Pada Persidangan Pembangun Seluruh Dunia yang baru sahaja tamat, Apple mengumumkan perisikan Apple, sistem perisikan diperibadikan baharu yang disepadukan secara mendalam ke dalam iOS 18, iPadOS 18 dan macOS Sequoia.

Apple+ Intelligence terdiri daripada pelbagai model generatif sangat pintar yang direka untuk tugas harian pengguna. Dalam blog Apple yang baru dikemas kini, mereka memperincikan dua model.
Kedua-dua model asas ini adalah sebahagian daripada keluarga model generatif Apple, dan Apple berkata mereka akan berkongsi maklumat lanjut tentang keluarga model ini dalam masa terdekat.
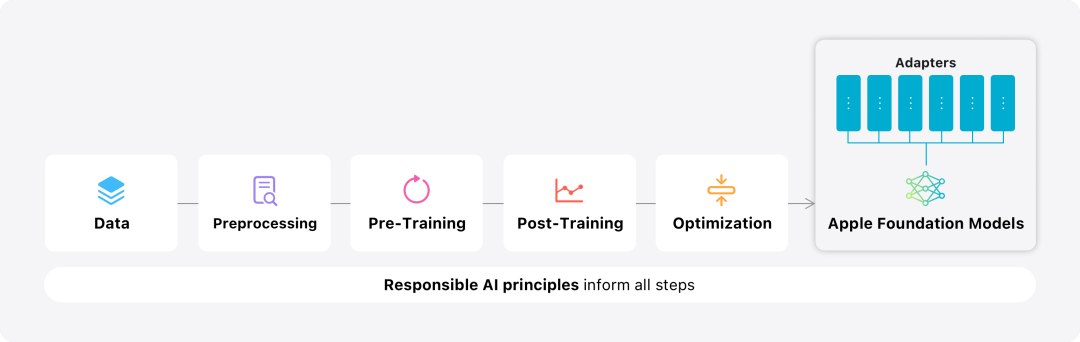
Dalam blog ini, Apple meluangkan banyak masa untuk memperkenalkan cara mereka membangunkan model berprestasi tinggi, pantas dan cekap tenaga cara melatih model ini; untuk membantu dan mengelakkan Prestasi dari segi kecederaan akibat kemalangan.型 Gambaran Keseluruhan Pemodelan Model Asas Apple Pra -latihan
ini dilatih dalam rangka kerja Apple Axlea. Rangka kerja ini dibina pada JAX dan XLA, membolehkan pengguna melatih model secara cekap dan berskala pada pelbagai perkakasan dan platform awan, termasuk TPU dan GPU dalam awan dan di premis. Selain itu, Apple menggunakan teknik seperti keselarian data, keselarian tensor, keselarian jujukan dan FSDP untuk menskalakan latihan sepanjang berbilang dimensi seperti data, model dan panjang jujukan. Apabila melatih model asasnya, Apple menggunakan data yang dibenarkan, yang termasuk data yang dipilih khas untuk meningkatkan fungsi tertentu, serta data yang dikumpul daripada rangkaian awam oleh perangkak web Apple AppleBot. Penerbit kandungan web boleh memilih untuk tidak menggunakan kandungan web mereka untuk melatih Apple Intelligence dengan menetapkan kawalan penggunaan data.
Apple tidak pernah menggunakan data peribadi pengguna apabila melatih model asasnya. Untuk melindungi privasi, mereka menggunakan penapis untuk mengalih keluar maklumat yang boleh dikenal pasti secara peribadi, seperti nombor kad kredit, yang tersedia secara umum di Internet. Selain itu, mereka menapis bahasa kesat dan kandungan lain yang berkualiti rendah sebelum ia masuk ke dalam set data latihan. Sebagai tambahan kepada langkah penapisan ini, Apple melaksanakan pengekstrakan dan penyahduplikasian data serta menggunakan pengelas berasaskan model untuk mengenal pasti dan memilih dokumen berkualiti tinggi untuk latihan.
Apple mendapati bahawa kualiti data adalah penting kepada model, jadi ia menggunakan strategi data hibrid dalam proses latihan, iaitu, data beranotasi data sintetik secara manual dan menjalankan prosedur Pengurusan dan penapisan data yang komprehensif. Apple membangunkan dua algoritma baharu dalam fasa pasca latihan: (1) algoritma penalaan halus pensampelan penolakan dengan "jawatankuasa guru", (2) pengukuhan daripada maklum balas manusia menggunakan pengoptimuman strategi turun-cermin dan cuti-satu-keluar. algoritma pembelajaran penganggar kelebihan (RLHF). Kedua-dua algoritma ini meningkatkan kualiti arahan model dengan ketara.
Di samping memastikan prestasi tinggi model yang dihasilkan itu sendiri, Apple juga menggunakan pelbagai teknologi inovatif untuk menambah baik dan mengoptimumkan model pada peranti kecekapan . Khususnya, mereka membuat banyak pengoptimuman kepada proses penaakulan model dalam menghasilkan token pertama (unit asas aksara atau perkataan tunggal) dan token seterusnya untuk memastikan tindak balas pantas dan operasi model yang cekap. Apple menggunakan mekanisme perhatian pertanyaan kumpulan dalam kedua-dua model sisi peranti dan model pelayan untuk meningkatkan kecekapan. Untuk mengurangkan keperluan memori dan kos inferens, mereka menggunakan jadual pembenaman perbendaharaan kata input dan output dikongsi yang tidak diduplikasi semasa pemetaan. Model sisi peranti mempunyai perbendaharaan kata sebanyak 49,000, manakala model pelayan mempunyai perbendaharaan kata sebanyak 100,000.
Untuk inferens sisi peranti, Apple menggunakan palletisasi bit rendah, iaitu teknologi pengoptimuman utama yang boleh memenuhi keperluan memori, penggunaan kuasa dan prestasi yang diperlukan. Untuk mengekalkan kualiti model, Apple turut membangunkan rangka kerja baharu menggunakan penyesuai LoRA yang menggabungkan strategi konfigurasi 2-bit dan 4-bit hibrid — purata 3.5 bit setiap berat — untuk mencapai ketepatan yang sama seperti model yang tidak dimampatkan.
Selain itu, Apple menggunakan Talaria, kependaman model interaktif dan alat analisis kuasa, serta pengkuantitian pengaktifan dan pengkuantitian benam, dan membangunkan kaedah untuk melaksanakan kemas kini cache nilai kunci (KV) yang cekap pada Enjin Neural.
Melalui siri pengoptimuman ini, pada iPhone 15 Pro, apabila model menerima perkataan segera, masa yang diperlukan daripada menerima perkataan gesaan hingga menghasilkan token pertama ialah kira-kira 0.6 milisaat Masa tunda ini Sangat singkat, menunjukkan bahawa model menjana respons dengan sangat cepat pada kadar 30 token sesaat.
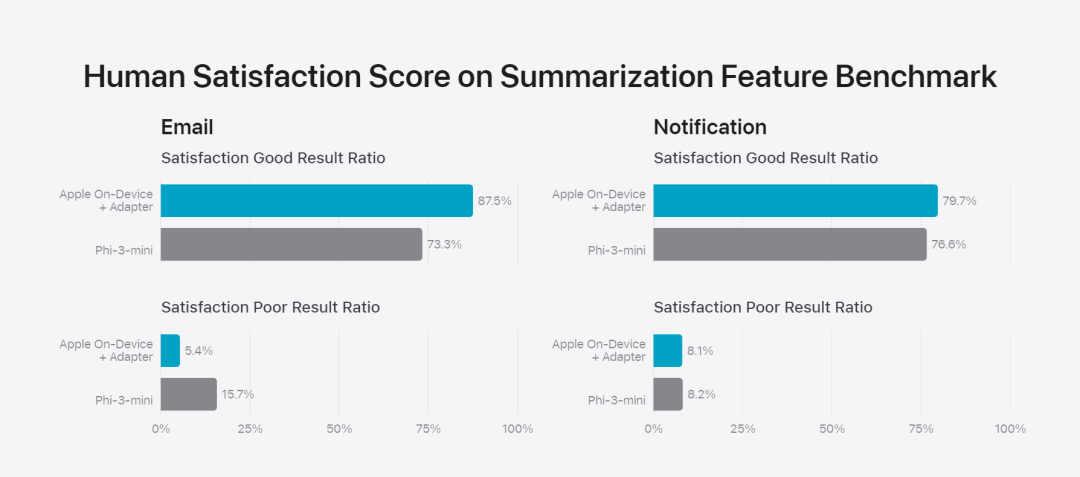
Apple memperhalusi model asas kepada aktiviti harian pengguna dan boleh mengkhususkannya secara dinamik untuk tugas yang sedang dijalankan.Pasukan penyelidik menggunakan penyesuai, modul rangkaian saraf kecil yang boleh dipalamkan ke dalam pelbagai lapisan model pra-latihan, untuk memperhalusi model untuk tugasan tertentu. Khususnya, pasukan penyelidik melaraskan matriks perhatian, matriks unjuran perhatian dan lapisan yang disambungkan sepenuhnya dalam rangkaian suapan ke hadapan dari segi titik. Dengan hanya memperhalusi lapisan penyesuai, parameter asal model asas pra-latihan kekal tidak berubah, mengekalkan pengetahuan am model, sambil menyesuaikan lapisan penyesuai untuk menyokong tugas tertentu. Rajah 2: Penyesuai ialah koleksi kecil pemberat model yang ditindih pada model asas biasa. Ia boleh dimuatkan dan ditukar secara dinamik - membolehkan model asas mengkhususkan secara dinamik dalam tugasan yang ada. Kepintaran Apple termasuk set penyesuai yang luas, setiap satu diperhalusi untuk fungsi tertentu. Ini adalah cara yang cekap untuk memanjangkan kefungsian model asasnya. Pasukan penyelidik menggunakan 16 bit untuk mencirikan nilai parameter penyesuai Untuk model peranti dengan kira-kira 3 bilion parameter, parameter 16 penyesuai biasanya memerlukan 10 megabait. Model penyesuai boleh dimuatkan secara dinamik, dicache buat sementara waktu dalam ingatan, dan ditukar. Ini membolehkan model asas mengkhusus secara dinamik dalam tugas semasa sambil mengurus memori dengan cekap dan memastikan responsif sistem pengendalian. Untuk memudahkan latihan penyesuai, Apple telah mencipta infrastruktur yang cekap untuk melatih semula, menguji dan menggunakan penyesuai dengan pantas apabila model asas atau data latihan dikemas kini. Apple memberi tumpuan kepada penilaian manusia apabila menanda aras model kerana hasil penilaian manusia sangat berkait rapat dengan pengalaman pengguna produk. Untuk menilai keupayaan ringkasan khusus produk, pasukan penyelidik menggunakan satu set 750 respons yang disampel dengan teliti untuk setiap kes penggunaan. Set data penilaian menekankan kepelbagaian input yang mungkin dihadapi oleh ciri produk dalam pengeluaran dan termasuk campuran berlapis dokumen tunggal dan bertindan dengan pelbagai jenis dan panjang kandungan. Keputusan eksperimen mendapati bahawa model dengan penyesuai dapat menjana ringkasan yang lebih baik daripada model yang serupa. Sebagai sebahagian daripada pembangunan yang bertanggungjawab, Apple mengenal pasti dan menilai risiko khusus yang wujud dalam abstrak. Sebagai contoh, ringkasan kadangkala menghilangkan nuansa penting atau butiran lain. Walau bagaimanapun, pasukan penyelidik mendapati bahawa penyesuai digest tidak menguatkan kandungan sensitif dalam lebih daripada 99% contoh musuh yang disasarkan.用 Rajah 3: Perkadaran "baik" dan "perbezaan" dalam kes penggunaan abstrak. Selain menilai kefungsian khusus yang disokong oleh model asas dan penyesuai, pasukan penyelidik juga menilai kefungsian umum model pada peranti dan model berasaskan pelayan. Khususnya, pasukan penyelidik menggunakan set gesaan dunia sebenar yang komprehensif untuk menguji kefungsian model, meliputi sumbang saran, klasifikasi, Soal Jawab tertutup, pengekodan, pengekstrakan, penaakulan matematik, Soal Jawab terbuka, penulisan semula, keselamatan, rumusan dan tugasan penulisan.
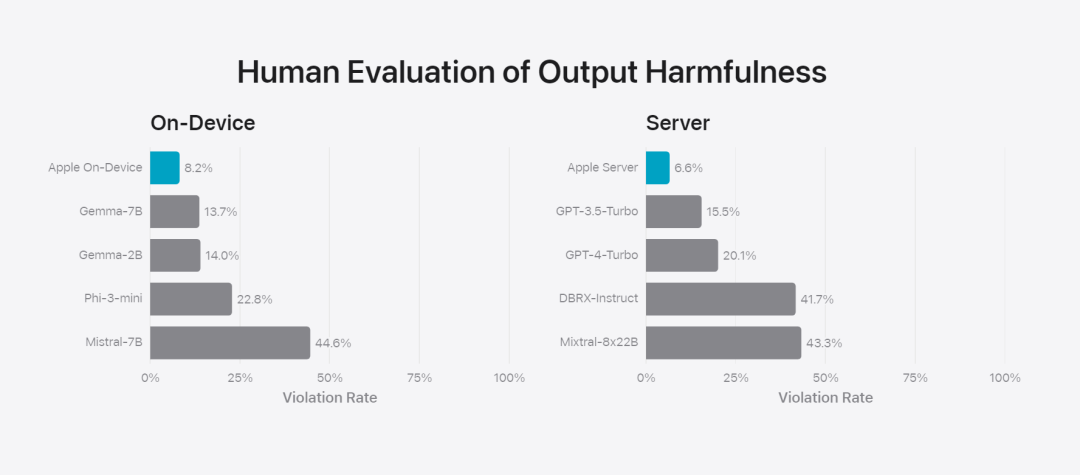
Pasukan penyelidik membandingkan model dengan model sumber terbuka (Phi-3, Gemma, Mistral, DBRX) dan model komersial skala setanding (GPT-3.5-Turbo, GPT-4-Turbo). Didapati model Apple digemari oleh penilai manusia berbanding kebanyakan model yang bersaing. Contohnya, model pada peranti Apple dengan parameter ~3B mengatasi model yang lebih besar termasuk model pelayan Phi-3-mini, Mistral-7B dan Gemma-7B bersaing dengan DBRX-Instruct, Mixtral-8x22B dan GPT-3.5 -Turbo; tidak kalah dalam perbandingan dan sangat cekap pada masa yang sama.基 Rajah 4: Perkadaran nisbah tindak balas dalam penilaian model asas Apple dan model perbandingan. Pasukan penyelidik juga menggunakan set gesaan lawan yang berbeza untuk menguji prestasi model pada kandungan berbahaya, topik dan fakta sensitif, mengukur kadar pelanggaran model seperti yang dinilai oleh penilai manusia, dengan bilangan yang lebih rendah adalah lebih baik baik. Menghadapi gesaan lawan, kedua-dua model pada peranti dan pelayan adalah mantap, dengan kadar pelanggaran yang lebih rendah daripada model sumber terbuka dan komersial.、 Rajah 5: Perkadaran kandungan berbahaya, tema sensitif dan fakta (semakin rendah lebih baik). Model Apple sangat teguh apabila berhadapan dengan gesaan lawan. Memandangkan keupayaan luas model bahasa besar, Apple secara aktif bekerjasama dengan pasukan dalaman dan luaran dalam pasukan merah manual dan automatik untuk menilai lagi keselamatan model tersebut.
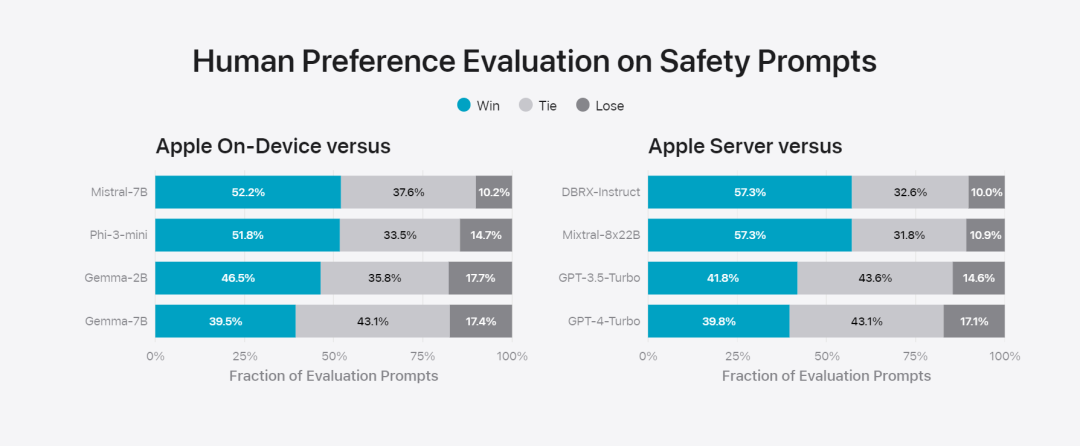
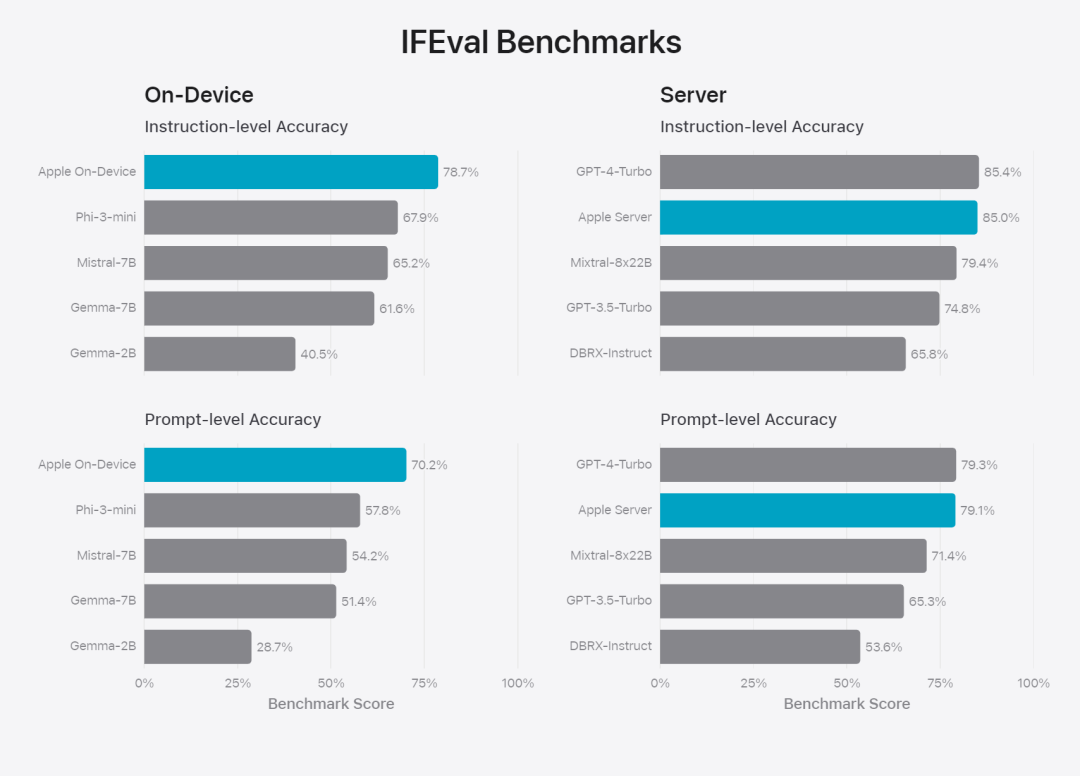
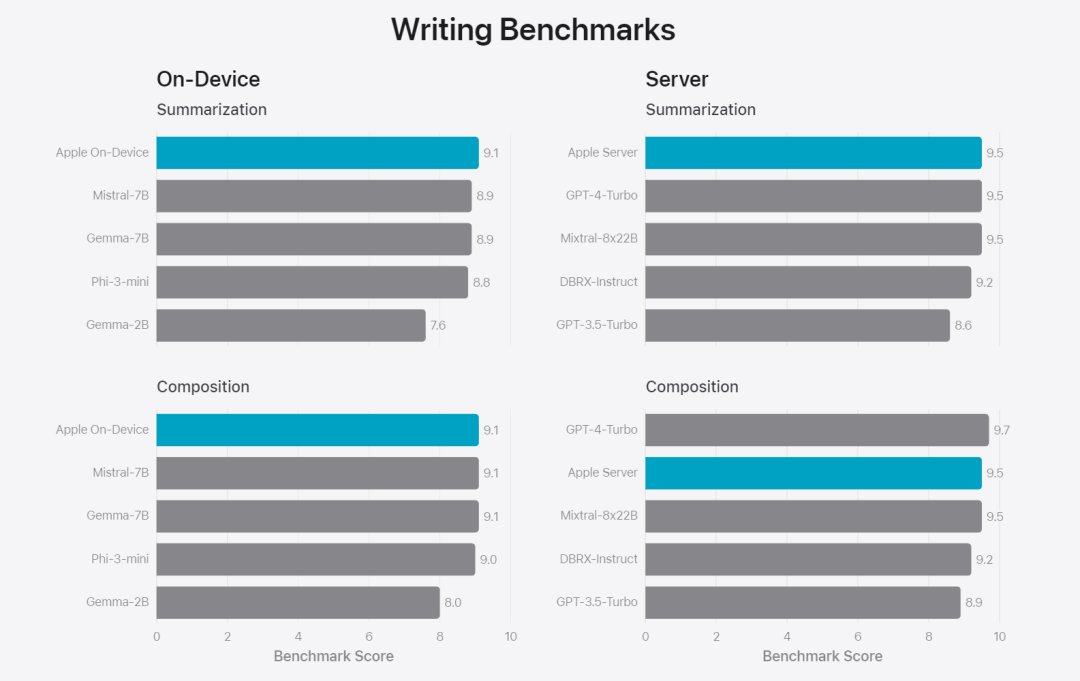
Rajah 6: Perkadaran respons pilihan dalam penilaian selari model asas Apple dan model serupa dari segi gesaan keselamatan. Penilai manusia mendapati respons model asas Apple adalah lebih selamat dan lebih membantu. Untuk menilai lebih lanjut model, pasukan penyelidik menggunakan penanda aras Instruction Tracing Evaluation (IFEval) untuk membandingkan keupayaan pengesanan arahannya dengan model bersaiz serupa. Keputusan menunjukkan bahawa kedua-dua model pada peranti dan pelayan mengikut arahan terperinci dengan lebih baik daripada model sumber terbuka dan komersial dengan skala yang sama.基 Rajah 7: Model asas Apple dan keupayaan pengesanan arahan model skala yang serupa (menggunakan penanda aras IFEVAL). Apple juga menilai keupayaan penulisan model, melibatkan pelbagai arahan penulisan. Rajah 8: Keupayaan menulis (lebih tinggi, lebih baik Akhir sekali, mari kita lihat video Apple yang memperkenalkan teknologi di sebalik Apple Intelligence.
Pautan rujukan: https://machinelearning.apple.com/research/introducing-apple-foundation-modelsAtas ialah kandungan terperinci Model di sebalik kecerdasan Apple diumumkan: model 3B lebih baik daripada Gemma-7B, dan model pelayan setanding dengan GPT-3.5-Turbo. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn