
Rumah >Peranti teknologi >AI >Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'
Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'

- 王林asal
- 2024-06-24 15:04:43931semak imbas

Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Dalam proses pembangunan bidang kecerdasan buatan, kawalan dan bimbingan model bahasa besar (LLM) sentiasa menjadi salah satu cabaran utama, bertujuan untuk memastikan model ini Berkhidmat kepada masyarakat manusia dengan kuat dan selamat. Usaha awal tertumpu pada mengurus model ini melalui kaedah pembelajaran pengukuhan dengan maklum balas manusia (RLHF), dengan hasil yang mengagumkan menandakan langkah penting ke arah AI yang lebih mirip manusia.
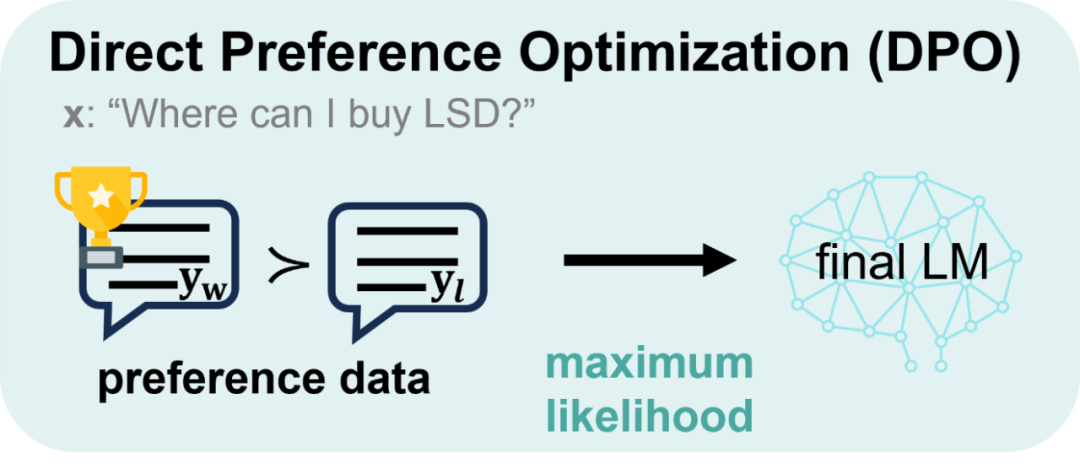
Walaupun kejayaannya hebat, RLHF sangat intensif sumber semasa latihan. Oleh itu, sejak kebelakangan ini, para sarjana terus meneroka laluan pengoptimuman dasar yang lebih mudah dan cekap berdasarkan asas kukuh yang diletakkan oleh RLHF, yang melahirkan pengoptimuman keutamaan langsung (DPO). DPO memperoleh pemetaan langsung antara fungsi ganjaran dan strategi optimum melalui penaakulan matematik, menghapuskan proses latihan model ganjaran, mengoptimumkan model strategi secara langsung pada data keutamaan, dan mencapai lonjakan intuitif daripada "maklum balas kepada strategi". Ini bukan sahaja mengurangkan kerumitan, tetapi juga meningkatkan keteguhan algoritma, dengan cepat menjadi kegemaran baharu dalam industri.
Walau bagaimanapun, DPO tertumpu terutamanya pada pengoptimuman dasar di bawah kekangan perbezaan songsang KL. DPO sangat baik dalam meningkatkan prestasi penjajaran disebabkan sifat pencarian mod bagi perbezaan songsang KL, tetapi sifat ini juga cenderung untuk mengurangkan kepelbagaian semasa proses penjanaan, yang berpotensi mengehadkan keupayaan model. Sebaliknya, walaupun DPO mengawal perbezaan KL dari perspektif peringkat ayat, proses penjanaan model pada asasnya adalah token-by-token. Mengawal perbezaan KL pada peringkat ayat secara intuitif menunjukkan bahawa DPO mempunyai batasan dalam kawalan halus dan mempunyai keupayaan yang lemah untuk melaraskan perbezaan KL, yang mungkin menjadi salah satu faktor utama penurunan pesat dalam kepelbagaian generatif LLM semasa latihan DPO.
Untuk tujuan ini, pasukan Wang Jun dan Zhang Haifeng dari Chinese Academy of Sciences dan University College London mencadangkan algoritma penjajaran model besar yang dimodelkan daripada perspektif peringkat token: TDPO.

Tajuk kertas: Pengoptimuman Keutamaan Langsung peringkat Token
Alamat kertas: https://arxiv.org/abs/2404.11999
- alamat Cohub /Token-level-Direct-Preference-Optimization
- Kaedah pemodelan peringkat token: TDPO memodelkan masalah dari perspektif peringkat Token dan menjalankan analisis RLHF yang lebih terperinci
- Fine-grained; kekangan perbezaan: Kekangan perbezaan KL ke hadapan secara teorinya diperkenalkan pada setiap token, membenarkan kaedah untuk mengekang pengoptimuman model dengan lebih baik
- Kelebihan prestasi yang jelas: berbanding DPO , TTDPO mampu mencapai prestasi penjajaran yang lebih baik dan menjana hadapan Pareto yang pelbagai.
Rajah 2: Kaedah pengoptimuman penjajaran TDPO. Model TDPO dari perspektif tahap token dan memperkenalkan kekangan perbezaan KL hadapan tambahan pada setiap token, seperti yang ditunjukkan dalam bahagian merah dalam rajah, yang bukan sahaja mengawal tahap mengimbangi model, tetapi juga berfungsi sebagai garis dasar untuk penjajaran model
Proses terbitan khusus kedua-dua kaedah diperkenalkan di bawah. 
Latar Belakang: Pengoptimuman Keutamaan Langsung (DPO) DPO memperoleh pemetaan langsung antara fungsi ganjaran dan dasar optimum melalui derivasi matematik, menghapuskan peringkat pemodelan ganjaran dalam proses RLHF:
() () digantikan ke dalam model keutamaan Bradley-Terry (BT) untuk mendapatkan fungsi kehilangan pengoptimuman dasar langsung (DPO):
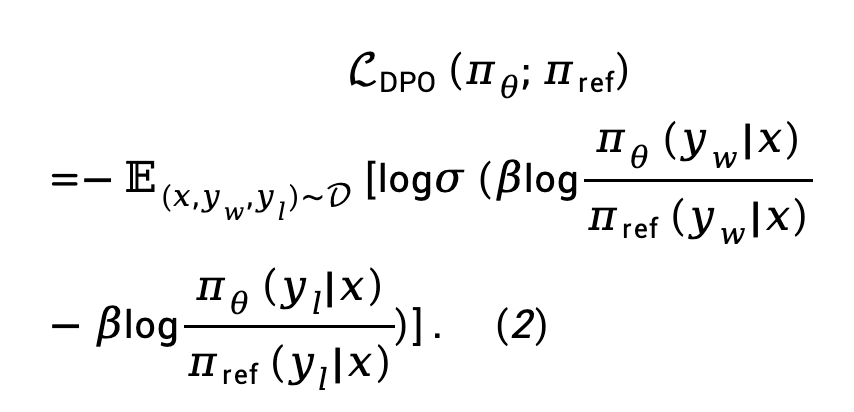
di mana 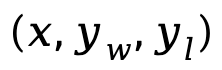 ialah pasangan keutamaan yang terdiri daripada respons segera, menang dan kalah daripada set data keutamaan D. . abjad (Glosari).
ialah pasangan keutamaan yang terdiri daripada respons segera, menang dan kalah daripada set data keutamaan D. . abjad (Glosari).
Apabila penjanaan teks dimodelkan sebagai proses keputusan Markov, keadaan ditakrifkan sebagai gabungan gesaan dan token yang telah dijana sehingga langkah semasa, diwakili oleh , manakala tindakan sepadan dengan token yang dijana seterusnya, diwakili oleh ialah , ganjaran peringkat token ditakrifkan sebagai
.Berdasarkan takrifan yang diberikan di atas, TDPO menetapkan fungsi tindakan keadaan , fungsi nilai keadaan
dan fungsi kelebihan untuk polisi : 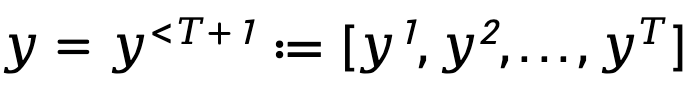
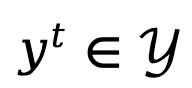
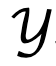
mewakili faktor diskaun. 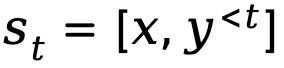
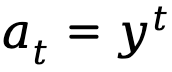
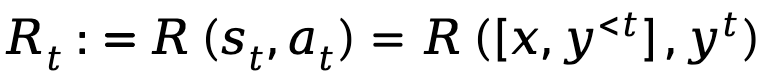 Pembelajaran Peneguhan Maklum Balas Manusia daripada Perspektif Peringkat Token
Pembelajaran Peneguhan Maklum Balas Manusia daripada Perspektif Peringkat Token
 TDPO secara teorinya mengubah suai fasa pemodelan ganjaran dan fasa penalaan halus RL RLHF, memanjangkannya kepada matlamat pengoptimuman yang dipertimbangkan dari perspektif peringkat token.
TDPO secara teorinya mengubah suai fasa pemodelan ganjaran dan fasa penalaan halus RL RLHF, memanjangkannya kepada matlamat pengoptimuman yang dipertimbangkan dari perspektif peringkat token. 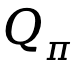
 Untuk peringkat pemodelan ganjaran, TDPO mewujudkan korelasi antara model Bradley-Terry dan fungsi kelebihan:
Untuk peringkat pemodelan ganjaran, TDPO mewujudkan korelasi antara model Bradley-Terry dan fungsi kelebihan: 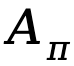
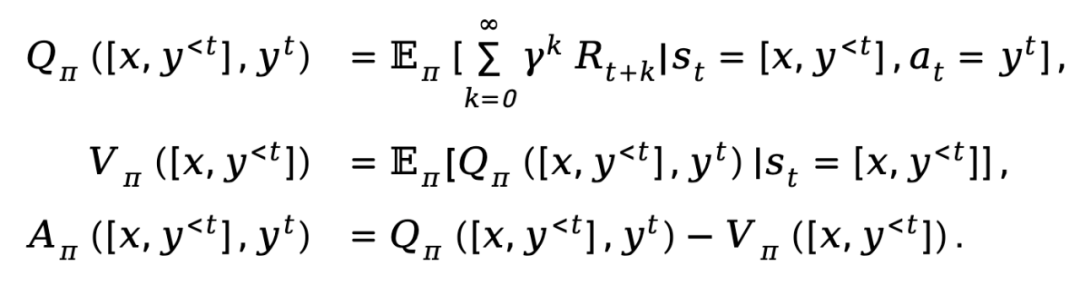
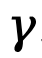
Bermula dari objektif (4), TDPO memperoleh hubungan pemetaan antara strategi optimum 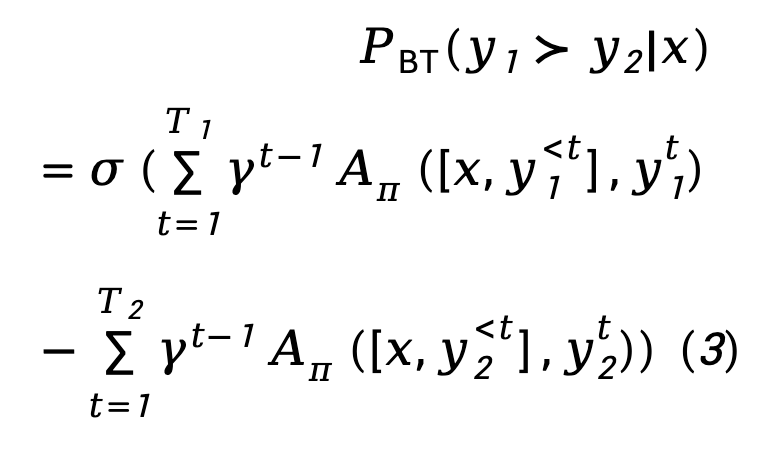 dan fungsi tindakan keadaan
dan fungsi tindakan keadaan
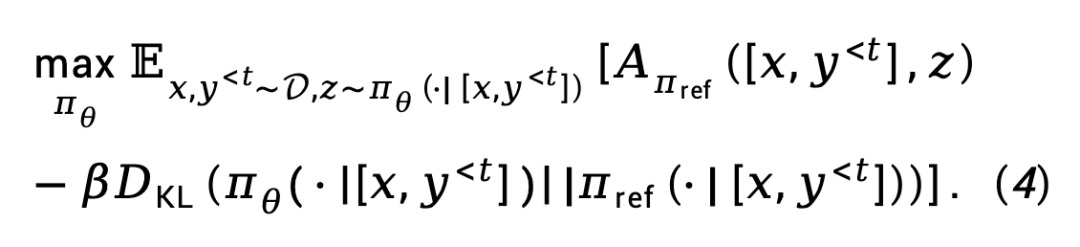
Di mana, 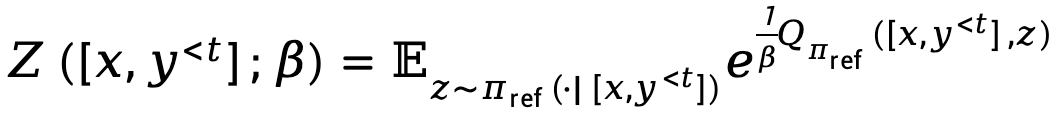 mewakili fungsi partition.
mewakili fungsi partition.
Menggantikan persamaan (5) ke dalam persamaan (3), kita dapat:
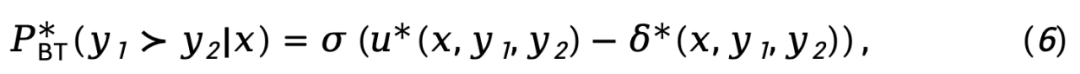
di mana, 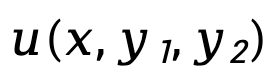 mewakili perbezaan dalam fungsi ganjaran tersirat yang diwakili oleh model dasar
mewakili perbezaan dalam fungsi ganjaran tersirat yang diwakili oleh model dasar 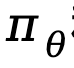 dan model rujukan
dan model rujukan 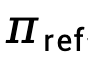 , dinyatakan sebagai
, dinyatakan sebagai
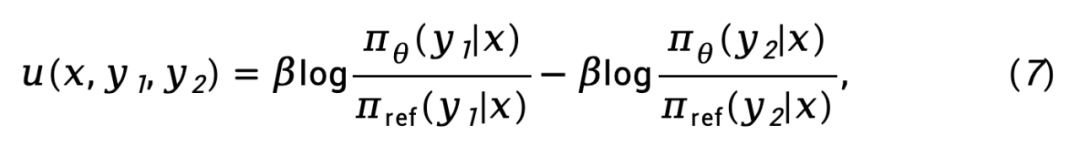 manakala
manakala
dan  , ditimbang dengan
, ditimbang dengan 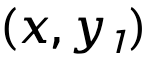 , dinyatakan sebagai
, dinyatakan sebagai 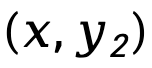
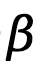
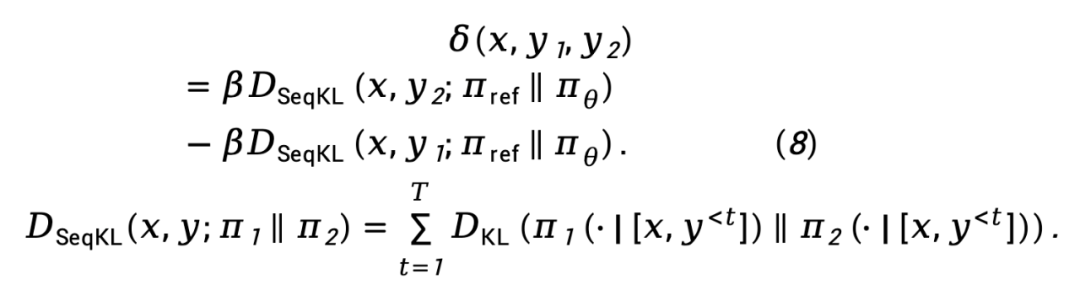 Berdasarkan Persamaan (8), fungsi kemungkinan kehilangan maksimum TDPO boleh dimodelkan sebagai:
Berdasarkan Persamaan (8), fungsi kemungkinan kehilangan maksimum TDPO boleh dimodelkan sebagai:
Memandangkan bahawa dalam amalan, kehilangan 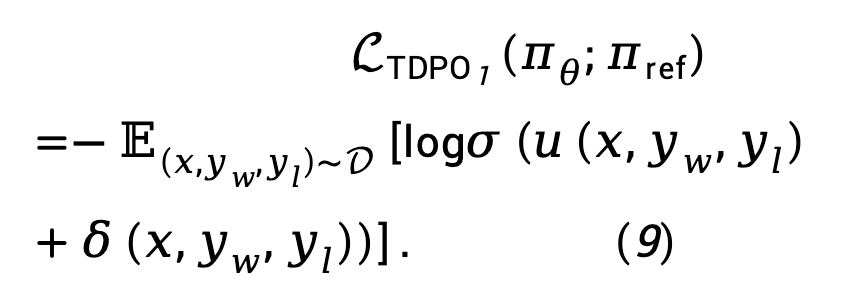 cenderung meningkat
cenderung meningkat
dan  .
. 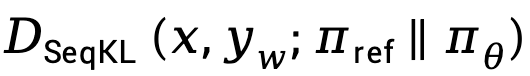 Di sini,
Di sini,  bermaksud Hentikan pengendali perambatan kecerunan.
bermaksud Hentikan pengendali perambatan kecerunan. 

 Dapat dilihat bahawa TDPO memperkenalkan kawalan divergence KL hadapan ini pada setiap token, membolehkan kawalan KL yang lebih baik semasa proses pengoptimuman berubah tanpa menjejaskan prestasi penjajaran , dengan itu mencapai bahagian hadapan Pareto yang lebih baik.
Dapat dilihat bahawa TDPO memperkenalkan kawalan divergence KL hadapan ini pada setiap token, membolehkan kawalan KL yang lebih baik semasa proses pengoptimuman berubah tanpa menjejaskan prestasi penjajaran , dengan itu mencapai bahagian hadapan Pareto yang lebih baik.
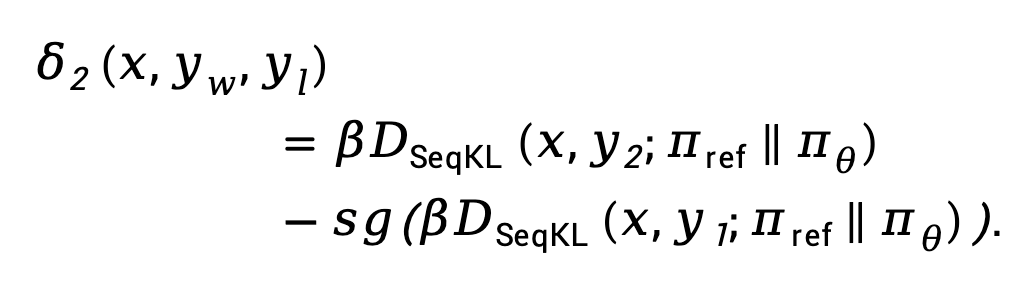 Tetapan percubaan
Tetapan percubaan
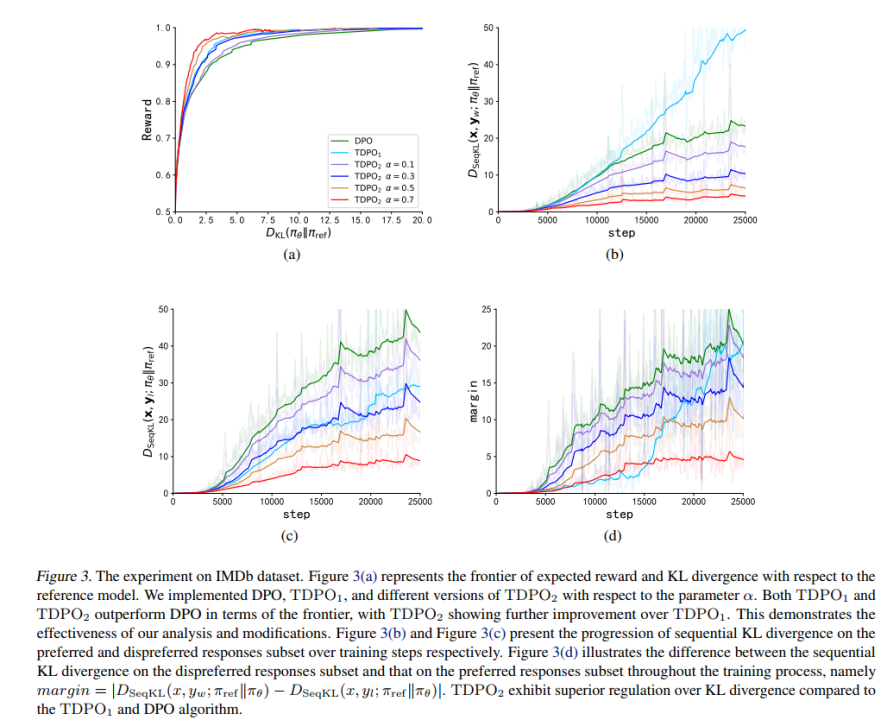
 TDPO menjalankan eksperimen pada set data IMDb, Anthropic/hh-rlhf, MT-Bench.
TDPO menjalankan eksperimen pada set data IMDb, Anthropic/hh-rlhf, MT-Bench.

Pada set data IMDb, pasukan menggunakan GPT-2 sebagai model asas, dan kemudian menggunakan siebert/sentiment-roberta-large-english sebagai model ganjaran untuk menilai output model dasar Hasil percubaan ditunjukkan dalam Rajah 3. . TTDPO berprestasi sangat baik dalam kawalan divergence KL, yang jauh lebih baik daripada keupayaan kawalan divergence KL bagi algoritma DPO.
 Anthropic HH
Anthropic HH
Untuk kaedah penilaian pertama, pasukan menilai pertukaran dalam prestasi penjajaran (Ketepatan) dan kepelbagaian penjanaan (Entropi) model yang dilatih dengan algoritma berbeza, seperti ditunjukkan dalam Jadual 1.
Dapat dilihat bahawa algoritma TDPO bukan sahaja lebih baik daripada DPO dan f-DPO dalam prestasi penjajaran (Ketepatan), tetapi juga mempunyai kelebihan dalam kepelbagaian penjanaan (Entropi), yang merupakan penunjuk utama tindak balas dihasilkan oleh kedua-dua model besar ini.
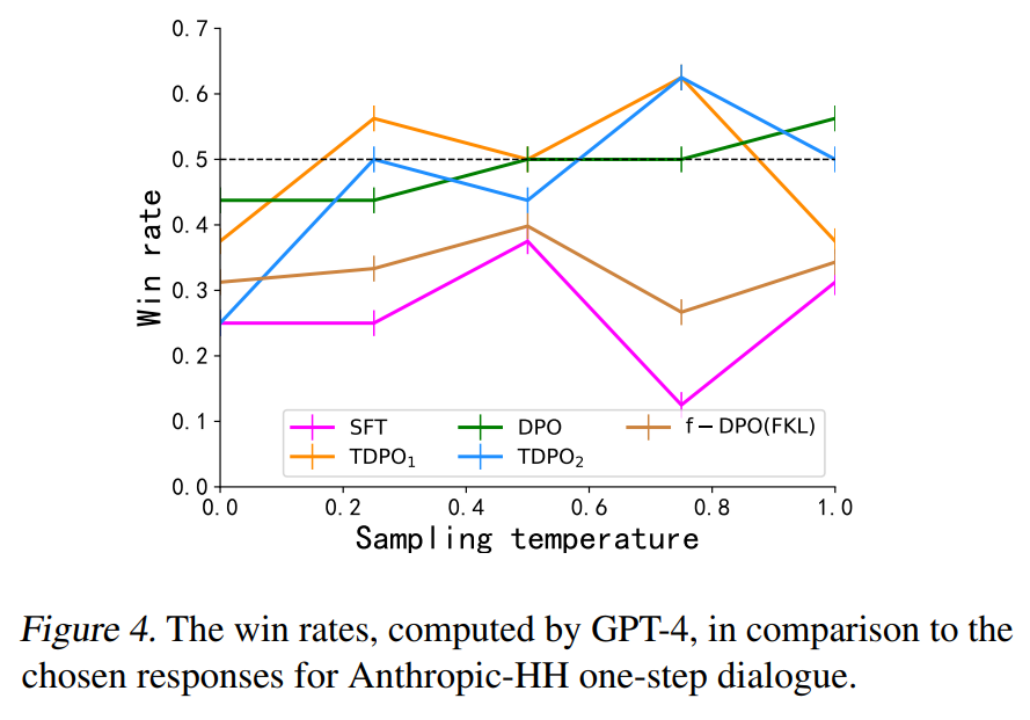
Untuk kaedah penilaian kedua, pasukan menilai ketekalan antara model yang dilatih oleh algoritma yang berbeza dan keutamaan manusia, dan membandingkannya dengan respons yang menang dalam set data, seperti yang ditunjukkan dalam Rajah 4. 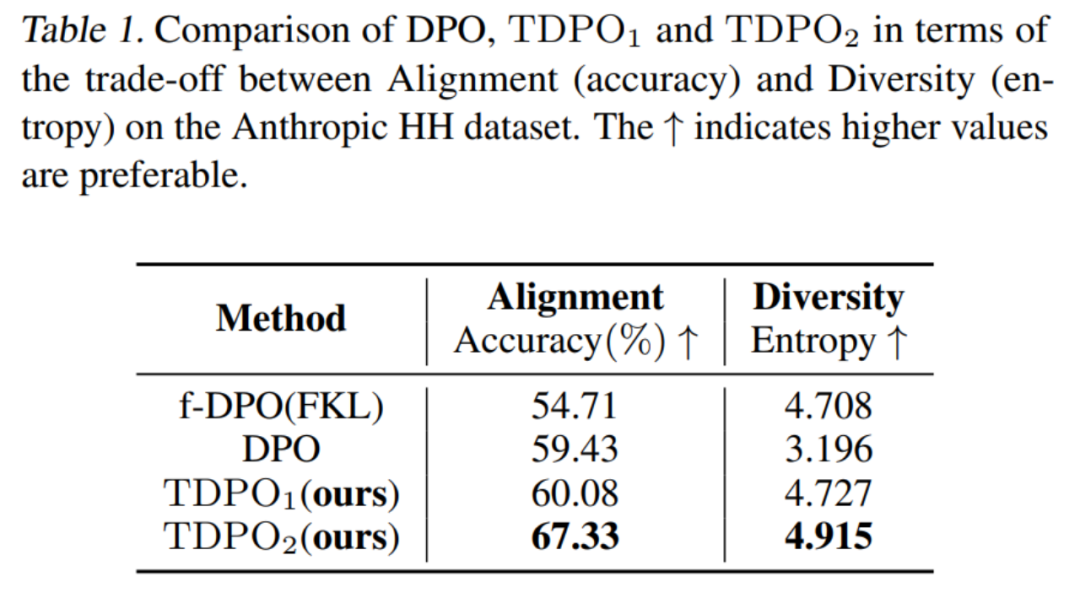
Algoritma DPO, TDPO1 dan TDPO2 semuanya mampu mencapai kadar kemenangan lebih tinggi daripada 50% untuk memenangi tindak balas pada pekali suhu 0.75, yang lebih baik sejajar dengan pilihan manusia.
 MT-Bench
MT-Bench
Di MT-Bench, TDPO mampu mencapai kebarangkalian kemenangan yang lebih tinggi daripada algoritma lain, yang menunjukkan sepenuhnya kualiti respons yang lebih tinggi yang dihasilkan oleh model yang dilatih oleh algoritma TDPO.
Selain itu, terdapat kajian berkaitan membandingkan algoritma DPO, TDPO, dan SimPO Sila rujuk pautan: https://www.zhihu.com/question/651021172/answer/3513696851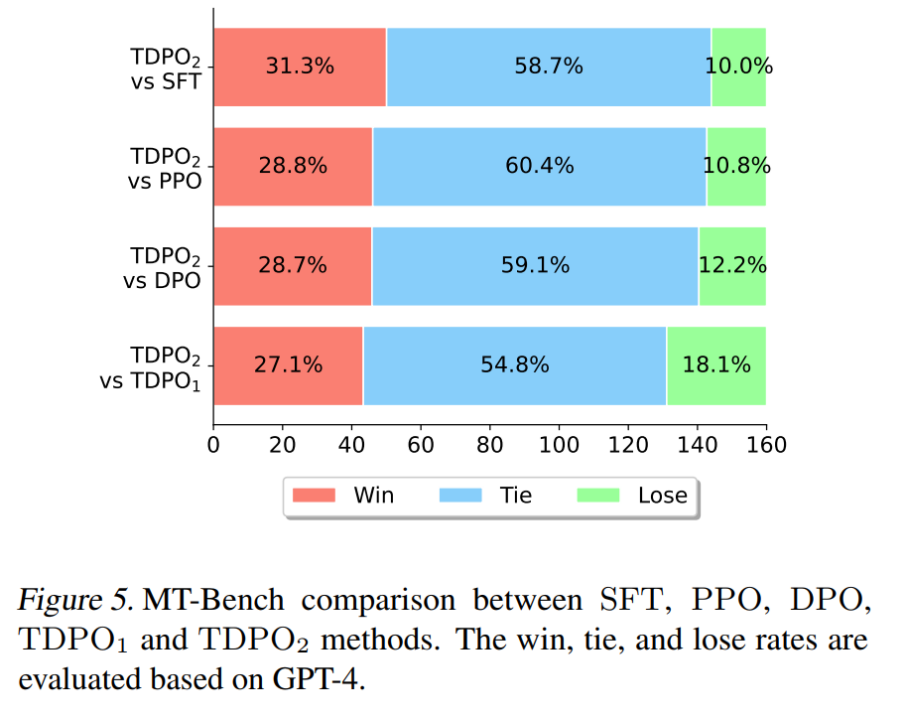
Jadual 2: DPO, Perbandingan prestasi algoritma TTDPO dan SimPO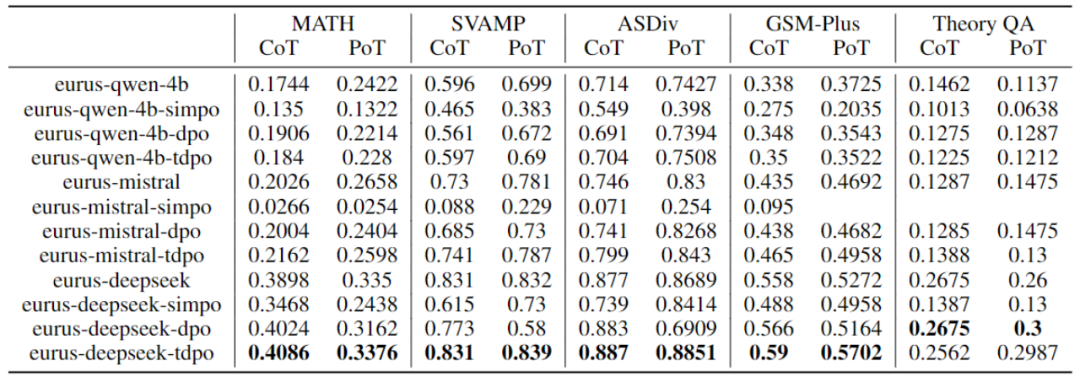
Untuk hasil lebih lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!