
Rumah >Peranti teknologi >AI >Molekul adalah 100% berkesan, ligan direka dari awal, dan Universiti Hunan mencadangkan rangka kerja pencirian molekul berasaskan serpihan
Molekul adalah 100% berkesan, ligan direka dari awal, dan Universiti Hunan mencadangkan rangka kerja pencirian molekul berasaskan serpihan

- PHPzasal
- 2024-07-11 16:12:59651semak imbas
Aplikasi dan cabaran deskriptor molekul
Deskriptor molekul digunakan secara meluas dalam pemodelan molekul. Walau bagaimanapun, dalam bidang penemuan molekul berbantukan AI, terdapat kekurangan perwakilan molekul yang boleh digunakan secara semula jadi, lengkap dan asli, yang menjejaskan prestasi model dan kebolehtafsiran.
Cadangan rangka kerja t-SMILES
Rangka kerja pencirian molekul pelbagai skala berasaskan serpihan t-SMILES menyelesaikan masalah pencirian molekul. Rangka kerja menggunakan rentetan jenis SMILES untuk menerangkan molekul dan menyokong model jujukan sebagai model generatif. Algoritma kod
t-SMILES
t-SMILES mempunyai tiga algoritma kod: TSSA, TSDY dan TSID.
Hasil eksperimen
Eksperimen menunjukkan bahawa molekul yang dihasilkan oleh model t-SMILES mempunyai 100% kesahan teori dan kebaharuan yang tinggi, yang lebih baik daripada model berdasarkan SOTA SMILES.
Selain itu, model t-SMILES mengelakkan pemasangan berlebihan dan mengekalkan persamaan pada set data sumber rendah berlabel sambil mencapai kebaharuan yang lebih tinggi.
Maklumat yang diterbitkan
Kajian yang bertajuk "t-SMILES: rangka kerja perwakilan molekul berasaskan serpihan untuk reka bentuk ligan de novo", telah diterbitkan dalam "Nature Communications" pada 11 Jun.

Penyelidikan kaedah perwakilan molekul berdasarkan SMILES
Pencirian molekul yang berkesan adalah faktor utama yang mempengaruhi prestasi tiruan model kecerdasan.
Graph Neural Networks (GNN) terkenal kerana keupayaannya menjana 100% molekul cekap, tetapi keupayaan ekspresifnya adalah terhad.
Spesifikasi Input Linear Molekul Ringkas (SENYUM), sebagai perwakilan linear, cenderung untuk menghasilkan rentetan yang tidak sah secara kimia. DeepSMILES dan SELFIES adalah penambahbaikan sebagai alternatif, tetapi masih mempunyai masalah.
Selain itu, penyelidikan menunjukkan bahawa model bahasa (LM) mungkin mengatasi kebanyakan GNN dalam mempelajari molekul yang besar dan kompleks. Baru-baru ini, LM berdasarkan Transformers telah menunjukkan keupayaan mereka untuk menjana teks yang hampir menyerupai tulisan manusia.
Diilhamkan oleh idea-idea ini, para penyelidik memilih SMILES sebagai pilihan permulaan untuk penerangan serpihan, dan digabungkan dengan teknologi pemprosesan bahasa semula jadi yang canggih untuk mengendalikan tugas pemodelan molekul berasaskan serpihan, yang boleh menggabungkan model graf untuk memberi lebih perhatian kepada topologi molekul dan LM Kelebihan keupayaan pembelajaran yang kuat.
Menghasilkan 100% molekul baru yang berkesan, lebih baik daripada SOTA
Oleh itu, pasukan Universiti Hunan mencadangkan rangka kerja perihalan molekul baharu berdasarkan molekul pecahan, t-SMILES (SENYUMAN berasaskan pokok). Rangka kerja ini mengandungi tiga algoritma pengekodan t-SMILES: TSSA (t-SMILES dengan atom yang dikongsi), TSDY (t-SMILES dengan atom maya tetapi bukan ID) dan TSID (t-SMILES dengan ID dan atom maya).

Rangka kerja t-SMILES yang baru dicadangkan
- menjana molekul molekul acyclic.MT (Acyclic molekular trees).
- Tukar AMT kepada pokok binari penuh (FBT).
- Lakukan lintasan pertama luas di FBT untuk mendapatkan rentetan t-SMILES.
Berbanding dengan SMILES
t-SMILES hanya memperkenalkan dua simbol baharu "&" dan "^" untuk mengekod topologi molekul berskala dan hierarki. Algoritma
t-SMILES
menyediakan rangka kerja berskala dan boleh disesuaikan yang secara teorinya boleh menyokong pelbagai skema substruktur.
Model berasaskan t-SMILES
dapat mempelajari maklumat struktur topologi peringkat tinggi sambil memproses maklumat substruktur terperinci.
Sistem berbilang kod
t-SMILES algoritma boleh membina sistem berbilang kod untuk penerangan molekul, di mana:
- Classic SMILES boleh disepadukan sebagai kes khas t-SMILES (TS_Vanilla).
- Berbilang penerangan boleh bekerjasama untuk meningkatkan prestasi keseluruhan.
Ilustrasi: pengedaran token untuk kod TSSA, SMILES dan SELFIES. (Sumber: kertas)
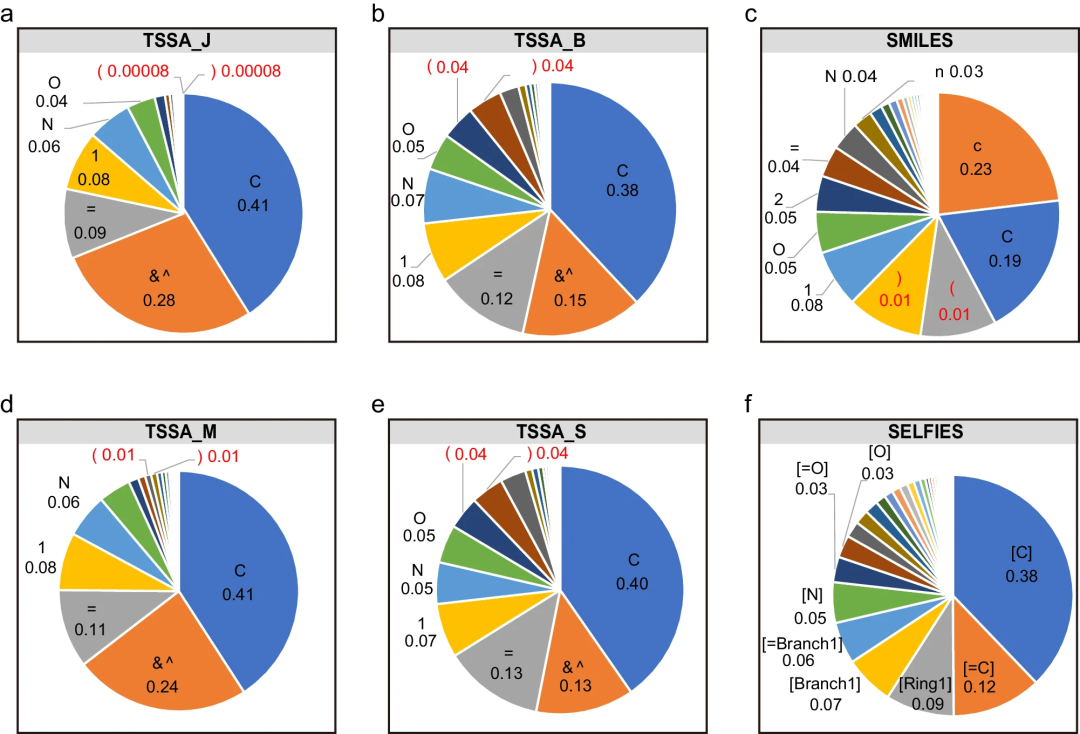
Pertama, para penyelidik secara sistematik menilai t-SENYUM dengan menyelidiki ciri uniknya. Selepas itu, eksperimen telah dijalankan menggunakan TSSA dan TSDY pada dua set data sumber rendah berlabel, JNK332 dan AID170633.
Penyelidikan memfokuskan pada batasan t-SMILES dan alternatifnya, yang dicapai dengan memanfaatkan standard, penambahan data dan model yang telah ditala halus yang telah dilatih. Dua puluh tugas terarah matlamat pada ChEMBL dinilai secara selari menggunakan TSDY, TSSA, dan TSID. Eksperimen menyeluruh juga dilakukan pada ChEMBL, Zink, dan QM9 untuk membandingkan t-SMILES dan alternatifnya dengan menggunakan persediaan yang serupa. Tambahan pula, pelbagai model garis dasar berasaskan serpihan dan model SOTA GNN dibandingkan.
Akhir sekali, kajian ablasi dilakukan untuk mengesahkan keberkesanan model generatif berdasarkan SMILES dengan pembinaan semula. Untuk menilai kebolehsuaian dan fleksibiliti algoritma t-SMILES, empat algoritma pemecahan yang diterbitkan sebelum ini digunakan untuk menguraikan molekul, termasuk JTVAE, BRICS, MMPA dan Scaffold. Tiga metrik telah digunakan dalam eksperimen yang berbeza: penanda aras pembelajaran teragih, penanda aras terarah matlamat dan metrik jarak Wasserstein untuk sifat fizikokimia.
Eksperimen perbandingan terperinci menunjukkan bahawa molekul baharu yang dihasilkan oleh model t-SMILES adalah 100% sah secara teori dan lebih baik daripada model berdasarkan SOTA SMILES. Berbanding dengan SMILES, DSMILES dan SELFIES, penyelesaian keseluruhan t-SMILES boleh mengelakkan masalah overfitting dan meningkatkan prestasi seimbang dengan ketara pada set data sumber rendah, sama ada menggunakan penambahan data atau model pra-latihan dan kemudian diperhalusi.
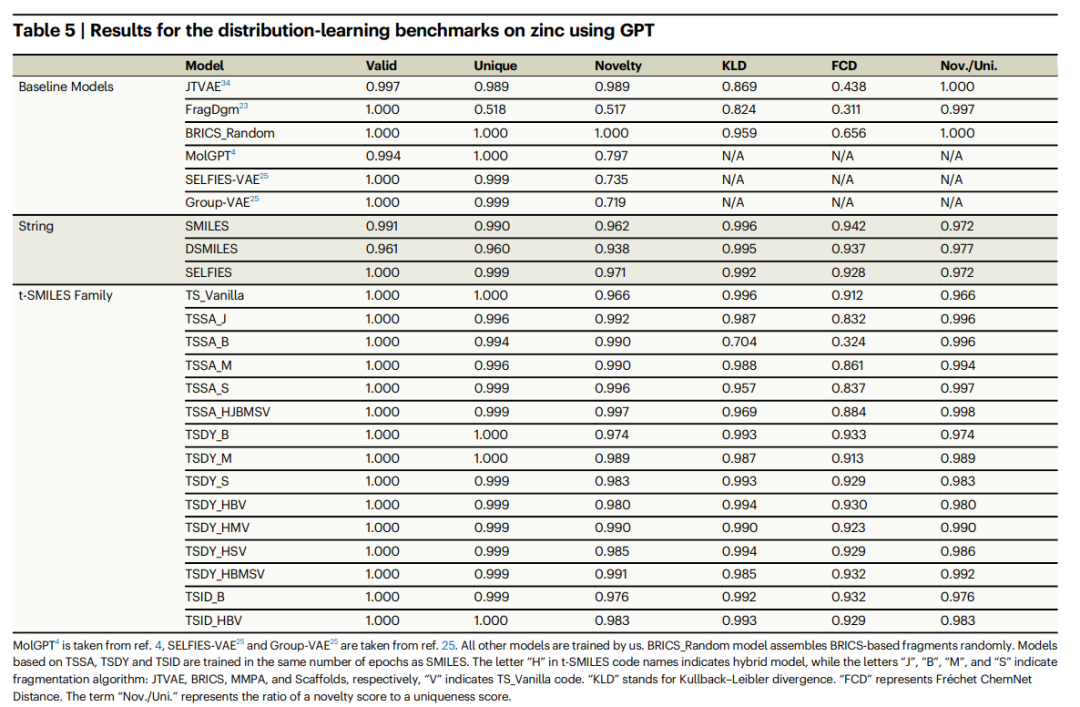
Selain itu, model t-SMILES mampu menangkap dengan mahir sifat fizikokimia molekul, memastikan molekul yang dihasilkan mengekalkan persamaan dengan pengedaran molekul latihan. Ini meningkatkan prestasi dengan ketara berbanding model asas berasaskan serpihan dan berasaskan graf sedia ada. Khususnya, model t-SMILES dengan algoritma pembinaan semula berorientasikan matlamat menunjukkan kelebihan yang jelas berbanding SMILES, DSMILES, SELFIES dan SOTA CReM dalam tugasan berorientasikan matlamat.
Keterbatasan dan Kawasan untuk Penambahbaikan
- LLM boleh memahami tatabahasa Inggeris yang diformat dengan baik. Oleh itu, sama ada struktur pokok t-SMILES boleh dipelajari dan bagaimana LM boleh melangkaui korelasi statistik permukaan untuk mempelajari pengetahuan kimia molekul masih perlu diterokai secara mendalam.
- Penyelidikan ini memfokuskan pada pengekodan molekul berpecah-belah ke dalam urutan, jadi hanya algoritma pemecahan yang diterbitkan digunakan sebagai contoh untuk mencipta "perkataan kimia". Penyelidikan masa depan boleh memanfaatkan t-SMILES untuk meneroka algoritma pemecahan lain untuk mentafsir ayat dan makna kimia dengan lebih mendalam, yang sebenarnya lebih mencabar daripada NLP.
- Walaupun t-SMILES direka untuk meningkatkan prestasi huraian molekul dan memintas batasan SMILES, kajian itu tidak bereksperimen dengan molekul yang lebih kompleks. Ini akan menjadi subjek kajian masa depan.
- Akhir sekali, ini adalah permulaan yang menjanjikan untuk mengekodkan molekul yang berpecah kepada rentetan jenis SMILES. Penyelidikan lanjut boleh meneroka algoritma lanjutan untuk pembinaan semula dan pengoptimuman molekul, model generatif yang dipertingkatkan dan teknik evolusi. Selain itu, penyelidikan boleh menumpukan pada sifat, retrosintesis dan tugas ramalan tindak balas.
Nota: Sampulnya datang dari Internet
Atas ialah kandungan terperinci Molekul adalah 100% berkesan, ligan direka dari awal, dan Universiti Hunan mencadangkan rangka kerja pencirian molekul berasaskan serpihan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI