
Rumah >Peranti teknologi >AI >Amalan lanjutan graf pengetahuan industri
Amalan lanjutan graf pengetahuan industri

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-06-13 11:59:28644semak imbas
1. Pengenalan latar belakang
Pertama, mari kita perkenalkan sejarah pembangunan Teknologi Yunwen.

Syarikat Teknologi Yunwen...
2023 ialah tempoh apabila model besar berleluasa tidak lagi penting. Walau bagaimanapun, dengan promosi RAG dan kelaziman tadbir urus data, kami mendapati bahawa tadbir urus data yang lebih cekap dan data berkualiti tinggi adalah prasyarat penting untuk meningkatkan keberkesanan model besar yang diswastakan Oleh itu, semakin banyak syarikat mula memberi perhatian kepada kandungan berkaitan pembinaan pengetahuan. Ini juga menggalakkan pembinaan dan pemprosesan pengetahuan ke peringkat yang lebih tinggi, di mana terdapat banyak teknik dan kaedah yang boleh diterokai. Dapat dilihat bahawa kemunculan teknologi baru tidak mengalahkan semua teknologi lama. Ia juga mungkin hasil yang lebih baik akan dicapai dengan mengintegrasikan teknologi baru dan lama antara satu sama lain. Kita mesti berdiri di atas bahu gergasi dan terus berkembang.
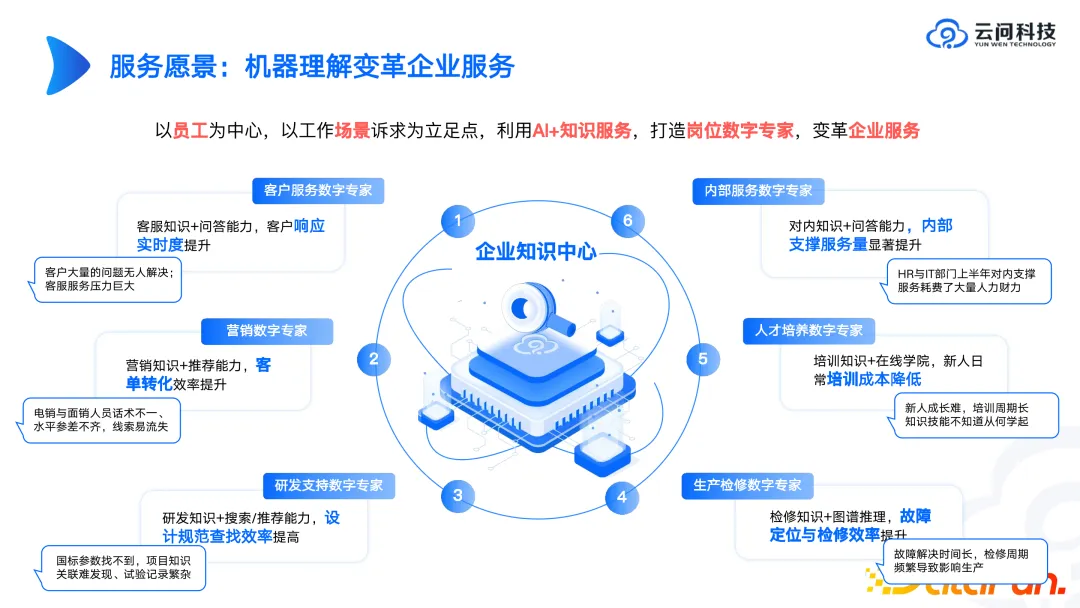
Mengapa Yunwen Technology memberi tumpuan kepada pusat pengetahuan perusahaan? Oleh kerana kami telah mendapati dalam beberapa kes lepas bahawa apabila berhadapan dengan banyak senario yang kompleks, seperti kawalan risiko, ujian dadah, dll., adalah sukar untuk mencapai hasil yang ideal dalam jangka pendek dan mencipta produk Standard dihantar. Dalam pengurusan pengetahuan perusahaan atau senario pengurusan perniagaan yang berkaitan dengan pejabat, operasi percubaan boleh dimasukkan dengan agak cepat, dan hasil yang ideal mungkin diperoleh. Oleh itu, apabila kami bekerjasama dengan perusahaan untuk mencipta model penswastaan berskala besar tahun ini, kami akan memasukkan pengurusan pengetahuan perusahaan, termasuk soal jawab atau carian berdasarkan pengurusan pengetahuan perusahaan, sebagai topik utama. Bagi perusahaan, pembinaan pusat pengetahuan dan pengetahuan mereka sendiri yang diswastakan adalah sangat penting.
Berdasarkan alasan-alasan ini, sekiranya ada rakan-rakan yang ingin mengkaji arah graf ilmu, saranan kami pertimbangkan keseluruhan kitaran hayat ilmu, fikirkan masalah yang perlu diselesaikan dan tempat mendarat yang khusus. Sebagai contoh, sesetengah syarikat menggunakan dokumen sedia ada untuk menjana kandungan yang berkaitan dengan peperiksaan, latihan dan temu duga Walaupun perkataan panas teknikal ini begitu hangat, model penswastaan sedemikian akan lebih berkesan daripada GPT3.5 atau GPT4, kerana dalam senario ini Beberapa adegan. pra-pengeluaran telah melalui. Oleh itu, kami percaya bahawa model yang lebih khusus dan canggih akan menjadi trend utama dalam pembangunan masa depan.
2. Borang produk peta
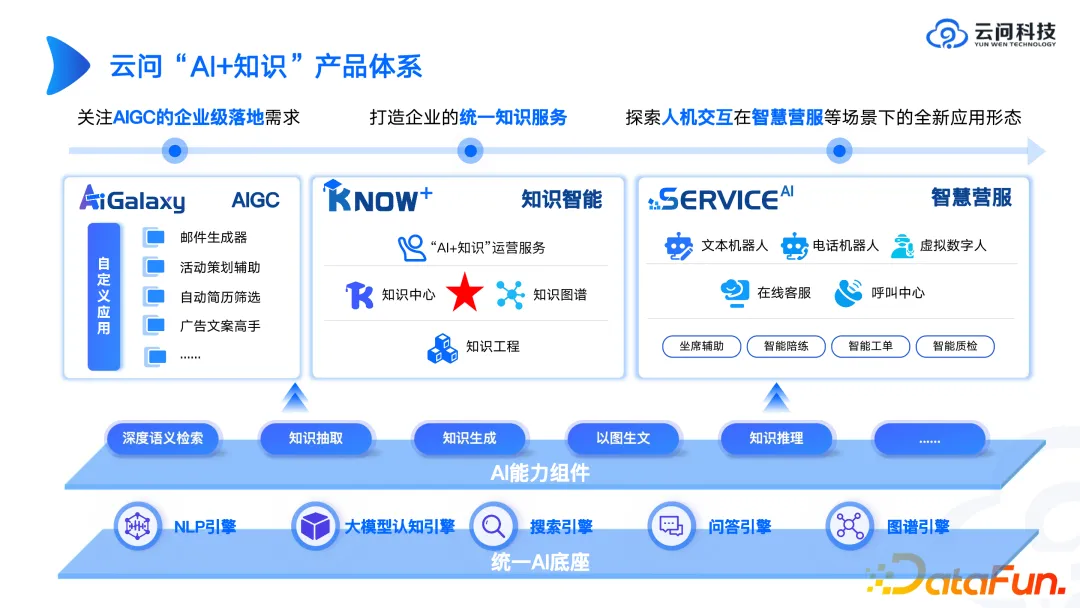
Di latar belakang di atas, apakah rupa bentuk produk peta? Seterusnya, kami akan memperkenalkan sistem produk "AI + knowledge" Teknologi Yunwen sebagai contoh.
Pertama sekali, mesti ada pangkalan AI bersatu Ini tidak boleh dilakukan oleh satu pasukan atau satu syarikat. Anda boleh menggunakan API pihak ketiga atau SDK bagi enjin model besar Dalam banyak kes, tidak perlu membina roda dari awal, kerana kemungkinan roda yang mengambil masa beberapa bulan untuk dibina tidak akan berkesan seperti roda terbuka. model sumber yang baru dikeluarkan. Oleh itu, untuk bahagian asas AI, adalah disyorkan untuk memikirkan lebih lanjut tentang cara menggabungkan teknologi pihak ketiga Jika anda membangunkannya sendiri, anda mesti berfikir dengan jelas tentang kelebihan Sudah tentu, adalah yang terbaik untuk memberikan permainan sepenuhnya nilai platform dan mengambil kira kedua-duanya.
Berkenaan komponen keupayaan AI, daripada beberapa pengalaman penghantaran kami, kami mendapati bahawa komponen keupayaan AI ini cenderung untuk menjual lebih baik daripada produk. Kerana banyak syarikat berharap untuk menggunakan komponen yang dibina oleh syarikat teknologi profesional untuk membina aplikasi lapisan atas mereka sendiri. Dalam era model besar, menjual komponen keupayaan AI adalah seperti menjual penyodok, dan lombong emas masih dilombong oleh syarikat besar sendiri.
Dari segi aplikasi lapisan atas, kami akan melaksanakannya dari tiga arah: aplikasi AIGC sendiri, kecerdasan pengetahuan dan perkhidmatan perniagaan pintar. Teroka ke arah mana akan ada nilai yang lebih besar. Graf pengetahuan diklasifikasikan oleh kami sebagai pautan teras dalam keseluruhan kecerdasan pengetahuan. Perlu diingatkan bahawa graf pengetahuan adalah teras tetapi bukan satu-satunya. Kami telah menghadapi banyak senario sebelum ini Pelanggan mempunyai sejumlah besar pangkalan data hubungan dan sejumlah besar dokumen tidak berstruktur Kami berharap kami dapat memasukkan semua sistem pengetahuan dan aset pengetahuan ini Kos untuk melakukannya adalah sangat tinggi. Kami percaya bahawa seni bina pengetahuan masa depan harus heterogen Sesetengah pengetahuan adalah dalam dokumen, beberapa pengetahuan dalam pangkalan data hubungan, dan beberapa pengetahuan mungkin datang dari rangkaian graf Pada akhirnya, apa yang perlu dilakukan oleh model besar adalah berdasarkan pelbagai. sumber heterogen Analisis komprehensif data struktur. Sebagai contoh, sekeping kecerdasan boleh mengekstrak beberapa penunjuk berangka daripada pangkalan data hubungan, mencari beberapa cadangan dalam dokumen, mencari beberapa maklumat sejarah daripada pesanan kerja, dan kemudian meletakkan semua kandungan bersama-sama untuk analisis. Beginilah cara kita memikirkan gabungan model besar dan graf pengetahuan. Dalam seni bina keseluruhan, model besar melakukan analisis akhir, dan graf pengetahuan membantu model besar mencari pengetahuan yang tersembunyi di belakangnya dengan lebih cepat dan tepat melalui sistem perwakilan pengetahuannya.
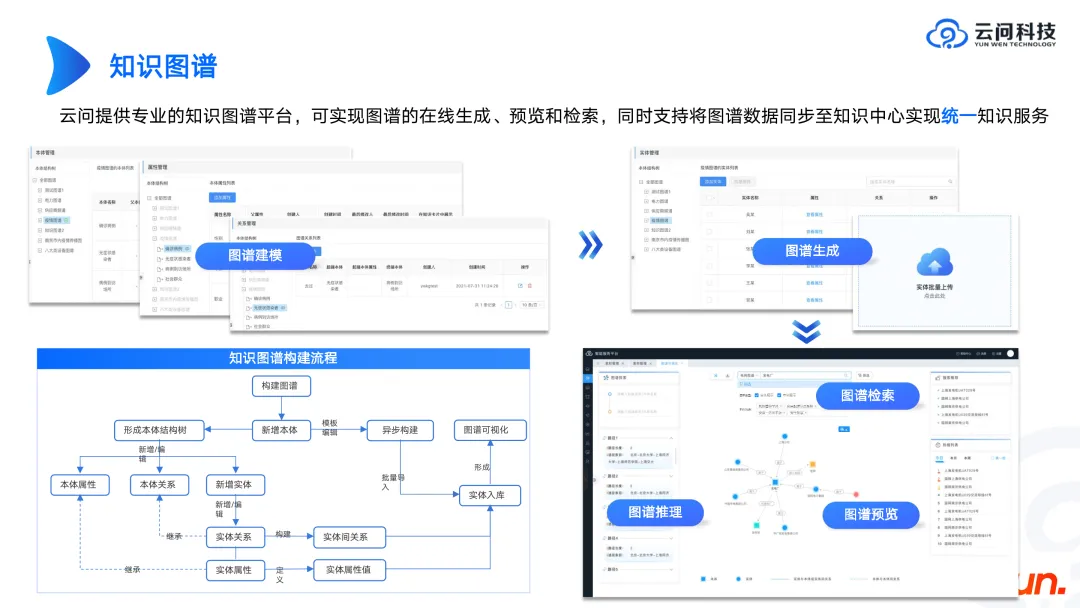
Kami telah membincangkan hubungan antara model besar dan peta sebelum ini, mari semak apa yang diperlukan oleh peta itu sendiri.
Pertama sekali, di belakang graf terdapat pangkalan data graf, seperti sumber terbuka Neo4j, Genius Graph dan beberapa jenama pangkalan data domestik. Graf pengetahuan dan pangkalan data graf adalah dua konsep yang berbeza Mencipta produk graf pengetahuan adalah setara dengan merangkum lapisan atas pangkalan data graf untuk mencapai pemodelan dan visualisasi graf yang pantas.
Apabila anda ingin membina produk graf pengetahuan, anda boleh terlebih dahulu merujuk kepada bentuk produk Neo4j atau produk graf pengetahuan beberapa pengeluar domestik utama, supaya anda boleh memahami secara kasar apa fungsi dan memautkan keperluan produk graf pengetahuan untuk melaksanakan. Apa yang lebih penting ialah mengetahui cara membina graf pengetahuan Ini nampaknya menjadi masalah perniagaan, kerana syarikat yang berbeza dan senario yang berbeza mempunyai graf yang berbeza. Sebagai seorang juruteknik, jika anda tidak memahami elektrik, peralatan, industri dan lain-lain, adalah mustahil untuk membina peta yang memuaskan perniagaan. Ia memerlukan komunikasi berterusan dengan perniagaan dan lelaran berterusan untuk akhirnya mendapat hasil. Proses perbincangan sebenarnya boleh kembali kepada intipati skema, dan mengemukakan satu set teori ontologi dan konsep logik skema. Sebaik sahaja skema dimuktamadkan, lebih ramai kakitangan yang berkaitan boleh terlibat untuk memperkayakan kandungan dan menambah baik lagi produk. Berikut adalah beberapa pengalaman kami setakat ini.

Berikut ialah pengenalan kepada ciri keseluruhan peta. Pada masa ini, graf pengetahuan masih berasaskan tiga kali ganda, di mana perhubungan semantik berbilang butiran dan berbilang peringkat seperti entiti, atribut dan perhubungan dibina. Dalam dunia perindustrian, kita sering menghadapi masalah yang tidak dapat diselesaikan dengan tiga kali ganda Apabila kita menggunakan nilai atribut entiti yang ditetapkan untuk menggambarkan dunia fizikal sebenar, banyak masalah akan timbul. Pada masa ini, kami akan melaksanakan syarat kekangan dalam bentuk CVT. Oleh itu, apabila membina graf pengetahuan, setiap orang mesti terlebih dahulu menunjukkan bahawa tiga kali ganda boleh menyelesaikan masalah semasa.
Satu perkara yang perlu ditegaskan ialah apabila membina peta, ia mesti dibina mengikut keperluan, kerana dunia ini tidak terhingga dan kandungan ilmu di dalamnya juga tidak terhingga. Pada mulanya, kita sering mempunyai visi untuk menggambarkan semua entiti yang wujud dalam dunia fizikal ke dalam dunia komputer kita. Masalah dengan ini ialah keseluruhan skema yang dibina pada akhirnya adalah terlalu kompleks dan tidak membantu untuk perniagaan sebenar. Sebagai contoh, fakta bahawa bumi beredar mengelilingi matahari, saya boleh membinanya dalam tiga kali ganda. Tetapi triplet ini tidak dapat menyelesaikan masalah sebenar yang saya hadapi sekarang, jadi saya mesti membina triplet mengikut keperluan.
Jadi bagaimana untuk menangani soalan akal? Banyak soalan memerlukan tiga kali ganda akal sehat. Kami fikir ini boleh diserahkan kepada model besar. Kami juga berharap graf pengetahuan dapat meneroka profesionalisme dan membina pengetahuan yang benar-benar relevan ke dalam graf. Kemudian model besar boleh berdasarkan akal dan digabungkan dengan pengetahuan terdahulu yang disediakan oleh graf pengetahuan yang tidak boleh diperolehi di medan terbuka untuk mencapai hasil yang lebih baik.

Pembinaan graf pengetahuan memerlukan kakitangan perniagaan dan kakitangan operasi untuk mereka bentuk bersama, termasuk definisi ontologi, perhubungan, atribut dan entiti, serta cara untuk menggambarkannya. Akhirnya, ia akan melibatkan satu soalan, iaitu kandungan apa yang hendak disampaikan kepada pengguna dari segi bentuk produk. Jika pengguna adalah pengguna akhir, maka hanya carian visual dan Soal Jawab perlu dibentangkan. Kerana jenis pelanggan ini tidak mengambil berat cara peta dibina, sama ada ia automatik atau manual.
Satu lagi isu yang sangat penting terlibat di sini, iaitu, walaupun dalam senario model besar, tidak semua peta boleh dibina secara automatik. Kos membina graf adalah sangat tinggi Daripada menghabiskan banyak tenaga untuk pemodelan graf, kita harus menghabiskan tenaga kita untuk penggunaan. Jika anda ingin mencapai penerimaan perniagaan, anda mungkin perlu bergantung pada pembinaan manual. Contohnya, jika jadual dengan format tertentu adalah kompleks merentas jadual, kita boleh cuba mencari garis dasar menggunakan model yang besar. Ini menukar tenaga daripada membina kepada memakan. Contohnya, jika kitaran projek berlangsung selama 100 hari, kami menghabiskan 70 hari membina peta dan menghabiskan 30 hari terakhir memikirkan senario aplikasi peta ini Atau kerana masa pembinaan awal dilanjutkan, tiada masa untuk berfikir tentang senario penggunaan yang berharga, yang mungkin membawa kepada persoalan besar. Mengikut pengalaman kami, anda harus meluangkan sedikit masa untuk membina, atau lalai untuk membina manual. Kemudian luangkan banyak masa memikirkan cara memaksimumkan nilai peta yang dibina.

Gambar di atas menunjukkan proses membina graf pengetahuan. Apabila membina ontologi, kita mesti menerima bahawa ontologi berubah, sama seperti struktur jadual pangkalan data itu sendiri juga boleh dikemas kini. Oleh itu, semasa mereka bentuk, pastikan anda mempertimbangkan keteguhan dan skalabilitinya. Sebagai contoh, apabila kita membuat peta jenis peralatan tertentu, kita harus mempertimbangkan keseluruhan sistem peralatan. Pada masa hadapan, anda mungkin perlu mencari peranti melalui sistem ini, dan anda juga harus memahami bahawa peranti lain di bawah sistem ini belum lagi membina peta, yang boleh dibina pada masa hadapan. Bawa nilai yang lebih besar kepada pengguna melalui keseluruhan sistem yang besar.
Persoalan yang sering kita dengar ialah, saya boleh dapatkan jawapannya melalui FAQ atau model besar, kenapa saya perlu menggunakan peta? Jawapan kami ialah jika kita mengaitkan pengetahuan semasa dengan peta, dunia yang kita lihat bukan lagi satu dimensi, tetapi dunia rangkaian Ini adalah nilai yang dapat direalisasikan oleh peta di sisi pengguna, dan Sukar untuk dicapai dengan teknologi lain. Pada masa ini, tumpuan semua orang selalunya pada magnitud dan algoritma lanjutan yang digunakan, tetapi sebenarnya, kita harus memikirkan pembinaan graf dari perspektif penggunaan dan penyelesaian masalah.

Sekarang model besar berleluasa, kita perlu mempertimbangkan gabungan model dan graf yang besar. Ia boleh dianggap bahawa graf adalah aplikasi lapisan atas, manakala model besar adalah keupayaan asas. Kami boleh memahami perkara yang dibawa oleh model besar kepada peta daripada senario yang berbeza.
Apabila membina graf, pengekstrakan maklumat boleh dilakukan melalui beberapa dokumen dan perkataan segera untuk menggantikan UIE asal, NER dan teknologi berkaitan lain, dengan itu meningkatkan lagi keupayaan pengekstrakan. Kita juga harus mempertimbangkan sama ada model besar atau model kecil adalah lebih baik dalam kes latihan data sifar, pukulan sedikit dan mencukupi. Tiada jawapan tunggal untuk soalan jenis ini, dan terdapat penyelesaian yang berbeza untuk senario yang berbeza dan set data yang berbeza. Ini adalah laluan pembinaan pengetahuan yang serba baharu. Pada masa ini, dalam senario sifar pukulan, model besar mempunyai keupayaan pengekstrakan yang lebih baik. Walau bagaimanapun, apabila saiz sampel meningkat, model kecil mempunyai lebih banyak kelebihan dari segi prestasi kos dan kelajuan inferens.
Di sisi pengguna, graf digunakan untuk menyelesaikan masalah penaakulan, seperti pertimbangan dasar, seperti menilai sama ada perusahaan boleh memenuhi dasar tertentu dan sama ada ia boleh menikmati faedah yang dinyatakan dalam polisi. Pendekatan sebelum ini ialah membuat pertimbangan melalui graf, peraturan dan ungkapan pernyataan. Pendekatan semasa adalah seperti Graph RAG, yang menggunakan soalan pengguna untuk mencari tiga kali ganda atau gandaan yang serupa dengan perusahaan semasa, dan menggunakan model besar untuk mendapatkan jawapan dan membuat kesimpulan. Oleh itu, banyak masalah penaakulan graf dan masalah pembinaan graf boleh diselesaikan melalui teknologi model besar.
Dari segi penyimpanan graf, struktur data pangkalan data graf dan graf itu sendiri adalah sangat penting Model besar tidak dapat mengendalikan teks panjang atau keseluruhan graf dalam jangka pendek, jadi penyimpanan graf adalah arah yang sangat penting. Seperti pangkalan data vektor, ia akan menjadi komponen yang sangat penting dalam ekosistem model besar masa hadapan. Aplikasi lapisan atas akan memutuskan sama ada untuk menggunakan komponen ini untuk menyelesaikan masalah sebenar.

Visualisasi graf adalah masalah bahagian hadapan dan perlu direka bentuk mengikut senario dan masalah yang perlu diselesaikan. Kami juga berharap teknologi ini boleh digunakan sebagai platform pertengahan untuk menyediakan keupayaan tertentu untuk memenuhi bentuk interaksi yang berbeza pada masa hadapan, seperti terminal mudah alih, PC, peranti pegang tangan, dsb. Kami hanya perlu menyediakan struktur, dan cara bahagian hadapan membuat dan mempersembahkan boleh ditentukan berdasarkan keperluan sebenar. Model besar juga akan menjadi cara untuk menggunakan struktur sedemikian. Apabila model atau ejen besar boleh menentukan cara memanggil graf berdasarkan keperluan, gelung tertutup boleh dibuka. Graf perlu dapat merangkum API yang lebih baik untuk menyesuaikan diri dengan panggilan daripada pelbagai aplikasi pada masa hadapan. Konsep platform tengah secara beransur-ansur dipandang serius Perkhidmatan bebas dan decoupled boleh digunakan dengan lebih meluas oleh semua pihak.
Sebagai contoh, kadangkala anda perlu mencari nilai tertentu yang tertinggal dalam jadual dalam dokumen Sukar untuk mengesan lokasinya melalui carian atau teknologi model besar Jika anda menggunakan keupayaan struktur graf untuk membentangkan kandungan , anda boleh Mendapatkan nilai peta ini dengan memanggil antara muka dalam sistem aplikasi, dan membentangkan dokumen di mana ia berada, atau hasil analisis model besar. Kaedah visualisasi ini adalah yang paling berkesan untuk pengguna. Ini juga merupakan kaedah Copilot yang popular pada masa ini, iaitu untuk bersama-sama menyelesaikan masalah dengan memanggil peta, carian atau keupayaan aplikasi lain, dan akhirnya menggunakan model besar untuk menjana "batu terakhir" untuk meningkatkan kecekapan.

Kini kami sering melakukan pelbagai integrasi asas pengetahuan dan graf Terdapat banyak projek ilmu yang muncul pada tahun ini. Sebelum ini, pengetahuan tersedia terutamanya untuk carian dan penggunaan. Dengan kemunculan model besar, semua orang mendapati bahawa pengetahuan juga boleh dibekalkan kepada model besar untuk digunakan. Oleh itu, setiap orang lebih memberi perhatian kepada sumbangan dan pembinaan ilmu. Kami sendiri mempunyai banyak pengetahuan, dan kami juga memerlukan sistem graf pengetahuan pihak ketiga kerana pengetahuan kami tidak tersusun, dan akan ada banyak pengetahuan yang sangat penting, seperti pesanan kerja, kes penyelenggaraan peralatan, dll., dan kami perlu memindahkan pengetahuan ini kepada Kandungan berstruktur disimpan sebelum ini Kandungan ini digunakan untuk carian, tetapi kini ia boleh digunakan untuk SFT pada model besar.
Pangkalan pengetahuan dan graf secara semula jadi boleh digabungkan, satu set produk perkhidmatan pengetahuan boleh diberikan kepada dunia luar. Daya hidup produk perkhidmatan pengetahuan ini sangat kuat, dan akan terdapat permintaan untuk pengetahuan sama ada dalam sistem OA, ERP, MIS atau PRM.
Apabila mengintegrasikan, anda mesti memberi perhatian yang besar kepada cara membezakan pengetahuan dan data. Pelanggan menyediakan sejumlah besar data, tetapi data ini mungkin bukan pengetahuan. Kita perlu mentakrifkan pengetahuan dari segi permintaan. Sebagai contoh, untuk sesuatu peralatan, perkara yang biasanya kita perlu tahu, seperti turun naik data semasa peralatan sedang berjalan, adalah semua data, dan masa kilang peralatan, masa penyelenggaraan terakhir, dsb., adalah pengetahuan. Bagaimana untuk mentakrifkan pengetahuan adalah sangat penting dan perlu dibina bersama dengan penyertaan dan bimbingan perniagaan. . Terutamanya dalam senario penghantaran, sama ada penghantaran trafik, penghantaran tenaga atau penghantaran tenaga kerja, semuanya dijalankan dalam bentuk agihan tugas. Sebagai contoh, jika berlaku kebakaran, berapa ramai orang, kenderaan, dsb. yang perlu dihantar Beberapa data yang berkaitan perlu disoal semasa menjadualkan Masalah semasa selalunya bukan tiada hasil dapat ditemui, tetapi terlalu banyak kandungan dikembalikan, tetapi tiada maklumat yang benar-benar berguna boleh diberikan. Oleh kerana penggunaan pengetahuan masih kekal dalam carian kata kunci, semua dokumen yang mengandungi perkataan "api" akan dipaparkan. Untuk persembahan yang lebih baik, anda boleh menggunakan graf. Contohnya, apabila mereka bentuk ontologi "kebakaran", ontologi atasnya adalah bencana Untuk entiti "kebakaran", anda boleh mereka bentuk langkah berjaga-jaga, langkah perlindungan dan kes pengalamannya. Pisahkan ilmu melalui kandungan ini. Dengan cara ini, apabila pengguna memasuki "api", konteks peta yang berkaitan dan perkara yang perlu dilakukan seterusnya akan dibentangkan.
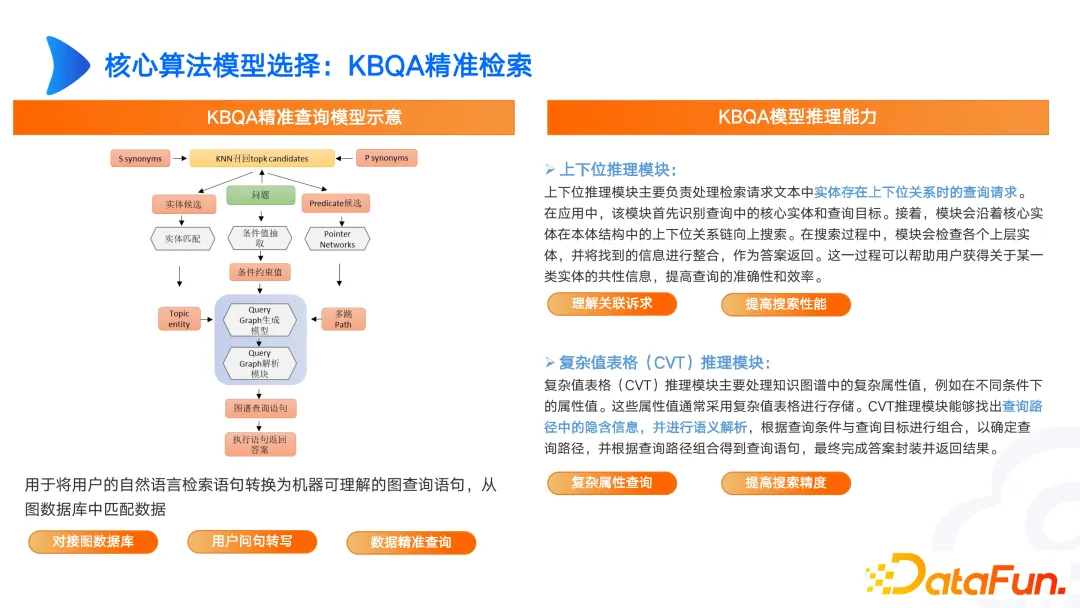
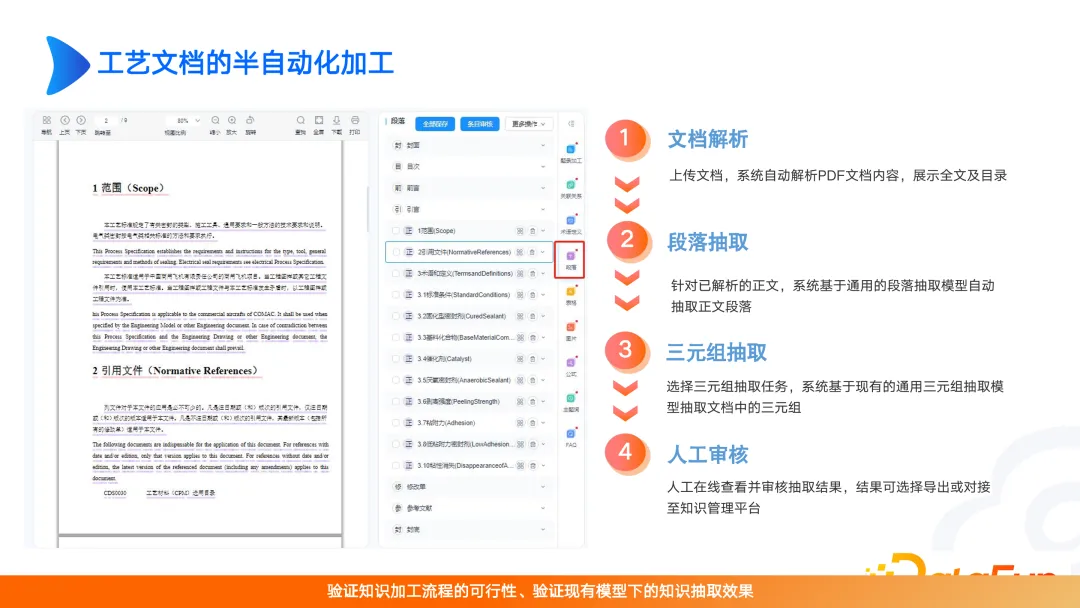
Dalam menjadualkan senario berkaitan, anda harus memberi perhatian kepada hala tuju Ejen. Ejen sangat penting untuk penjadualan kerana penjadualan itu sendiri adalah senario pelbagai tugas. Keputusan yang dikembalikan oleh peta akan lebih tepat dan lebih kaya. Terdapat juga banyak senario aplikasi untuk peranti pintar. Maklumat peralatan akan disimpan dalam sistem yang berbeza Contohnya, maklumat kilang disimpan dalam manual produk, maklumat penyelenggaraan disimpan dalam pesanan kerja penyelenggaraan, status operasi disimpan dalam sistem pengurusan peralatan, dan status pemeriksaan disimpan dalam sistem pemeriksaan industri. . Masalah besar yang dihadapi oleh industri ialah terdapat terlalu banyak sistem. Jika anda ingin menanyakan maklumat peranti, anda perlu menanyakannya daripada berbilang sistem dan data dalam sistem ini tidak bersambung antara satu sama lain. Pada masa ini, sistem diperlukan yang boleh membuka sambungan dan mengaitkan serta memetakan semua kandungan. Pangkalan pengetahuan dengan graf pengetahuan sebagai terasnya boleh menyelesaikan masalah ini. Graf pengetahuan boleh memasukkan atribut, medan, sumber medan, dsbnya yang berkaitan melalui ontologi, dan boleh menerangkan serta mengaitkan hubungan siri dan selari antara pelbagai sistem dari bawah. Tetapi apabila membina graf anda, perlu diingat bahawa anda perlu mereka bentuk dan membina graf anda dengan sewajarnya. Apabila banyak syarikat membina peta, mereka akan memindahkan semua data dari pusat data melalui teknologi D2R Peta ini sebenarnya tidak mempunyai makna. Apabila membina peta, anda mesti mempertimbangkan hubungan antara peta dinamik dan peta statik. Terdapat juga banyak senario aplikasi dan teknik reka bentuk dalam bidang pemasaran pintar dan AI tenaga pelbagai senario, yang tidak akan dibincangkan di sini dan boleh dibincangkan kemudian. Apabila membina graf, reka bentuk seni bina adalah sangat penting. Cara mengintegrasikan perpustakaan dan proses asas dengan pembinaan dan penggunaan graf. Terdapat banyak butiran untuk difikirkan tentang bagaimana ia akhirnya dihantar. Anda boleh merujuk pautan yang disenaraikan dalam rajah di atas untuk reka bentuk dan latihan. Kami juga telah melakukan beberapa kajian dalam graf KBQA, seperti bit atas dan bawah, pertanyaan CVT graf, dsb. Sebagai contoh, dalam senario perubatan, demam dan sakit kepala dikaitkan dengan gambaran badan yang tidak normal. Apabila terdapat perbezaan antara perwakilan pengguna dan perwakilan profesional, kami boleh menyelesaikannya melalui CVT penaakulan unggul dan rendah. Graf yang dibina pada masa ini mungkin hanya penjajaran entiti seperti SPO atau multi-hop atau TransE. Walau bagaimanapun, dalam senario kompleks sebenar, CVT perlu dilaksanakan dalam kombinasi dengan kedudukan atas dan bawah. Terdapat juga banyak kertas kerja yang berprestasi baik pada set data bahasa Inggeris, tetapi keputusan pada set data bahasa Cina tidak sesuai. Oleh itu, kita perlu mereka bentuk berdasarkan keperluan kita sendiri dan terus berulang untuk mencapai hasil yang baik. Pemprosesan dokumen separa automatik, termasuk penghuraian dokumen, pengekstrakan perenggan, pengekstrakan tiga kali ganda dan semakan manual. Langkah semakan manual ini sering diabaikan, terutamanya selepas ketibaan model besar, orang ramai kurang memberi perhatian kepada semakan manual. Malah, jika pemprosesan data dan tadbir urus data dilakukan, kesan model akan bertambah baik. Oleh itu, kita mesti mempertimbangkan bahawa senario yang akhirnya ingin kita selesaikan mesti mempunyai nilai yang tinggi, dan kita juga mesti memberi perhatian kepada di mana sumber dilaburkan, sama ada dalam pembinaan peta atau pengoptimuman model besar. Tanpa pertimbangan ini, produk akan mudah diganti atau dicabar. Gambar di atas menunjukkan produk pengurusan kitaran hayat peranti Teknologi Yunwen. Senario sedemikian direalisasikan melalui modul pertengahan ringan dan pembinaan aplikasi lapisan atas dalam senario yang berbeza. Daya hidup modul ini jauh lebih bertenaga daripada daya hidup sistem graf pengetahuan itu sendiri. Menjual standalone atau middleware sahaja tidak sesuai dalam medan graf, terutamanya dalam senario industri. Banyak masalah industri adalah sangat kompleks dari perspektif pelanggan dan tidak dapat diselesaikan dengan gambar rajah atau model besar. Apa yang perlu kita lakukan ialah meyakinkan pelanggan daripada kesannya. Dalam proses transformasi pintar industri, terdapat banyak titik aplikasi dalam R&D dan reka bentuk, pengurusan pengeluaran, pengurusan bekalan, pemasaran pra-jualan dan perkhidmatan komprehensif. Gambar di atas adalah contoh senario aplikasi peta peralatan yang rosak. Dalam senario ini kami tidak memasukkan semua elemen graf, seperti status pengendalian peralatan dan data mudah dalam pangkalan data hubungan. Kami percaya bahawa untuk penyelenggaraan peralatan, kami memberi tumpuan terutamanya kepada tiga jenis data Jenis pertama ialah maklumat asas peralatan, seperti masa meninggalkan kilang, pengilang, dan berapa lama ia telah beroperasi jenis adalah kesalahan, seperti nama kesalahan, atasan dan bawahan, kesalahan tersebut Apakah kecacatan yang akan menyebabkan, jenis kesalahan apa yang akan menyebabkan jenis kesalahan, dll peralatan apa. Dengan menyambungkan tiga jenis data ini, kita boleh membina graf gelung tertutup kecil. Pada masa hadapan, ia juga boleh dilanjutkan berdasarkan data dinamik. Oleh itu, apabila membina graf, kami lebih suka membuat graf yang kecil dan cantik dengan adegan gelung tertutup. Ia bukan peta yang hanya mengejar tahap magnitud yang tinggi, tetapi tidak dapat memenuhi keperluan pengguna. Oleh itu, apabila membina graf pengetahuan industri, kita mesti bermula daripada senario tertentu dan membina graf dengan menganalisis keperluan senario, untuk mencapai pelaksanaan dan aplikasi yang lebih baik. 



Atas ialah kandungan terperinci Amalan lanjutan graf pengetahuan industri. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Google dan Stanford bersama-sama mengeluarkan artikel: Mengapa kita mesti menggunakan model besar?
- Bagaimana untuk menggunakan PHP untuk pembelajaran pemindahan mendalam dan graf pengetahuan?
- Membangunkan fungsi carian graf pengetahuan menggunakan PHP dan Manticore Search
- Bagaimana untuk menggunakan C++ untuk pembinaan dan penaakulan graf pengetahuan yang cekap?