
Rumah >Peranti teknologi >AI >Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct

- PHPzasal
- 2024-06-13 13:59:561582semak imbas
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct.
Pencapaian inovatif ini telah membuat satu kejayaan besar dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod.

Keunikan StarCoder2-15B-Instruct ialah strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya berautonomi dan boleh dikawal.
Model menjana beribu-ribu arahan melalui StarCoder2-15B dan memperhalusi model asas StarCoder-15B sebagai tindak balas Ia tidak perlu bergantung pada anotasi manual yang mahal bagi data, dan juga tidak perlu mendapatkan data daripada komersial besar model seperti GPT4, mengelakkan Potensi isu hak cipta.
Dalam ujian HumanEval, StarCoder2-15B-Instruct menyerlah dengan markah Pass@1 sebanyak 72.6%, yang telah dipertingkatkan daripada 72.0% CodeLlama-70B-Instruct.
Dalam penilaian pada set data LiveCodeBench, model penjajaran sendiri ini malah mengatasi prestasi model serupa yang dilatih pada data yang dijana GPT-4. Keputusan ini menunjukkan bahawa model besar juga boleh belajar secara berkesan cara menjajarkan sama dengan manusia menggunakan data dalam pengedarannya sendiri, tanpa bergantung pada pengedaran berat sebelah model besar daripada guru luar.
Kejayaan pelaksanaan projek ini telah mendapat sokongan padu daripada kumpulan penyelidik Arjun Guha di Northeastern University, University of California, Berkeley, ServiceNow dan Hugging Face serta institusi lain.
Teknologi Didedahkan
Proses penjanaan data StarCoder2-Instruct terutamanya merangkumi tiga langkah teras:
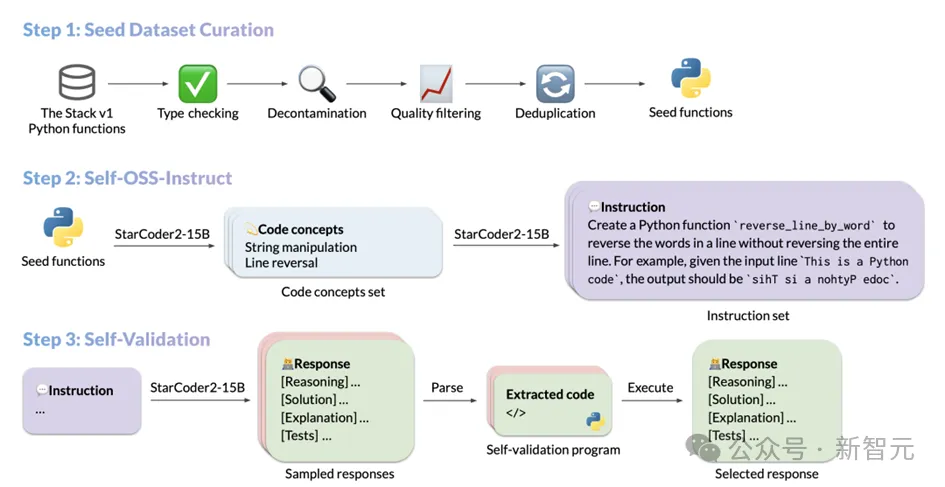
kod pp pasukan dari The Stack v1 Tapis fungsi benih yang berkualiti tinggi dan pelbagai daripada korpus besar kod sumber berlesen. Melalui penapisan dan penapisan yang ketat, kualiti dan kepelbagaian kod benih dipastikan; arahan kod yang realistik. Arahan ini merangkumi pelbagai senario pengaturcaraan daripada penyahserilan data kepada penggabungan senarai, rekursi, dll. kaedah pengesahan kendiri berpandu , memastikan bahawa respons yang dijana adalah tepat dan berkualiti tinggi. . untuk dan mempelajari prinsip pengaturcaraan yang berbeza dengan operasi praktikal. StarCoder2-15B-Instruct diilhamkan oleh OSS-Instruct dan mendapat inspirasi daripada coretan kod sumber terbuka, terutamanya fungsi benih Python yang diformat dengan baik dan berstruktur dengan jelas dalam The Stack V1. Apabila membina set data asasnya, StarCoder2-15B-Instruct menjalankan penerokaan mendalam The Stack V1, memilih semua fungsi Python dengan arahan yang didokumenkan, dan secara automatik menganalisis dan membuat kesimpulan fungsi yang diperlukan oleh fungsi ini dengan bantuan fungsi autoimport Ketergantungan.
Untuk memastikan ketulenan dan kualiti tinggi set data, StarCoder2-15B-Instruct telah menapis dan menapis semua fungsi yang dipilih dengan teliti. Pertama sekali, semakan jenis yang ketat dilakukan melalui penyemak jenis Pyright, tidak termasuk semua fungsi yang mungkin menghasilkan ralat statik, sekali gus memastikan ketepatan dan kebolehpercayaan data.
Kemudian, melalui teknologi padanan rentetan yang tepat, kod dan pembayang yang berpotensi berkaitan dengan set data penilaian dikenal pasti dan dihapuskan untuk mengelakkan pencemaran data. Dari segi kualiti dokumen, StarCoder2-15B-Instruct menggunakan mekanisme penyaringan yang unik. Ia menggunakan keupayaan penilaiannya sendiri untuk menunjukkan 7 gesaan sampel kepada model, membolehkan model menilai sama ada kualiti dokumen setiap fungsi memenuhi piawaian, dengan itu memutuskan sama ada untuk memasukkannya dalam set data akhir.
Kaedah berdasarkan penilaian kendiri model ini bukan sahaja meningkatkan kecekapan dan ketepatan penapisan data, tetapi juga memastikan kualiti dan ketekalan set data yang tinggi.
Akhir sekali, untuk mengelakkan lebihan dan pertindihan data, StarCoder2-15B-Instruct menggunakan MinHash dan algoritma pencincangan sensitif lokaliti untuk menyahduplikasi fungsi dalam set data. Dengan menetapkan ambang kesamaan Jaccard sebanyak 0.5, fungsi pendua dengan kesamaan tinggi dialih keluar dengan berkesan, memastikan keunikan dan kepelbagaian set data.
Selepas siri saringan dan penapisan halus ini, StarCoder2-15B-Instruct akhirnya memilih 250,000 fungsi berkualiti tinggi daripada 5 juta fungsi Python dengan dokumen sebagai set data benihnya. Pendekatan ini sangat diilhamkan oleh proses pengumpulan data MultiPL-T.
Penjanaan arahan yang pelbagai
Apabila StarCoder2-15B-Instruct melengkapkan pengumpulan fungsi benih, ia menggunakan teknologi Self-OSS-Instruct untuk mencipta arahan pengaturcaraan yang pelbagai. Teras teknologi ini adalah untuk membolehkan model asas StarCoder2-15B menjana arahan yang sepadan secara autonomi untuk serpihan kod benih tertentu melalui pembelajaran kontekstual.
Untuk mencapai matlamat ini, StarCoder2-15B-Instruct direka dengan teliti 16 contoh, setiap contoh mengikut struktur (coretan kod, konsep, arahan). Proses penjanaan arahan dibahagikan kepada dua peringkat:
Pengenalan konsep kod: Dalam peringkat ini, StarCoder2-15B akan menjalankan analisis mendalam bagi setiap fungsi benih dan menjana senarai yang mengandungi konsep kod utama dalam fungsi tersebut. Konsep ini secara meluas merangkumi prinsip dan teknik asas dalam bidang pengaturcaraan, seperti padanan corak, penukaran jenis data, dsb., yang mempunyai nilai praktikal yang sangat tinggi kepada pembangun.
Penciptaan arahan: Berdasarkan konsep kod yang diiktiraf, StarCoder2-15B akan terus menjana arahan tugas pengekodan yang sepadan. Proses ini direka bentuk untuk memastikan arahan yang dijana menggambarkan dengan tepat fungsi teras dan keperluan serpihan kod.
Melalui proses di atas, StarCoder2-15B-Instruct akhirnya berjaya menghasilkan sehingga 238k arahan, memperkayakan set data latihannya dan memberikan sokongan padu untuk prestasinya dalam tugas pengaturcaraan.
Mekanisme respons pengesahan kendiri
Selepas mendapat arahan yang dihasilkan oleh Self-OSS-Instruct, tugas utama StarCoder2-15B-Instruct adalah untuk memadankan setiap arahan yang berkualiti .
Secara tradisinya, orang ramai cenderung bergantung pada model guru yang lebih berkuasa seperti GPT-4 untuk mendapatkan respons ini, tetapi pendekatan ini bukan sahaja boleh menghadapi kesukaran pelesenan hak cipta, malah model luaran tidak selalu dapat dicapai atau tepat . Lebih penting lagi, bergantung pada model luaran mungkin memperkenalkan perbezaan pengedaran antara guru dan pelajar, yang boleh menjejaskan ketepatan keputusan akhir.
Untuk mengatasi cabaran ini, StarCoder2-15B-Instruct memperkenalkan mekanisme pengesahan kendiri. Idea teras mekanisme ini adalah untuk membenarkan model StarCoder2-15B mencipta kes ujian yang sepadan dengan sendirinya selepas menghasilkan tindak balas bahasa semula jadi. Proses ini serupa dengan proses ujian kendiri yang dilalui oleh pembangun selepas menulis kod.
Secara khusus, untuk setiap arahan, StarCoder2-15B akan menjana 10 sampel yang mengandungi tindak balas bahasa semula jadi dan kes ujian yang sepadan. StarCoder2-15B-Instruct kemudian melaksanakan kes ujian ini dalam persekitaran kotak pasir untuk mengesahkan kesahihan respons. Mana-mana sampel yang gagal dalam melaksanakan ujian akan ditapis keluar.
Selepas proses penyaringan yang ketat ini, StarCoder2-15B-Instruct akan memilih secara rawak satu daripada respons yang diuji bagi setiap arahan dan menambahkannya pada set data SFT akhir. Sepanjang proses, StarCoder2-15B-Instruct menjana sejumlah 2.4 juta sampel tindak balas (10 sampel setiap arahan) untuk 238k arahan. Selepas menggunakan strategi pensampelan sebanyak 0.7, 500,000 sampel berjaya melepasi ujian pelaksanaan.
Untuk memastikan kepelbagaian dan kualiti set data, StarCoder2-15B-Instruct juga melakukan pemprosesan penyahduplikasian. Akhirnya, 50,000 arahan ditinggalkan, setiap satu dengan respons berkualiti tinggi yang dipilih secara rawak, diuji dan disahkan. Respons ini membentuk set data SFT akhir StarCoder2-15B-Instruct, menyediakan asas yang kukuh untuk latihan dan aplikasi model yang seterusnya.
Prestasi cemerlang dan penilaian komprehensif StarCoder2-15B-Instruct
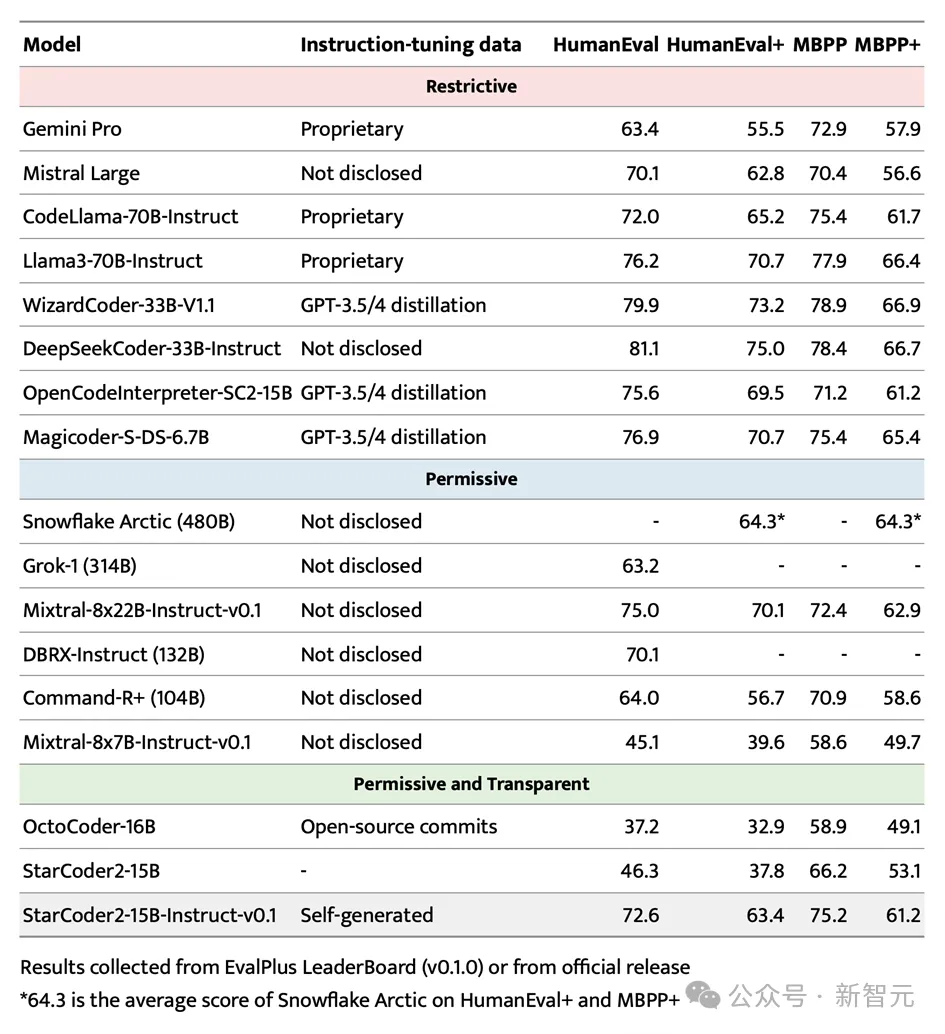
Dalam ujian penanda aras EvalPlus berprofil tinggi, StarCoder2-15B-Instruct berjaya menyerlah dan menjadi sistem berprestasi terbaik kerana prestasi autonominya Model besar yang boleh dikawal.
Bukan sahaja ia mengatasi Grok-1 Command-R+ dan DBRX yang lebih besar, ia juga sepadan dengan peneraju industri seperti Snowflake Arctic 480B dan Mixtral-8x22B-Instruct.
Perlu dinyatakan bahawa StarCoder2-15B-Instruct ialah model kod bebas besar pertama yang mencapai skor 70+ pada penanda aras HumanEval Proses latihannya benar-benar telus, dan penggunaan data serta kaedah mematuhi undang-undang dan peraturan .
Dalam bidang model besar kod boleh dikawal bebas, StarCoder2-15B-Instruct telah mengatasi dengan ketara OctoCoder peneraju terdahulu, membuktikan kedudukan utamanya dalam bidang ini.
Walaupun dibandingkan dengan model besar dan berkuasa dengan lesen terhad seperti Gemini Pro dan Mistral Large, StarCoder2-15B-Instruct masih menunjukkan prestasi cemerlang dan setanding dengan CodeLlama-70B-Instruct. Apa yang lebih mengagumkan ialah StarCoder2-15B-Instruct bergantung sepenuhnya pada data yang dijana sendiri untuk latihan, tetapi prestasinya adalah setanding dengan OpenCodeInterpreter-SC2-15B berdasarkan penalaan halus data GPT-3.5/4.
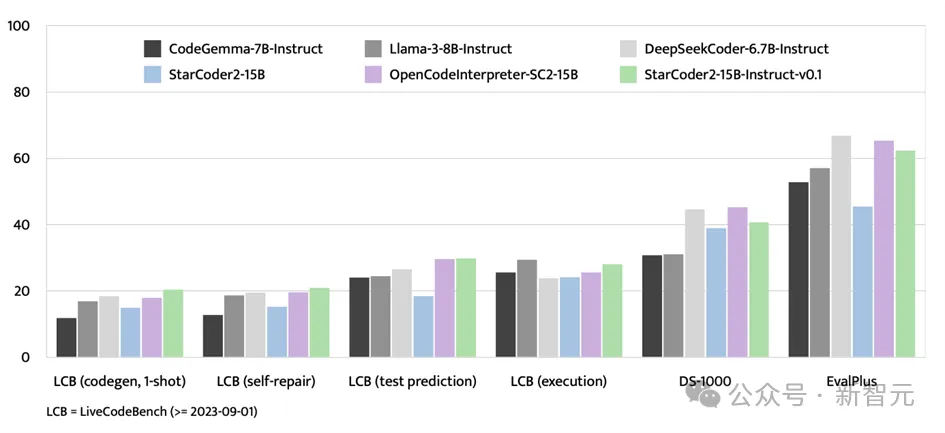
Selain ujian penanda aras EvalPlus, StarCoder2-15B-Instruct juga menunjukkan kekuatan yang kukuh pada platform penilaian seperti LiveCodeBench dan DS-1000.
LiveCodeBench memfokuskan pada menilai cabaran pengekodan yang muncul selepas 1 September 2023, dan StarCoder2-15B-Instruct mencapai hasil terbaik pada penanda aras ini dan secara konsisten mendahului OpenCodeInterpreter yang diperhalusi menggunakan data GPT-4B -SC2-15
Walaupun DS-1000 tertumpu pada tugas sains data, StarCoder2-15B-Instruct masih menunjukkan prestasi yang kukuh pada penanda aras ini, menunjukkan sedikit masalah sains data dalam data latihan dan daya saing. . Satu langkah penting telah diambil dalam bidang kecemerlangan. Amalan kejayaan model ini memecahkan had sebelumnya iaitu bergantung pada model guru luar yang berkuasa seperti GPT-4, dan menunjukkan bahawa model kod dengan prestasi cemerlang juga boleh dibina melalui penalaan kendiri.Teras StarCoder2-15B-Instruct-v0.1 terletak pada kejayaan penerapan strategi penjajaran kendirinya dalam bidang pembelajaran kod. Strategi ini bukan sahaja meningkatkan prestasi model, tetapi yang lebih penting, ia memberikan model lebih ketelusan dan kebolehtafsiran. Ini sangat berbeza dengan model besar lain seperti Snowflake-Arctic, Grok-1, Mixtral-8x22B, DBRX dan CommandR+, yang, walaupun berkuasa, sering mengehadkan skop dan kebolehpercayaannya kerana kekurangan ketelusan.
Apa yang lebih menggembirakan ialah StarCoder2-15B-Instruct-v0.1 telah membuat set data dan keseluruhan proses latihan - termasuk pengumpulan data dan proses latihan - sumber terbuka sepenuhnya. Langkah ini bukan sahaja menunjukkan semangat terbuka para penyelidik, tetapi juga meletakkan asas yang kukuh untuk penyelidikan dan pembangunan masa depan dalam bidang ini. Ada sebab untuk mempercayai bahawa amalan StarCoder2-15B-Instruct-v0.1 yang berjaya akan memberi inspirasi kepada lebih ramai penyelidik untuk melabur dalam penyelidikan dalam bidang penalaan kendiri model kod, dan menggalakkan kemajuan teknologi dan pengembangan aplikasi dalam ini padang. Pada masa yang sama, kami juga menjangkakan hasil yang lebih inovatif dalam bidang ini akan terus muncul, menyuntik dorongan baharu ke dalam pembangunan pintar masyarakat manusia.
Mengenai pengarang
Guru Zhang Lingming dari UIUC ialah seorang sarjana dengan pencapaian yang mendalam dalam persimpangan kejuruteraan perisian, bahasa pengaturcaraan dan pembelajaran mesin. Kumpulan penyelidikan yang dipimpinnya telah lama komited untuk menyelidik tentang sintesis perisian automatik, pembaikan dan pengesahan berdasarkan model AI yang besar, serta meningkatkan kebolehpercayaan sistem pembelajaran mesin.
Baru-baru ini, pasukan itu telah mengeluarkan beberapa model kod besar yang inovatif dan set data penanda aras ujian, dan telah menerajui dalam mencadangkan satu siri ujian perisian berasaskan model besar dan teknologi pembaikan. Pada masa yang sama, beribu-ribu kecacatan dan kelemahan baharu telah berjaya ditemui dalam berbilang sistem perisian sebenar, memberikan sumbangan besar kepada peningkatan kualiti perisian.
Atas ialah kandungan terperinci Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!