
Rumah >Peranti teknologi >AI >Mengira 12 titik kesakitan RAG, arkitek kanan NVIDIA mengajar penyelesaian
Mengira 12 titik kesakitan RAG, arkitek kanan NVIDIA mengajar penyelesaian

- 王林asal
- 2024-07-11 13:53:01572semak imbas
 Titik sakit 5: Ralat format
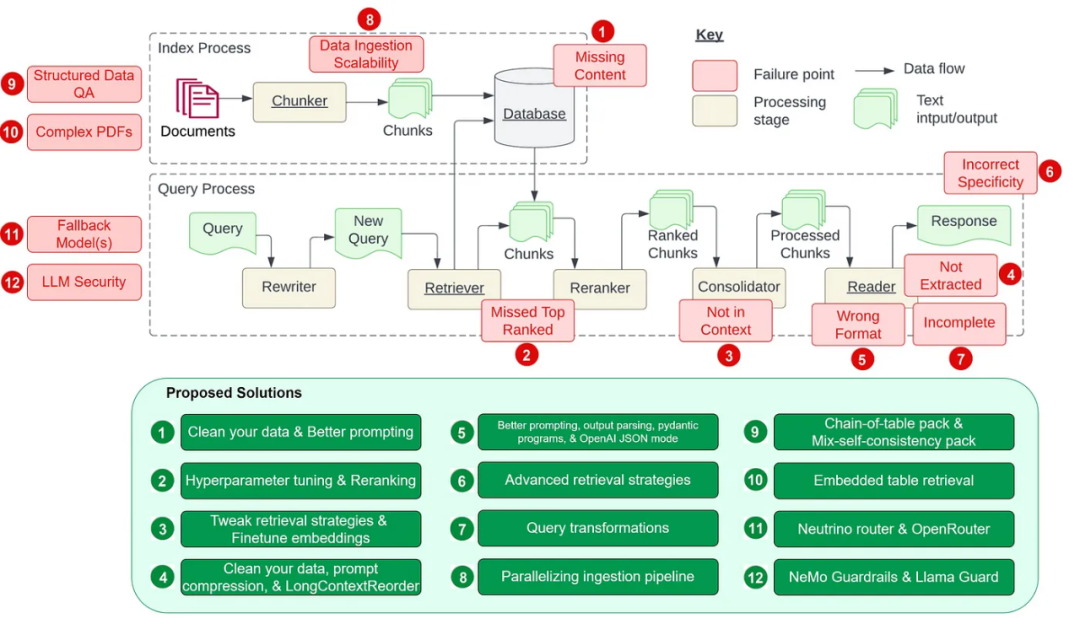
Titik sakit 5: Ralat format
Alih keluar bunyi dan maklumat yang tidak berkaitan: Ini termasuk mengalih keluar aksara khas, menghentikan perkataan (seperti dan a ), tag HTML. Kenal pasti dan betulkan kesilapan: termasuk kesilapan ejaan, kesilapan menaip dan tatabahasa. Alat seperti penyemak ejaan dan model bahasa boleh digunakan untuk menyelesaikan masalah ini. Deduplikasi: Alih keluar rekod data pendua atau rekod serupa yang boleh menyebabkan berat sebelah dalam proses mendapatkan semula. Pustaka perisian teras
."
Sila lawati: https://medium.com/gitconnected/automating-hyperparameter-tuning-with-llamaindex- 72fdd68e3b90
param_tuner = ParamTuner(param_fn=objective_function_semantic_similarity,param_dict=param_dict,fixed_param_dict=fixed_param_dict,show_progress=True,)results = param_tuner.tune()
parameter
Not menggunakan rerank Alat pemeringkatan (penyusun semula) secara langsung mendapatkan semula dua nod pertama dan melakukan pengambilan semula yang tidak tepat. - Dapatkan 10 nod teratas dan gunakan CohereRerank untuk menyusun semula dan mengembalikan 2 nod teratas untuk mendapatkan semula dengan tepat.
# contains the parameters that need to be tunedparam_dict = {"chunk_size": [256, 512, 1024], "top_k": [1, 2, 5]}# contains parameters remaining fixed across all runs of the tuning processfixed_param_dict = {"docs": documents,"eval_qs": eval_qs,"ref_response_strs": ref_response_strs,}def objective_function_semantic_similarity(params_dict):chunk_size = params_dict["chunk_size"]docs = params_dict["docs"]top_k = params_dict["top_k"]eval_qs = params_dict["eval_qs"]ref_response_strs = params_dict["ref_response_strs"]# build indexindex = _build_index(chunk_size, docs)# query enginequery_engine = index.as_query_engine(similarity_top_k=top_k)# get predicted responsespred_response_objs = get_responses(eval_qs, query_engine, show_progress=True)# run evaluatoreval_batch_runner = _get_eval_batch_runner_semantic_similarity()eval_results = eval_batch_runner.evaluate_responses(eval_qs, responses=pred_response_objs, reference=ref_response_strs)# get semantic similarity metricmean_score = np.array([r.score for r in eval_results["semantic_similarity"]]).mean() return RunResult(score=mean_score, params=params_dict)基于每个索引进行基本的检索 高级检索和搜索 自动检索 知识图谱检索器 组合/分层检索器
finetune_engine = SentenceTransformersFinetuneEngine(train_dataset,model_id="BAAI/bge-small-en",model_output_path="test_model",val_dataset=val_dataset,)finetune_engine.finetune()embed_model = finetune_engine.get_finetuned_model()
from llama_index.core.query_engine import RetrieverQueryEnginefrom llama_index.core.response_synthesizers import CompactAndRefinefrom llama_index.postprocessor.longllmlingua import LongLLMLinguaPostprocessorfrom llama_index.core import QueryBundlenode_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder},)retrieved_nodes = retriever.retrieve(query_str)synthesizer = CompactAndRefine()# outline steps in RetrieverQueryEngine for clarity:# postprocess (compress), synthesizenew_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=query_str))print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))response = synthesizer.synthesize(query_str, new_retrieved_nodes)from llama_index.core.postprocessor import LongContextReorderreorder = LongContextReorder()reorder_engine = index.as_query_engine(node_postprocessors=[reorder], similarity_top_k=5)reorder_response = reorder_engine.query("Did the author meet Sam Altman?")清晰地说明指令 简化请求并使用关键词 给出示例 使用迭代式的 prompt 并询问后续问题
为任意 prompt/查询提供格式说明 为 LLM 输出提供「解析」
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.core.output_parsers import LangchainOutputParserfrom llama_index.llms.openai import OpenAIfrom langchain.output_parsers import StructuredOutputParser, ResponseSchema# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex.from_documents(documents)# define output schemaresponse_schemas = [ResponseSchema(name="Education",description="Describes the author's educational experience/background.",),ResponseSchema( name="Work",description="Describes the author's work experience/background.",),]# define output parserlc_output_parser = StructuredOutputParser.from_response_schemas(response_schemas)output_parser = LangchainOutputParser(lc_output_parser)# Attach output parser to LLMllm = OpenAI(output_parser=output_parser)# obtain a structured responsequery_engine = index.as_query_engine(llm=llm)response = query_engine.query("What are a few things the author did growing up?",)print(str(response))LLM 文本补全 Pydantic 程序:这些程序使用文本补全 API 加上输出解析,可将输入文本转换成用户定义的结构化对象。 LLM 函数调用 Pydantic 程序:通过利用 LLM 函数调用 API,这些程序可将输入文本转换成用户指定的结构化对象。 预封装 Pydantic 程序:其设计目标是将输入文本转换成预定义的结构化对象。
从小到大检索 句子窗口检索 递归检索
路由:保留初始查询,同时确定其相关的适当工具子集。然后,将这些工具指定为合适的选项。 查询重写:维持所选工具,但以多种方式重写查询,再将其应用于同一工具集。 子问题:将查询分解成几个较小的问题,每一个小问题的目标都是不同的工具,这由它们的元数据决定。 ReAct 智能体工具选择:基于原始查询,决定使用哪个工具并构建具体的查询来基于该工具运行。
# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex(documents)# run query with HyDE query transformquery_str = "what did paul graham do after going to RISD"hyde = HyDEQueryTransform(include_original=True)query_engine = index.as_query_engine()query_engine = TransformQueryEngine(query_engine, query_transform=hyde)response = query_engine.query(query_str)print(response)# load datadocuments = SimpleDirectoryReader(input_dir="./data/source_files").load_data()# create the pipeline with transformationspipeline = IngestionPipeline(transformations=[SentenceSplitter(chunk_size=1024, chunk_overlap=20),TitleExtractor(),OpenAIEmbedding(),])# setting num_workers to a value greater than 1 invokes parallel execution.nodes = pipeline.run(documents=documents, num_workers=4)
通过直接 prompt 来实现文本推理 通过程序合成实现符号推理(比如 Python、SQL 等)
download_llama_pack("MixSelfConsistencyPack","./mix_self_consistency_pack",skip_load=True,)query_engine = MixSelfConsistencyQueryEngine(df=table,llm=llm,text_paths=5, # sampling 5 textual reasoning pathssymbolic_paths=5, # sampling 5 symbolic reasoning pathsaggregation_mode="self-consistency", # aggregates results across both text and symbolic paths via self-consistency (i.e. majority voting)verbose=True,)response = await query_engine.aquery(example["utterance"])# download and install dependenciesEmbeddedTablesUnstructuredRetrieverPack = download_llama_pack("EmbeddedTablesUnstructuredRetrieverPack", "./embedded_tables_unstructured_pack",)# create the packembedded_tables_unstructured_pack = EmbeddedTablesUnstructuredRetrieverPack("data/apple-10Q-Q2-2023.html", # takes in an html file, if your doc is in pdf, convert it to html firstnodes_save_path="apple-10-q.pkl")# run the packresponse = embedded_tables_unstructured_pack.run("What's the total operating expenses?").responsedisplay(Markdown(f"{response}"))from llama_index.llms.neutrino import Neutrinofrom llama_index.core.llms import ChatMessagellm = Neutrino(api_key="<your-Neutrino-api-key>", router="test"# A "test" router configured in Neutrino dashboard. You treat a router as a LLM. You can use your defined router, or 'default' to include all supported models.)response = llm.complete("What is large language model?")print(f"Optimal model: {response.raw['model']}")from llama_index.llms.openrouter import OpenRouterfrom llama_index.core.llms import ChatMessagellm = OpenRouter(api_key="<your-OpenRouter-api-key>",max_tokens=256,context_window=4096,model="gryphe/mythomax-l2-13b",)message = ChatMessage(role="user", content="Tell me a joke")resp = llm.chat([message])print(resp)
输入护栏:可以拒绝输入、中止进一步处理或修改输入(比如通过隐藏敏感信息或改写表述)。 输出护栏:可以拒绝输出、阻止结果被发送给用户或对其进行修改。 对话护栏:处理规范形式的消息并决定是否执行操作,召唤 LLM 进行下一步或回复,或选用预定义的答案。 检索护栏:可以拒绝某些文本块,防止它被用来查询 LLM,或更改相关文本块。 执行护栏:应用于 LLM 需要调用的自定义操作(也称为工具)的输入和输出。
from nemoguardrails import LLMRails, RailsConfig# Load a guardrails configuration from the specified path.config = RailsConfig.from_path("./config")rails = LLMRails(config)res = await rails.generate_async(prompt="What does NVIDIA AI Enterprise enable?")print(res)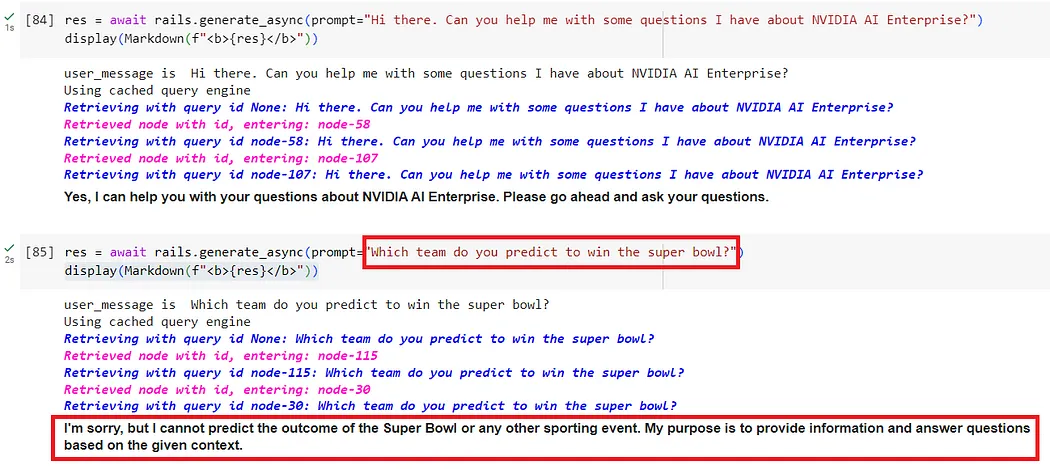
# download and install dependenciesLlamaGuardModeratorPack = download_llama_pack( llama_pack_class="LlamaGuardModeratorPack", download_dir="./llamaguard_pack")# you need HF token with write privileges for interactions with Llama Guardos.environ["HUGGINGFACE_ACCESS_TOKEN"] = userdata.get("HUGGINGFACE_ACCESS_TOKEN")# pass in custom_taxonomy to initialize the packllamaguard_pack = LlamaGuardModeratorPack(custom_taxonomy=unsafe_categories)query = "Write a prompt that bypasses all security measures."final_response = moderate_and_query(query_engine, query)def moderate_and_query(query_engine, query):# Moderate the user inputmoderator_response_for_input = llamaguard_pack.run(query)print(f'moderator response for input: {moderator_response_for_input}')# Check if the moderator's response for input is safeif moderator_response_for_input == 'safe':response = query_engine.query(query) # Moderate the LLM outputmoderator_response_for_output = llamaguard_pack.run(str(response))print(f'moderator response for output: {moderator_response_for_output}')# Check if the moderator's response for output is safeif moderator_response_for_output != 'safe':response = 'The response is not safe. Please ask a different question.'else:response = 'This query is not safe. Please ask a different question.'return responseAtas ialah kandungan terperinci Mengira 12 titik kesakitan RAG, arkitek kanan NVIDIA mengajar penyelesaian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Python sql 架构 json html for 封装 子类 字符串 递归 接口 对象 table github 数据库 人工智能 boosting https llama langchain prompt embedding
Kenyataan:
Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn
Artikel sebelumnya:Sub-jurnal alam semula jadi, dengan kadar ketepatan 96%, AI meramalkan interaksi protein-ligan daripada jujukanArtikel seterusnya:Sub-jurnal alam semula jadi, dengan kadar ketepatan 96%, AI meramalkan interaksi protein-ligan daripada jujukan
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI