
Rumah >Peranti teknologi >AI >Model besar perubatan 3D sumber terbuka SAT menyokong 497 organoid dan mempunyai prestasi melebihi 72 nnU-Nets Ia dikeluarkan oleh pasukan Universiti Shanghai Jiao Tong.
Model besar perubatan 3D sumber terbuka SAT menyokong 497 organoid dan mempunyai prestasi melebihi 72 nnU-Nets Ia dikeluarkan oleh pasukan Universiti Shanghai Jiao Tong.

- 王林asal
- 2024-07-12 10:52:01625semak imbas

Pengarang |. Universiti Shanghai Jiao Tong, Makmal Kecerdasan Buatan Shanghai
Editor |. imbasan radiologi, didorong oleh gesaan Teks), pada imej perubatan 3D (CT, MR, PET), berdasarkan gesaan teks untuk mencapai pembahagian sejagat bagi 497 jenis organ/lesi dalam badan manusia. Semua data, kod dan model adalah sumber terbuka.
 Pautan kertas:
Pautan kertas:
Pautan kod:
https://github.com/zhaoziheng/SAThttps://pautanData .com/zhaoziheng/SAT-DS/
Latar belakang penyelidikan
Segmentasi imej perubatan memainkan peranan penting dalam satu siri tugas klinikal seperti diagnosis, perancangan pembedahan dan pemantauan penyakit. Walau bagaimanapun, penyelidikan tradisional melatih model "berdedikasi" untuk setiap tugas pembahagian tertentu, menyebabkan setiap model "berdedikasi" mempunyai skop aplikasi yang agak terhad dan tidak dapat memenuhi pelbagai keperluan segmentasi perubatan dengan cekap dan mudah.
Pada masa yang sama, model bahasa besar baru-baru ini telah mencapai kejayaan besar dalam bidang perubatan, dan untuk menggalakkan lagi pembangunan kecerdasan buatan perubatan am, adalah perlu untuk membina alat segmentasi perubatan yang boleh menghubungkan bahasa dan keupayaan kedudukan.Rajah 1: SAT pada asasnya berbeza daripada rangka kerja segmentasi sedia ada. 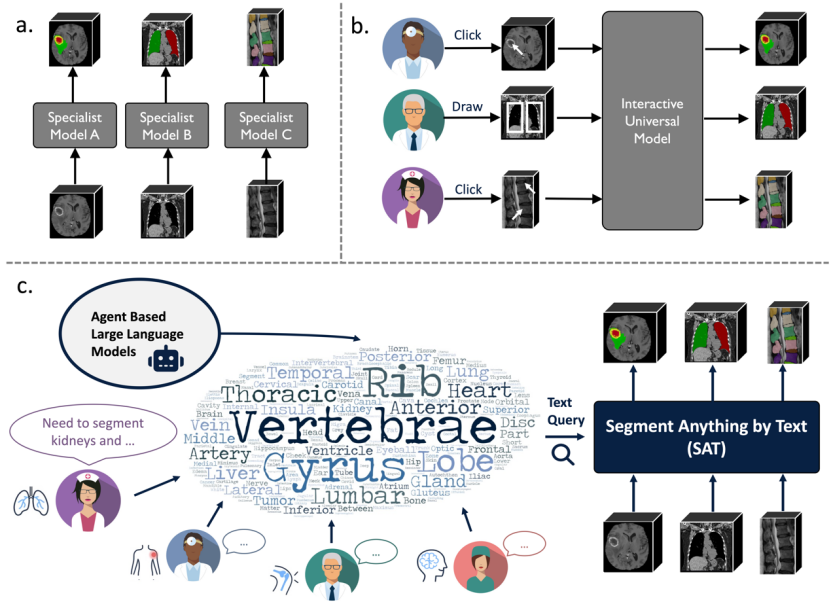
1. Kajian ini adalah yang pertama untuk meneroka menyuntik pengetahuan anatomi manusia ke dalam pengekod teks untuk mengekod istilah anatomi dengan tepat dan mencapai gesaan teks untuk imej radiologi .
2. Penyelidikan ini membina graf pengetahuan perubatan pelbagai mod pertama yang mengandungi 6K+ konsep anatomi manusia. Pada masa yang sama, set data segmentasi imej perubatan 3D terbesar telah dibina, dipanggil SAT-DS, yang menghimpunkan 72 set data awam, 22K+ imej daripada modaliti CT, MR dan PET, dan anotasi segmentasi 302K+, meliputi tubuh manusia 497 sasaran segmentasi dalam 8 bahagian utama. 3 Berdasarkan SAT-DS, kajian ini melatih dua model dengan saiz yang berbeza: SAT-Pro (parameter 447M) dan SAT-Nano (parameter 110M), dan mereka bentuk eksperimen untuk mengesahkan nilai SAT dari pelbagai sudut: SAT The. prestasi adalah bersamaan dengan 72 model pakar nnU-Nets (parameter dilaraskan dan dioptimumkan secara berasingan pada setiap set data, sejumlah kira-kira 2.2B parameter), dan menunjukkan keupayaan generalisasi yang lebih kukuh pada data luar domain boleh digunakan sebagai Model pembahagian asas yang telah dilatih pada data berskala besar boleh menunjukkan prestasi yang lebih baik daripada nnU-Nets apabila dipindahkan ke tugas tertentu melalui penalaan halus hiliran sebagai tambahan, berbanding dengan MedSAM berdasarkan gesaan kotak, SAT boleh mencapai lebih tepat dan prestasi yang tepat berdasarkan gesaan teks. Akhirnya, pada data klinikal di luar domain, pasukan penyelidik menunjukkan bahawa SAT boleh digunakan sebagai alat proksi untuk model bahasa yang besar, secara langsung memperkasakan yang terakhir dengan keupayaan penyetempatan dan pembahagian dalam tugasan seperti sebagai penjanaan laporan. Yang berikut akan memperkenalkan butiran artikel asal dari tiga aspek: data, model dan hasil percubaan.Pembinaan data
Graf pengetahuan pelbagai modal:
Untuk mencapai pengekodan tepat istilah anatomi, pasukan penyelidik mula-mula mengumpul graf pengetahuan pelbagai mod yang mengandungi 6K+ konsep anatomi manusia, yang kandungannya berasal daripada tiga sumber :1. Sistem Bahasa Perubatan Bersepadu (UMLS) ialah kamus bioperubatan yang dibina oleh Perpustakaan Perubatan Negara A.S. Pasukan penyelidik mengekstrak hampir 230K konsep dan definisi bioperubatan, serta graf pengetahuan yang meliputi 1J+ hubungan bersama.
2. Pengetahuan anatomi berwibawa di Internet. Pasukan penyelidik menapis 6502 konsep anatomi manusia dan mendapatkan maklumat yang relevan daripada Internet dengan bantuan model bahasa besar yang dipertingkatkan semula, mendapatkan konsep dan definisi 6K+ dan peta pengetahuan yang meliputi 38K+ hubungan antara struktur anatomi. 3. Dataset pembahagian awam. Pasukan penyelidik mengumpul set data pembahagian imej perubatan 3D awam berskala besar, dan menghubungkan kawasan tersegmen melalui konsep anatomi (label kategori) dengan pengetahuan dalam pangkalan pengetahuan teks yang disebutkan di atas untuk menyediakan perbandingan pengetahuan visual.SAT-DS: Untuk melatih model segmentasi universal, pasukan penyelidik membina SAT-DS, pengumpulan data segmentasi imej perubatan 3D terbesar di lapangan. Khususnya, 72 set data segmentasi awam yang pelbagai telah dikumpulkan dan disusun, termasuk sejumlah 22,186 imej 3D, 302,033 anotasi segmentasi, daripada tiga modaliti: CT, MR, dan PET, dan 497 segmentasi meliputi 8 kawasan utama badan manusia (. struktur anatomi atau lesi).
Untuk meminimumkan perbezaan antara set data heterogen, pasukan penyelidik menyeragamkan orientasi, jarak voxel, nilai kelabu dan atribut imej lain antara set data yang berbeza, dan menamakan set data yang berbeza menggunakan kategori segmentasi sistem istilah anatomi bersatu.

Rajah 3: SAT-DS ialah pengumpulan data segmentasi imej perubatan 3D berskala besar dan pelbagai, meliputi sejumlah 497 kategori segmentasi dalam 8 kawasan utama badan manusia.
Seni bina model
Suntikan pengetahuan: Untuk membina pengekod segera yang boleh mengekod istilah anatomi dengan tepat, pasukan penyelidik mula-mula menyuntik pengetahuan anatomi pelbagai mod ke dalam pengekod teks menggunakan pembelajaran kontrastif.
Seperti yang ditunjukkan dalam Rajah a di bawah, konsep anatomi digunakan untuk menghubungkan pengetahuan berbilang mod kepada pasangan, dan kemudian pengekod visual dan pengekod teks digunakan untuk mengekod pengetahuan visual dan teks masing-masing, dan ciri dipelajari melalui kontras Dengan menjajarkan visual ciri struktur anatomi dengan pengetahuan teks dalam ruang dan membina hubungan antara struktur anatomi, kami mempelajari pengekodan konsep anatomi yang lebih baik dan berfungsi sebagai petunjuk untuk membimbing latihan model segmentasi visual.
Segmentasi universal berdasarkan gesaan teks: Pasukan penyelidik seterusnya mereka bentuk rangka kerja model segmentasi universal berdasarkan gesaan teks, seperti yang ditunjukkan dalam Rajah b di bawah, termasuk pengekod teks, pengekod visual, penyahkod visual dan penyahkod segera.
Antaranya, memandangkan struktur anatomi yang sama mempunyai perbezaan dalam imej yang berbeza, penyahkod kiu (penyahkod pertanyaan) menggunakan ciri imej yang dikeluarkan oleh pengekod visual untuk meningkatkan ciri konsep anatomi, iaitu isyarat segmentasi. Akhir sekali, produk titik dikira antara pembayang pembahagian dan keluaran ciri tahap piksel oleh penyahkod visual untuk mendapatkan hasil ramalan pembahagian.

Penilaian Model
Kajian ini membandingkan SAT dengan dua kaedah perwakilan, iaitu model nnU-Nets "khusus" dan model segmentasi am interaktif MedSAM. Penilaian merangkumi dua aspek: ujian set data dalam domain (prestasi segmentasi komprehensif) dan ujian set data luar domain pukulan sifar (keupayaan pemindahan data merentas pusat Hasil penilaian disepadukan daripada tiga peringkat: set data,). kategori dan kawasan badan manusia:
-
Kategori: Keputusan pembahagian kategori yang sama antara set data yang berbeza diringkaskan dan dipuratakan; dirumuskan dan dipuratakan; prestasi nnU-Nets, kajian melakukan analisis data berasingan pada setiap data berasingan nnU-Nets dilatih pada set dan dibandingkan dengan SAT Tetapan khusus adalah seperti berikut:
1 Dalam ujian dalam domain, semua 72 set data dalam SAT-DS digunakan untuk ujian dan perbandingan. Untuk SAT, jumlah 72 set latihan digunakan untuk latihan dan diuji pada 72 set ujian untuk nnU-Nets, keputusan 72 nnU-Nets pada set ujian masing-masing diringkaskan secara keseluruhan. 2 Dalam ujian luar domain, 72 set data dibahagikan lagi, dan set latihan 49 set data (dinamakan SAT-DS-Nano) digunakan untuk melatih SAT-Nano, dan ujian pukulan sifar; untuk nnU-Nets, 49 nnU-Nets digunakan untuk menguji pada 10 set ujian luar domain dan keputusannya diringkaskan.
Jadual 1: Perbandingan ujian dalam domain SAT-Pro, SAT-Nano, SAT-Pro-Ft dan nnU-Nets, hasilnya disepadukan dalam unit kawasan atau lesi. H&N bermaksud Kepala dan Leher, UL bermaksud Anggota Atas, dan LL bermaksud Anggota Badan Bawah. Kategori yang muncul dalam berbilang wilayah dikelaskan sebagai Seluruh Badan (WB), dan Semua mewakili hasil purata 497 kategori.
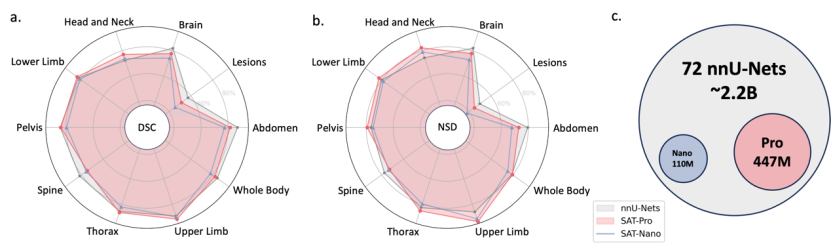
Keputusan ujian dalam domain: Seperti yang dapat dilihat daripada Jadual 1, SAT-Pro menunjukkan prestasi yang sangat hampir kepada 72 nnU-Nets dalam ujian dalam domain, dan melepasi nnU-Nets dalam pelbagai kawasan. Perlu diingatkan bahawa SAT boleh menyelesaikan 72 tugasan segmentasi dengan hanya satu model, dan saiz model jauh lebih kecil daripada set nnU-Nets (seperti ditunjukkan dalam Rajah c di bawah).
Keputusan ujian migrasi penalaan halus: Kajian ini menguji lagi SAT-Pro pada setiap set data selepas penalaan halus secara berasingan, dinamakan SAT-Pro-Ft. Seperti yang dapat dilihat daripada Jadual 1, SAT-Pro-Ft mempunyai peningkatan prestasi yang ketara dalam semua bidang berbanding SAT-Pro, dan melebihi nnU-Nets dalam prestasi keseluruhan.
Keputusan ujian di luar domain: Seperti yang ditunjukkan dalam Jadual 2, SAT-Nano mengatasi nnU-Nets dalam 19 daripada 20 penunjuk dalam 10 set data, menunjukkan keseluruhan keupayaan migrasi yang lebih kukuh.
Jadual 2: Perbandingan ujian luar domain antara SAT-Nano, nnU-Nets dan MedSAM Hasilnya dibentangkan dalam unit set data.

Percubaan perbandingan dengan model segmentasi interaktif MedSAM
Kajian ini secara langsung menggunakan pusat pemeriksaan awam MedSAM untuk ujian dan tetapan khusus adalah seperti berikut:
1 data Kami selanjutnya menyaring 32 set data yang digunakan dalam latihan MedSAM untuk perbandingan.
2 Dalam ujian luar domain, 5 set data yang belum digunakan dalam latihan MedSAM telah disaring untuk perbandingan.
Untuk MedSAM, pertimbangkan dua gesaan Kotak berbeza: menggunakan segi empat tepat terkecil (Kotak Oracle) yang mengandungi pembahagian kebenaran tanah, direkodkan sebagai MedSAM (Ketat menambah offset rawak berdasarkan Kotak Oracle, direkodkan sebagai MedSAM (Loose). Pada masa yang sama, uji kesan Oracle Box secara langsung sebagai ramalan. Untuk SAT, model dalam eksperimen perbandingan nnU-Nets digunakan secara langsung untuk menguji set data ini tanpa latihan semula.
Keputusan ujian dalam domain:Seperti yang ditunjukkan dalam Jadual 3, SAT-Pro berprestasi lebih baik daripada MedSAM dalam hampir semua bidang, dan prestasi keseluruhan SAT-Pro dan SAT-Nano adalah lebih baik daripada MedSAM. Walaupun SAT-Pro berprestasi lebih teruk daripada MedSAM pada lesi, Oracle Box sendiri menunjukkan prestasi yang cukup baik pada lesi sebagai ramalan, malah mengatasi MedSAM pada DSC. Ini menunjukkan bahawa prestasi unggul MedSAM dalam membahagikan lesi mungkin datang daripada maklumat terdahulu yang kukuh yang digesa oleh Box.
Jadual 3: Perbandingan ujian dalam domain SAT-Pro, SAT-Nano dan MedSAM, hasilnya disepadukan dalam unit kawasan atau lesi.

Perbandingan kualitatif: Rajah 6 memilih dua contoh tipikal daripada keputusan ujian dalam domain untuk paparan visual untuk membandingkan lagi SAT dan MedSAM. Seperti yang ditunjukkan dalam Rajah 6, dalam pembahagian miokardium, gesaan Kotak sukar untuk dibezakan antara miokardium dan ventrikel yang dibalut oleh miokardium, jadi MedSAM juga tersilap membahagikan kedua-duanya bersama-sama, yang menunjukkan bahawa gesaan Kotak berada dalam keadaan yang serupa. perhubungan spatial yang kompleks Ia adalah mudah untuk mempunyai kekaburan, yang membawa kepada pembahagian yang tidak tepat.
Sebaliknya, SAT berdasarkan gesaan teks (memasukkan secara langsung nama struktur anatomi) boleh membezakan dengan tepat antara miokardium dan ventrikel. Di samping itu, seperti yang dapat dilihat dalam segmentasi tumor usus yang ditunjukkan dalam Rajah 6, Oracle Box sudah pun merupakan hasil ramalan yang baik untuk sasaran lesi, manakala hasil segmentasi MedSAM mungkin tidak lebih baik daripada prompt Box yang diperolehi.
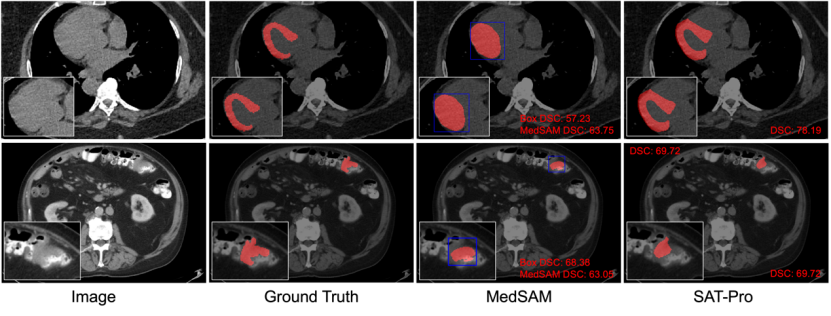
Rajah 6: Perbandingan kualitatif antara SAT-Pro dan MedSAM (Ketat). Antaranya, MedSAM menggunakan Kotak Oracle sebagai gesaan, dan Kotak ditandakan dengan warna biru. Baris pertama menunjukkan contoh pembahagian miokardium; baris kedua menunjukkan contoh pembahagian tumor usus.
Keputusan ujian luar domain: Seperti yang ditunjukkan dalam Jadual 2, berbanding dengan MedSAM (Ketat), SAT-Nano mengatasi MedSAM dalam 5 daripada 10 penunjuk dalam 5 set data. MedSAM (Loose) mempunyai kemerosotan prestasi yang jelas dalam semua penunjuk, menunjukkan bahawa MedSAM lebih sensitif terhadap offset gesaan Kotak yang dimasukkan oleh pengguna.
Eksperimen Ablasi
Apabila mereka bentuk SAT, rangkaian tulang belakang visual dan pengekod teks adalah dua bahagian utama Penyelidikan ini cuba menggunakan struktur rangkaian visual atau pengekod teks yang berbeza dalam rangka kerja SAT, dan eksperimen ablasi am untuk meneroka pengaruhnya.
Untuk menjimatkan kos percubaan, semua latihan dan ujian model SAT dalam eksperimen ablasi dilakukan pada SAT-DS-Nano yang mengandungi 49 set data, yang mengandungi 13303 imej 3D, 151461 anotasi segmentasi dan 429 kategori Split.
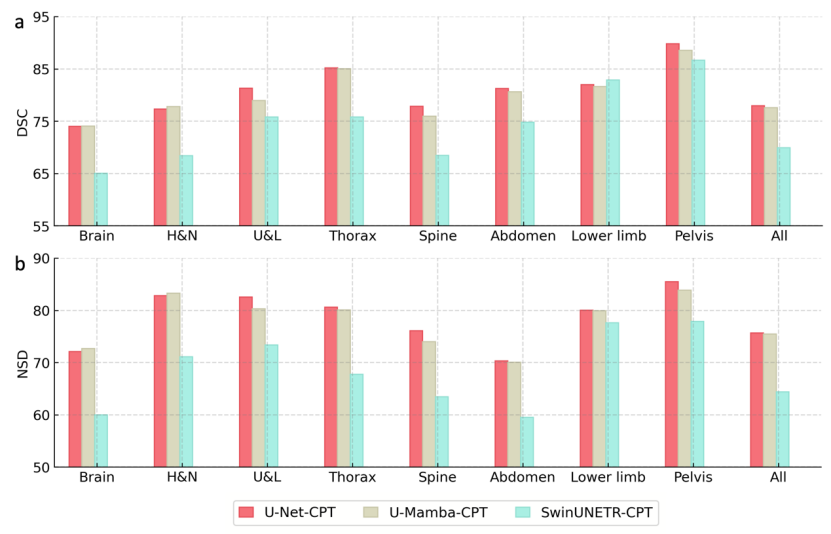
Rangkaian tulang belakang visual: Di bawah rangka kerja SAT-Nano, kajian ini memilih tiga struktur rangkaian segmentasi arus perdana untuk perbandingan, iaitu U-Net (110M parameter), SwinUNETR (107M parameter) dan U-Mamba (114M parameter) ). Untuk perbandingan yang saksama, amaun parameter yang mengawalnya dalam eksperimen ablasi ini adalah lebih kurang serupa. Pada masa yang sama, untuk mengira overhed, langkah suntikan pengetahuan ditinggalkan dan MedCPT digunakan secara langsung (MedCPT ialah pengekod teks berdasarkan literatur PubMed, dilatih menggunakan data klik pengguna peribadi 225M dan telah mencapai prestasi terbaik dalam satu siri tugas bahasa perubatan) kerana Pengekod teks menjana petunjuk. Tiga varian tersebut dicatatkan sebagai U-Net-CPT, SwinUNETR-CPT dan U-Mamba-CPT masing-masing.
Seperti yang anda lihat dari Rajah 7, menggunakan U-Net dan U-Mamba sebagai rangkaian tulang belakang visual, prestasi segmentasi akhir adalah agak hampir, dengan U-Net lebih baik sedikit daripada U-Mamba manakala prestasi segmentasi apabila menggunakan SwinUNETR adalah penurunan yang jauh lebih baik. Akhirnya, pasukan penyelidik memilih U-Net sebagai rangkaian tulang belakang visual untuk SAT.
Pengekod teks: Di bawah rangka kerja SAT-Nano, kajian ini memilih tiga pengekod teks perwakilan untuk perbandingan: pengekod teks yang dilatih menggunakan kaedah suntikan pengetahuan yang dicadangkan di atas (ditandakan sebagai milik Kami), The state-of-the-art pengekod teks perubatan MedCPT digunakan, dan pengekod teks BERT-base, yang tidak diperhalusi untuk data perubatan, digunakan.
Demi keadilan, percubaan ablasi ini secara seragam menggunakan U-Net sebagai rangkaian visual. Ketiga-tiga varian tersebut dicatatkan sebagai U-Net-Ours, U-Net-CPT dan U-Net-BB masing-masing. Seperti yang ditunjukkan dalam Rajah 8, secara keseluruhan, menggunakan MedCPT mempunyai sedikit peningkatan dalam prestasi segmentasi berbanding dengan menggunakan pangkalan BERT, menunjukkan bahawa pengetahuan domain membantu untuk memberikan petua segmentasi yang baik semasa menggunakan pengekod teks yang dicadangkan dalam kajian ini mempunyai Prestasi terbaik ialah dicapai dalam semua kategori, menunjukkan bahawa membina pangkalan pengetahuan anatomi manusia berbilang modal dan suntikan pengetahuan amat membantu untuk model segmentasi.

Pengedaran ekor panjang ialah ciri yang jelas bagi set data bersegmen. Seperti yang ditunjukkan dalam Rajah 9 a dan b, pasukan penyelidik menyiasat taburan bilangan anotasi 429 kategori dalam SAT-DS-Nano yang digunakan untuk eksperimen ablasi. Jika 10 kategori dengan bilangan anotasi terbesar (2.33%) teratas ditakrifkan sebagai kelas kepala, dan 150 kategori dengan bilangan anotasi paling sedikit (34.97%) terakhir ditakrifkan sebagai kelas ekor, boleh didapati bahawa bilangan anotasi untuk kelas ekor hanya menyumbang 3.25 daripada jumlah anotasi %.
Kajian ini meneroka lebih lanjut kesan pengekod teks ke atas hasil pembahagian kategori berbeza dalam pengedaran ekor panjang. Seperti yang ditunjukkan dalam Rajah 9c, pengekod yang dicadangkan oleh pasukan penyelidik mencapai prestasi terbaik dalam kategori kepala, ekor dan tengah, dengan peningkatan dalam kategori ekor lebih jelas daripada kategori kepala. Pada masa yang sama, MedCPT berprestasi lebih rendah sedikit daripada BERT-base pada kelas kepala, tetapi berprestasi lebih baik pada kelas ekor. Keputusan ini menunjukkan bahawa pengetahuan domain, terutamanya suntikan pengetahuan anatomi manusia berbilang modal, sangat membantu untuk pembahagian kategori ekor panjang.

Digabungkan dengan model bahasa yang besar
Memandangkan SAT boleh dibahagikan berdasarkan gesaan teks, ia boleh digunakan secara langsung sebagai alat proksi untuk model bahasa besar untuk menyediakan keupayaan pembahagian. Untuk menunjukkan senario aplikasi, pasukan penyelidik memilih 4 data klinikal sebenar yang pelbagai, menggunakan GPT4 untuk mengekstrak sasaran pembahagian daripada laporan dan dipanggil SAT untuk pembahagian pukulan sifar. Keputusan ditunjukkan dalam Rajah 10.
Seperti yang anda lihat, GPT-4 boleh mengesan struktur anatomi penting dalam laporan dengan sangat baik, dan memanggil SAT untuk membahagikannya dengan baik pada imej klinikal sebenar tanpa sebarang penalaan data.

Nilai penyelidikan
Sebagai model segmentasi umum berskala besar pertama bagi imej perubatan 3D berdasarkan gesaan teks, nilai SAT dicerminkan dalam banyak aspek:
SAT membina pembahagian sejagat yang cekap dan fleksibel: SAT-Pro hanya menggunakan satu model, menunjukkan prestasi setanding dengan 72 nnU-Nets pada pelbagai tugas pembahagian, dan mempunyai jumlah parameter model yang lebih kecil. Ini menunjukkan bahawa berbanding dengan kaedah segmentasi perubatan tradisional yang memerlukan konfigurasi, latihan dan penggunaan siri model khusus, SAT-Pro sebagai model segmentasi umum ialah penyelesaian yang lebih fleksibel dan cekap. Pada masa yang sama, pasukan penyelidik juga membuktikan bahawa SAT-Pro mempunyai prestasi generalisasi yang lebih baik pada data luar wilayah dan boleh memenuhi keperluan klinikal dengan lebih baik seperti migrasi merentas pusat.
SAT ialah model asas berdasarkan pra-latihan data segmentasi berskala besar: Selepas SAT-Pro dilatih pada set data segmentasi berskala besar, ia menunjukkan peningkatan prestasi yang ketara apabila dipindahkan ke set data tertentu melalui fine- penalaan , dan berprestasi lebih baik secara keseluruhan daripada nnU-Nets. Ini menunjukkan bahawa SAT boleh dianggap sebagai model segmentasi asas yang berkuasa yang boleh melakukan lebih baik pada tugas tertentu melalui pemindahan yang diperhalusi, dengan itu mengimbangi keperluan klinikal bagi segmentasi tujuan umum dan segmentasi khusus.
SAT mencapai segmentasi yang tepat dan mantap berdasarkan gesaan teks: Berbanding dengan model segmentasi interaktif berdasarkan gesaan Kotak, SAT berdasarkan gesaan teks boleh mencapai hasil segmentasi yang lebih tepat dan teguh serta boleh menjimatkan pengguna Ia memerlukan banyak masa masa untuk melukis kotak, dengan itu mencapai pembahagian sejagat automatik dan didayakan kelompok.
SAT boleh digunakan sebagai alat proksi untuk model bahasa besar: Pasukan penyelidik menunjukkan pada data klinikal sebenar bahawa SAT boleh disambungkan dengan lancar dengan model bahasa besar, menggunakan teks sebagai jambatan untuk menyediakan keupayaan pembahagian dan kedudukan secara langsung untuk mana-mana model bahasa yang besar. Ini amat bernilai untuk menggalakkan lagi pembangunan Kecerdasan Buatan Perubatan Generalist.
Impak saiz model pada segmentasi: Dengan melatih dua model saiz berbeza: SAT-Nano dan SAT-Pro, kajian ini mendapati bahawa SAT-Pro mempunyai peningkatan yang ketara berbanding SAT-Nano dalam ujian dalam domain . Ini menunjukkan bahawa undang-undang penskalaan masih terpakai apabila melatih model segmentasi umum pada set data berskala besar.
Impak pengetahuan domain pada segmentasi: Pasukan penyelidik mencadangkan pangkalan pengetahuan anatomi manusia pelbagai mod yang pertama dan meneroka menggunakan peningkatan pengetahuan untuk meningkatkan prestasi model segmentasi umum, terutamanya segmentasi kategori ekor panjang. Memandangkan anotasi pembahagian, terutamanya anotasi pada kategori ekor panjang, agak terhad, penerokaan ini amat penting untuk membina model segmentasi umum.
Atas ialah kandungan terperinci Model besar perubatan 3D sumber terbuka SAT menyokong 497 organoid dan mempunyai prestasi melebihi 72 nnU-Nets Ia dikeluarkan oleh pasukan Universiti Shanghai Jiao Tong.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI