
Rumah >Peranti teknologi >AI >ACL 2024 |. Penyelidikan audiovisual akademik terkemuka, Universiti Jiao Tong Shanghai, Universiti Tsinghua, Universiti Cambridge dan Shanghai AILAB bersama-sama mengeluarkan set data audiovisual akademik M3AV
ACL 2024 |. Penyelidikan audiovisual akademik terkemuka, Universiti Jiao Tong Shanghai, Universiti Tsinghua, Universiti Cambridge dan Shanghai AILAB bersama-sama mengeluarkan set data audiovisual akademik M3AV

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-07-12 04:11:471189semak imbas

Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

Pautan kertas: https://arxiv.org/abs/2403.14168 -
Laman utama projek: https://jack-zc8.github.io/M3AV Tajuk kertas: M3AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Akademik Dataset pengetahuan Kaedah dalam talian. Video ini mengandungi maklumat multimodal yang kaya, termasuk suara pembesar suara, ekspresi muka dan pergerakan badan, teks dan imej dalam slaid dan maklumat teks kertas yang sepadan. Pada masa ini terdapat sangat sedikit set data yang boleh menyokong pengecaman kandungan berbilang mod secara serentak dan tugas pemahaman - , sebahagiannya disebabkan oleh kekurangan anotasi manusia yang berkualiti tinggi.
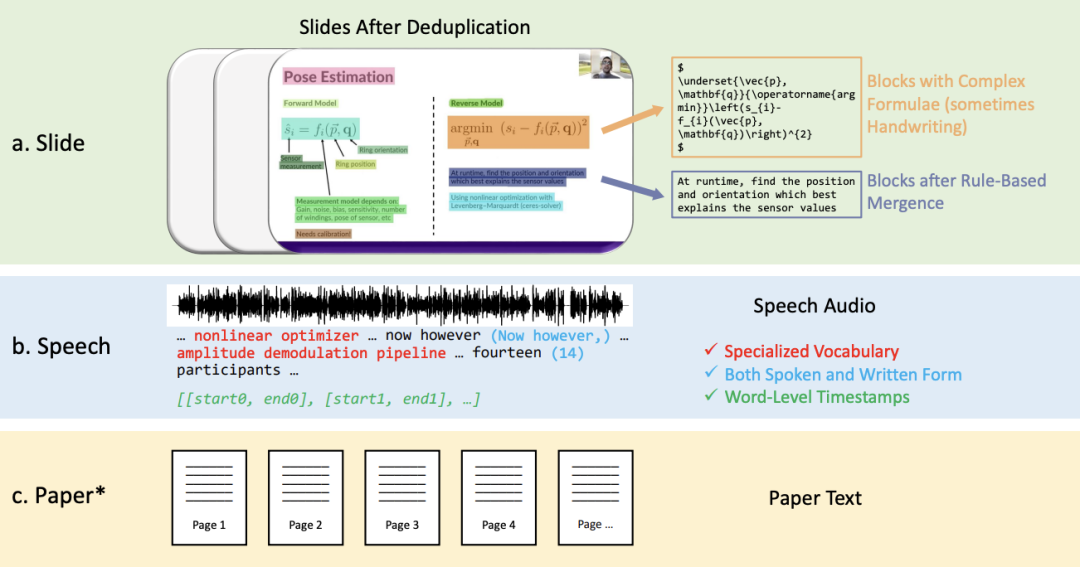
2. Teks transkripsi pertuturan dalam bentuk lisan dan bertulis, termasuk kosa kata khas dan cap masa peringkat perkataan.
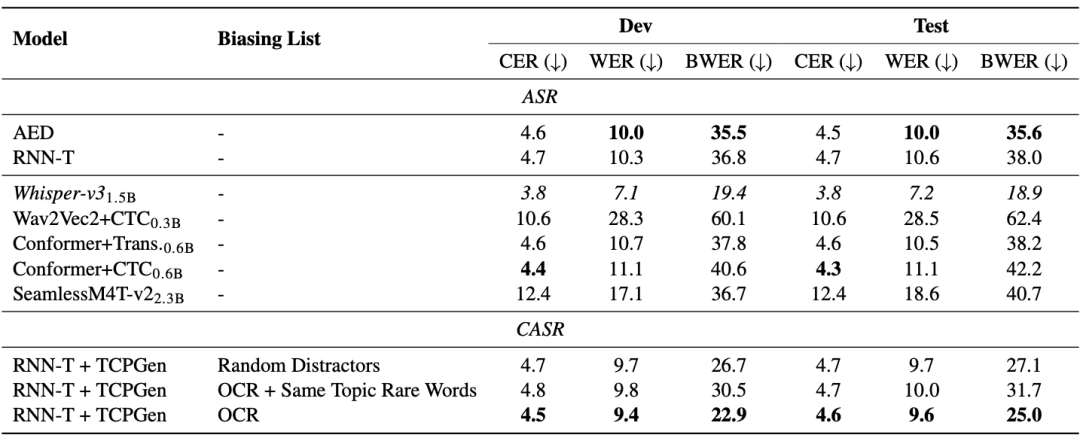
Tugas Penjanaan Slaid dan Skrip (SSG) direka untuk mempromosikan pemahaman model AI dan membina semula proses penyelidikan akademik dengan cepat, dengan itu membantu proses penyelidikan akademik yang lebih maju mengulang bahan akademik untuk menjalankan penyelidikan akademik dengan berkesan. 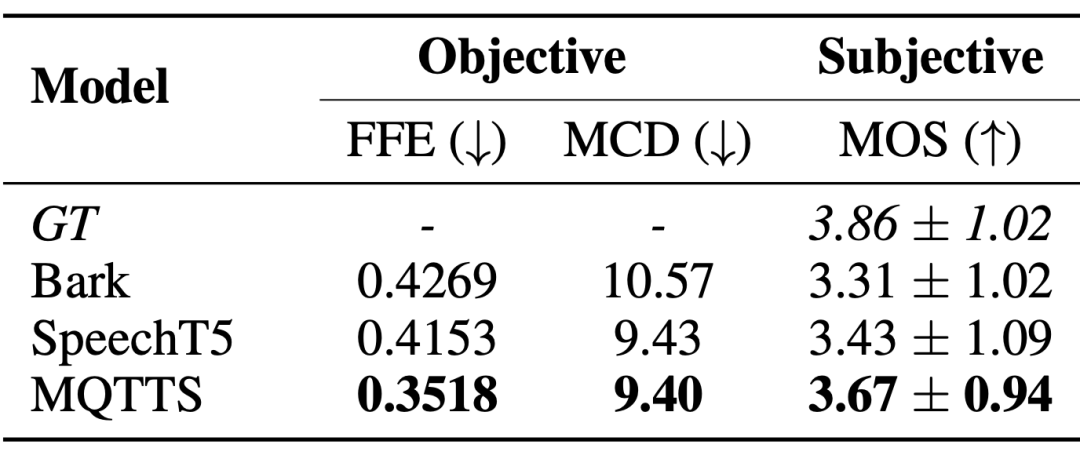
Selain itu, Retrieval Enhanced Generation (RAG) meningkatkan prestasi model dengan berkesan: Jadual di bawah menunjukkan bahawa teks kertas yang diperkenalkan juga meningkatkan kualiti slaid dan skrip yang dihasilkan.
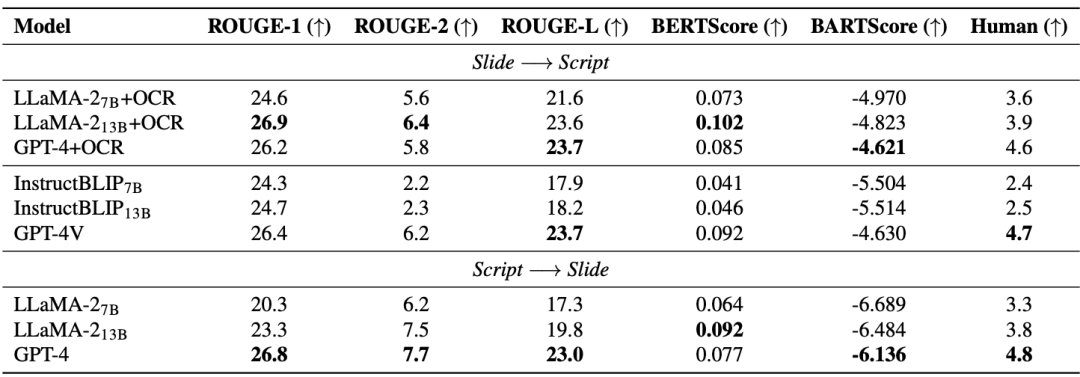
Kerja ini mengeluarkan set data audiovisual (M3AV) pelbagai mod, pelbagai jenis, pelbagai guna yang merangkumi pelbagai bidang akademik. Set data mengandungi transkripsi pertuturan beranotasi manusia, slaid dan teks esei tambahan yang diekstrak, menyediakan asas untuk menilai keupayaan model AI untuk mengenali kandungan multimodal dan memahami pengetahuan akademik. Penulis kertas itu menerangkan proses penciptaan secara terperinci dan menjalankan pelbagai analisis pada set data. Tambahan pula, mereka membina penanda aras dan menjalankan berbilang eksperimen di sekitar set data. Akhirnya, pengarang kertas kerja mendapati bahawa model sedia ada masih mempunyai ruang untuk penambahbaikan dalam memahami dan memahami video kuliah akademik. 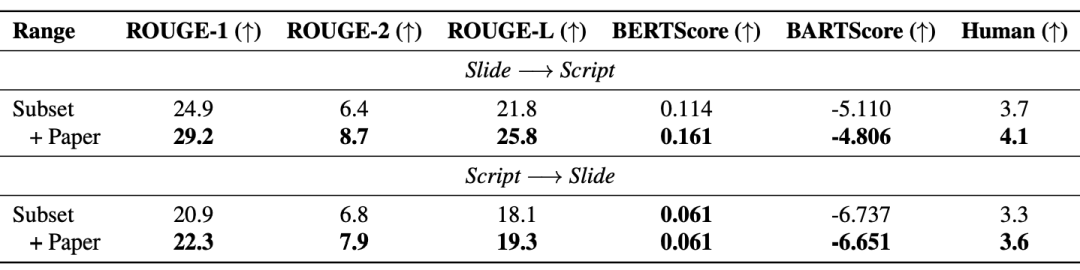
Atas ialah kandungan terperinci ACL 2024 |. Penyelidikan audiovisual akademik terkemuka, Universiti Jiao Tong Shanghai, Universiti Tsinghua, Universiti Cambridge dan Shanghai AILAB bersama-sama mengeluarkan set data audiovisual akademik M3AV. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI