berskala besar Xingchen boleh menjadi berharga dalam pelbagai senario kehidupan sosial yang sangat luas. Mengambil senario
dengan frekuensi tinggi interaksi suara sebagai contoh, model pengecaman pertuturan berbilang dialek besar Xingchen, yang mahir dalam pelbagai dialek, boleh membolehkan sistem mengenali dan menyalin input pertuturan dalam pelbagai dialek dengan lebih tepat, membawa pengalaman yang lebih semula jadi dan lancar, terutamanya di kawasan yang lazimnya dialek, dapat mengurangkan salah faham yang disebabkan oleh "ayam bercakap dengan itik". Dari perspektif
persahabatan emosi, pemahaman dan kecekapan model besar dalam dialek dapat meningkatkan kualiti persahabatan produk robot perbualan, dan menyelesaikan masalah warga tua dan kumpulan lain yang tidak mahir dalam bahasa Mandarin dengan berkesan, mengakses perkhidmatan maklumat. Sama seperti plot dalam filem fiksyen sains "Her", AI boleh memberikan manusia penjagaan berkualiti tinggi yang mengatasi hubungan interpersonal di dunia nyata. Pada masa ini, model pengecaman pertuturan berbilang dialek besar Xingchen telah mula disepadukan ke dalam pelbagai industri dan sedang aktif meneroka senario aplikasi yang baru muncul. Sebagai contoh, model pengecaman pertuturan berbilang dialek berskala besar Xingchen telah dipandu dalam sistem perkhidmatan pelanggan pintar Wanhao China Telecom di Fujian, Jiangxi, Guangxi, Beijing, Mongolia Dalam dan tempat-tempat lain selepas mengakses berbilang dialek berskala besar model pengecaman pertuturan, Wanhao Perkhidmatan Pelanggan Pintar memahami 30 dialek dalam beberapa saat dan mengendalikan purata kira-kira 2 juta panggilan setiap hari platform perkhidmatan pelanggan pintar Yisheng disambungkan kepada pemahaman pertuturan dan keupayaan analisis pertuturan super pelbagai dialek Xingchen; model pengiktirafan, mencapai liputan penuh di 31 wilayah dan boleh mengendalikannya setiap hari 1.25 juta panggilan perkhidmatan pelanggan. Bagi China Telecom, terdapat satu lagi titik permulaan yang sangat penting: sebelum 2023, apabila orang bercakap tentang teknologi model besar, nilai kebajikan awam jarang disebut. Tetapi pada tahun 2024, nilai ini semakin "dilihat". Aplikasi teknologi model besar akan sangat menggalakkan perlindungan budaya dialek. Di antara lebih daripada 130 bahasa di negara kita, 68 mempunyai kurang daripada 10,000 penutur, 48 mempunyai kurang daripada 5,000 penutur, 25 mempunyai kurang daripada 1,000 penutur, dan sesetengah bahasa hanya mempunyai sedozen atau bahkan beberapa penutur. boleh bercakap. Penyertaan model pertuturan yang besar boleh membantu merekod dan melindungi dialek yang terancam dan menggalakkan pewarisan dan pembelajaran dialek. Untuk dokumen dan arkib sejarah yang mengandungi sejumlah besar kandungan dialek, model besar dialek juga boleh membantu dalam pendigitalan dan kerja organisasi untuk mengelakkan kehilangan warisan budaya. "Pembantu Suara" dibuka sepenuhnya Bagaimanakah China Telecom boleh memimpin pertempuran untuk melaksanakan model besar? Pertempuran untuk model besar telah berlangsung selama satu setengah tahun pada masa ini terdapat konsensus dalam industri: memandangkan kos inferens model besar menurun dengan ketara, orang ramai akan memulakan tempoh ledakan untuk aplikasi model besar. Di antara banyak pemain model besar di dalam dan luar negara, China Telecom adalah yang sangat istimewa. Dalam peringkat baharu ini, berbanding syarikat teknologi yang kita kenali, pengendali seperti China Telecom mempunyai lebih banyak kelebihan dari segi sumber dan perniagaan. Di satu pihak, pengendali mempunyai sumber rangkaian dan pengkomputeran yang banyak, dan secara relatifnya, kos latihan dan inferens adalah lebih rendah. Terutama dalam pembinaan model besar, lebih mudah untuk memanfaatkan skala. Sebaliknya, China Telecom mempunyai pangkalan pelanggan yang besar dan perniagaan perkhidmatan maklumat 2C, 2H, dan 2B yang kaya, yang boleh dengan cepat mempromosikan pelaksanaan model kecerdasan buatan yang besar dalam pelbagai bidang dan membentuk titik pertumbuhan ekonomi baharu. Kelebihan ini memberi operator insentif untuk meningkatkan pelaburan dalam bidang kecerdasan buatan dan memacu kemajuan teknologi. Antara pengendali domestik, China Telecom ialah yang pertama digunakan dalam bidang AI, dan mematuhi laluan pembangunan inovasi teknologi dan penyelidikan bebas serta pembangunan keupayaan teras. Sejak tahun lepas, daripada model besar semantik Xingchen kepada model besar multi-modal Xingchen dan model besar pengecaman pertuturan Xingchen, model besar China Telecom sentiasa mengekalkan lelaran pantas dan melengkapkan model penuh semantik, pertuturan, penglihatan dan pelbagai mod. Reka letak model besar yang dinamik. 

 Adakah anda menantikan pembantu suara Cina yang serba boleh?
Adakah anda menantikan pembantu suara Cina yang serba boleh?
Atas ialah kandungan terperinci Selepas menukar kepada lebih daripada 30 dialek, kami gagal lulus ujian model pertuturan besar China Telecom. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI