Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Pengarang artikel ini ialah Profesor Zhang Peng dari Jabatan Perisikan dan Pengkomputeran Universiti Tianjin, pelajar sarjananya, Zhao Jiaming pelajar Qiao Wenbo dan Gao Jue. Kerja penyelidikan ini dibiayai oleh Yayasan Sains Semula Jadi Kebangsaan China dan Makmal Bersama Sains dan Teknologi Wenge Universiti Tianjin-China. . /2406.03873
-
Universiti Tianjin memperkenalkan pasukan Kecerdasan Kuantum dan Pemahaman Bahasa secara kuantitatif secara kuantitatif rangkaian perwakilan tersirat (Q
uantum
I
persembahan
). Berbanding dengan kaedah rangkaian neural klasik, kaedah ini mempunyai keupayaan perwakilan isyarat yang lebih kuat secara eksponen dalam teori. Keputusan eksperimen juga mengesahkan bahawa QIREN sememangnya mempamerkan prestasi cemerlang melebihi model SOTA pada tugas perwakilan isyarat Dengan parameter yang lebih sedikit, ralat pemasangan dikurangkan sehingga 35%. Rajah 1 menunjukkan idea teras dan kesimpulan utama kertas ini.
Kertas kerja berkaitan telah diterima oleh ICML 2024, salah satu persidangan paling berwibawa dalam bidang pembelajaran mesin.傅 Rajah 1. Rangkaian neural Fourier Klasik dan rangkaian neural Fourier kuantum.
Dalam beberapa tahun kebelakangan ini, perwakilan saraf tersirat telah menarik perhatian meluas sebagai kaedah perwakilan isyarat yang muncul. Perwakilan saraf tersirat mempunyai beberapa kelebihan unik berbanding perwakilan grid diskret tradisional, seperti imej yang diwakili oleh grid piksel. Pertama, ia mempunyai keupayaan "resolusi tak terhingga" dan boleh mengambil sampel pada mana-mana resolusi spatial. Kedua, perwakilan saraf tersirat mempunyai penjimatan ruang storan yang sangat baik dan memberikan kemudahan untuk penyimpanan data. Disebabkan kelebihan unik ini, perwakilan saraf tersirat dengan cepat menjadi paradigma arus perdana untuk mewakili isyarat seperti imej, objek dan pemandangan 3D. Kebanyakan penyelidikan awal mengenai perwakilan saraf tersirat dibina pada perceptron berbilang lapisan (MLPs) berasaskan ReLU. Walau bagaimanapun, adalah sukar untuk MLP berasaskan ReLU untuk memodelkan bahagian isyarat frekuensi tinggi dengan tepat, seperti yang ditunjukkan dalam Rajah 2. Penyelidikan terkini telah mula meneroka penggunaan rangkaian saraf Fourier (FNN) untuk mengatasi batasan ini. Walau bagaimanapun, dalam menghadapi tugas pemasangan yang semakin kompleks dalam aplikasi dunia sebenar, rangkaian saraf Fourier klasik juga memerlukan lebih banyak parameter latihan, yang meningkatkan permintaan untuk sumber pengkomputeran. Perwakilan neural tersirat kuantum yang dicadangkan dalam artikel ini mengambil kesempatan daripada kelebihan kuantum untuk mengurangkan parameter dan penggunaan pengiraan Penyelesaian ini boleh membawa inspirasi baharu kepada bidang perwakilan neural tersirat dan juga pembelajaran mesin. Rajah 2. Komponen kekerapan yang berbeza dari imej sebenar (atas) dan komponen frekuensi yang berbeza dari imej yang dipasang oleh MLP berasaskan relu (bawah) 
Senibina keseluruhan model Qiren ditunjukkan dalam Rajah 3. terdiri daripada lapisan campuran N dan lapisan linear pada akhir. Model mengambil koordinat sebagai nilai isyarat input dan output. Data pada mulanya memasuki lapisan hibrid, bermula dengan lapisan Linear dan lapisan BatchNorm, menghasilkan: 
dan kemudian dimasukkan ke dalam QC litar kuantum muat naik semula data. Dalam Rajah 2 (b) dan (c), kami memberikan pelaksanaan khusus bagi lapisan parameter dan litar kuantum lapisan pengekodan. Lapisan parameter terdiri daripada blok bertindan K. Setiap blok mengandungi get spin yang digunakan pada setiap qubit, serta get CNOT yang disambungkan secara round-robin. Lapisan pengekodan menggunakan gerbang pada setiap qubit. Akhir sekali, kami mengukur nilai jangkaan keadaan kuantum berbanding dengan yang boleh diperhatikan. Keluaran litar kuantum diberikan oleh: 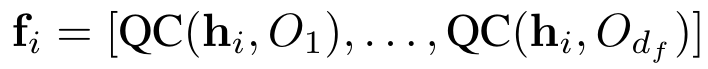
di mana O mewakili sebarang yang boleh diperhatikan. Output lapisan campuran ke-n akan digunakan sebagai input lapisan ke- (n+1). Akhir sekali, kami menambah lapisan linear untuk menerima dan mengeluarkan. Kami menggunakan ralat min kuasa dua (MSE) sebagai fungsi kehilangan untuk melatih model: 
Dalam beberapa kajian sebelum ini, sifat matematik litar kuantum muat naik semula data telah didedahkan pada dasarnya, litar kuantum muat naik semula data adalah sesuai dengan fungsi objektif dalam bentuk daripada siri Fourier. Walau bagaimanapun, kerja sebelumnya hanya meneroka litar qubit tunggal berbilang lapisan atau litar berbilang qubit satu lapisan, dan tidak membandingkan dengan kaedah klasik dan tidak menemui kelebihan litar kuantum memuat naik semula data. Kami melanjutkan penyelidikan kami kepada litar berbilang qubit berbilang lapisan. Di samping itu, kami telah membuktikan bahawa dalam bidang perwakilan saraf tersirat, rangkaian neural kuantum hibrid QIREN, yang menggunakan litar kuantum memuat semula data sebagai komponen terasnya, mempunyai kelebihan eksponen berbanding kaedah klasik. Kami menganalisis peranan lapisan kuantum dan lapisan klasik dalam QIREN dan meringkaskannya kepada tiga perkara berikut: 1 Di bawah keadaan optimum, keupayaan muat naik semula data untuk mewakili siri Fourier litar kuantum meningkat dengan litar Saiz berkembang secara eksponen. Lihat bahagian 4.2 dan 4.3 kertas untuk terbitan khusus. 2. Fungsi lapisan linear adalah untuk mengembangkan lagi spektrum dan melaraskan frekuensi, dengan itu meningkatkan prestasi pemasangan. Menggunakan lapisan linear sebelum memuat naik data ke litar kuantum adalah bersamaan dengan melaraskan nilai eigen dari lapisan pengekodan Hamiltonian, akhirnya menjejaskan spektrum. Pendekatan ini mempunyai dua kelebihan. Pertama, ia boleh menjadikan spektrum lebih besar. Beberapa istilah berlebihan dihasilkan dalam spektrum apabila pengekodan hanya dengan get. Lebihan ini boleh dikurangkan dengan menggunakan lapisan linear. Kedua, ia membolehkan liputan spektrum diselaraskan, bertujuan untuk meliputi frekuensi dengan pekali yang lebih besar yang lebih penting. Oleh itu, menambah lapisan linear boleh meningkatkan lagi prestasi pemasangan QIREN. 3. Peranan lapisan Batchnorm adalah untuk mempercepatkan penumpuan model kuantum. Dalam rangkaian neural suapan, data biasanya melalui lapisan BatchNorm sebelum fungsi pengaktifan, yang secara berkesan menghalang masalah kecerunan yang hilang. Begitu juga, dalam QIREN, litar kuantum menggantikan fungsi pengaktifan dan memainkan peranan dalam menyediakan ketaklinieran (litar kuantum itu sendiri adalah linear, tetapi proses memuat naik data klasik ke litar kuantum adalah tidak linear). Oleh itu, kami menambah lapisan BatchNorm di sini dengan tujuan menstabilkan dan mempercepatkan penumpuan model. Kami mengesahkan prestasi unggul QIREN dalam mewakili isyarat, terutamanya isyarat frekuensi tinggi, melalui perwakilan imej dan tugas perwakilan bunyi. Keputusan eksperimen ditunjukkan dalam Jadual 1. QIREN dan SIREN menunjukkan prestasi yang sama pada tugas perwakilan bunyi. Walaupun prestasi kedua-dua model nampaknya setanding, perlu ditekankan bahawa model kami mencapai 35.1% penjimatan memori dengan parameter paling sedikit, dan penumpuan SIREN memerlukan penetapan hiperparameter yang sesuai, manakala model kami tidak Sekatan ini. Kami kemudian menganalisis output model dari perspektif frekuensi. Kami menggambarkan spektrum keluaran model dalam Rajah 4. Adalah jelas bahawa output taburan frekuensi rendah oleh model adalah hampir dengan keadaan sebenar. Walau bagaimanapun, apabila ia berkaitan dengan pengagihan frekuensi tinggi, kedua-dua QIREN dan SIREN sesuai, diikuti oleh MLP berasaskan ReLU dengan ciri Fourier rawak (RFF). MLP berasaskan ReLU dan berasaskan Tanh malah tidak mempunyai bahagian isyarat frekuensi tinggi. 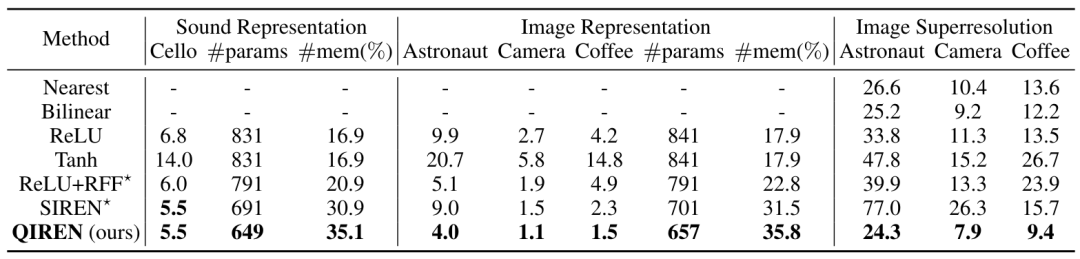
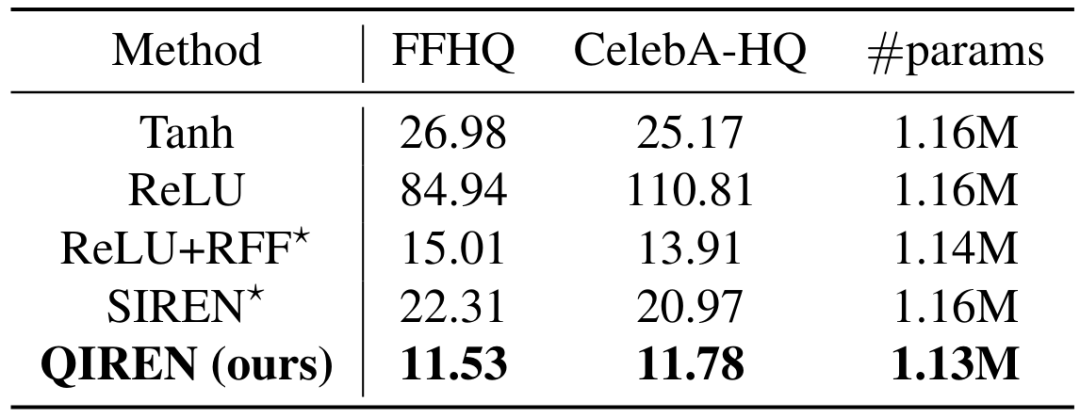
Jadual 1. MSE() model pada perwakilan isyarat dan tugas resolusi super imej. Model yang dianggap SOTA ditanda *. params mewakili jumlah parameter model, dan mem mewakili memori yang disimpan oleh model berbanding dengan perwakilan grid diskret.任 Rajah 4. Bunyi yang menunjukkan spektrum keluaran model dalam tugasan Qiren mencapai prestasi terbaik dalam tugas perwakilan imej Berbanding dengan model SOTA, ralat adalah Pengurangan maksimum ialah 34.8%. Untuk meneroka lebih lanjut keupayaan perwakilan isyarat model, kami menggunakan penapis untuk memisahkan komponen frekuensi tinggi dan frekuensi rendah outputnya dan membandingkan ralat pemasangan kedua-dua komponen ini masing-masing, dengan keputusan yang ditunjukkan dalam Rajah 5. QIREN secara konsisten mencapai ralat terendah apabila memasang komponen frekuensi tinggi dan rendah. . Ralat relatif setiap model berbanding dengan MLP berasaskan Tanh. Kawasan berlorek mewakili ralat frekuensi rendah, manakala kawasan tidak berlorek mewakili ralat frekuensi tinggi. Penyelidikan terkini memperkenalkan rangka kerja terobosan untuk melanjutkan perwakilan neural tersirat kepada penjanaan imej. Lebih khusus lagi, rangka kerja menggunakan hypernetwork yang mengambil pengagihan rawak sebagai input untuk menjana parameter yang mencirikan rangkaian secara tersirat. Selepas itu, parameter yang dijana ini diberikan kepada rangkaian perwakilan tersirat. Akhir sekali, rangkaian perwakilan tersirat menjana imej yang mengambil koordinat sebagai input. Pendekatan lawan digunakan untuk memastikan imej yang dihasilkan adalah konsisten dengan hasil yang kami inginkan. Dalam tugasan ini, kami mengguna pakai rangka kerja sedemikian dan membina StyleGAN2. Keputusan eksperimen ditunjukkan dalam Jadual 2. Kami juga meneroka beberapa ciri menarik penjana QIREN, seperti yang ditunjukkan dalam Rajah 6 dan 7. Jadual 2. Skor FID model pada set data FFHQ dan CelebA-HQ.
Rajah 7. Interpolasi ruang imej yang bermakna 
Kerja ini bukan sahaja mengintegrasikan kelebihan kuantum ke dalam perwakilan neural tersirat, tetapi juga membuka arah aplikasi yang menjanjikan rangkaian saraf - perwakilan saraf tersirat. Perlu ditekankan bahawa perwakilan saraf tersirat mempunyai banyak aplikasi berpotensi lain, seperti mewakili pemandangan atau objek 3D, ramalan siri masa dan menyelesaikan persamaan pembezaan. Untuk kelas tugas besar yang memodelkan isyarat berterusan, kami boleh mempertimbangkan untuk memperkenalkan rangkaian perwakilan tersirat sebagai komponen asas. Berdasarkan asas teori dan eksperimen kertas ini, kami boleh memanjangkan QIREN kepada aplikasi ini dalam kerja akan datang, dan QIREN dijangka menghasilkan hasil yang lebih baik dengan parameter yang lebih sedikit dalam bidang ini. Pada masa yang sama, kami menemui senario aplikasi yang sesuai untuk pembelajaran mesin kuantum. Dengan itu mempromosikan penyelidikan praktikal dan inovatif selanjutnya dalam komuniti pembelajaran mesin kuantum. 
Atas ialah kandungan terperinci ICML 2024 |. Perwakilan isyarat secara eksponen lebih kuat, penjimatan memori melebihi 35%, rangkaian perwakilan tersirat kuantum akan datang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn


