
Rumah >Peranti teknologi >AI >Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-06-11 15:57:201108semak imbas
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar.

Selaraskan model atau lakukan penalaan arahan untuk membolehkan model belajar cara menggunakan sepenuhnya pengetahuan ini dan cara bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input yang dicipta oleh anotasi manusia atau LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan memasukkannya ke dalam parameter.
Bagaimana model menyepadukan pengetahuan tambahan baharu ini
Pada tahap mekanistik, kami tidak tahu bagaimana interaksi ini berlaku. Menurut sesetengah pihak, pendedahan kepada pengetahuan baharu ini boleh menyebabkan model tersebut berhalusinasi. Ini kerana model dilatih untuk menjana fakta yang tidak berdasarkan pengetahuan sedia ada (atau mungkin bercanggah dengan pengetahuan terdahulu model). Terdapat juga pengetahuan tentang rupa model yang mungkin dihadapi (mis. entiti yang kurang kerap muncul dalam korpus pra-latihan).
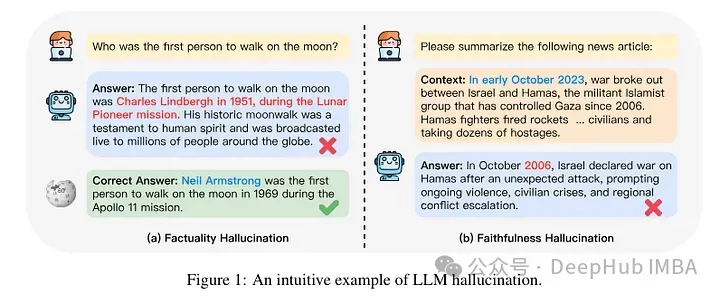
Jadi kajian yang diterbitkan baru-baru ini memfokuskan pada menganalisis perkara yang berlaku apabila model diberi pengetahuan baharu melalui penalaan halus. Penulis meneliti secara terperinci apa yang berlaku kepada model yang diperhalusi dan bagaimana ia bertindak balas selepas memperoleh pengetahuan baharu.
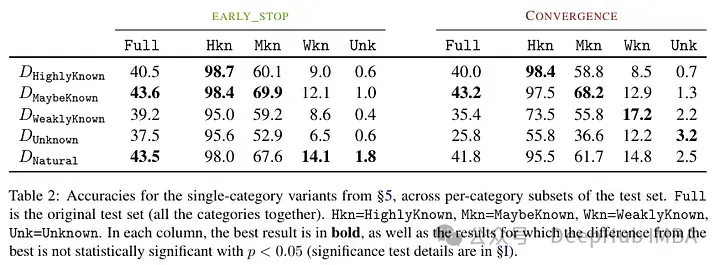
Mereka cuba mengklasifikasikan contoh di peringkat pengetahuan selepas penalaan halus. Pengetahuan yang wujud dalam contoh baharu mungkin tidak konsisten sepenuhnya dengan pengetahuan model. Contoh boleh diketahui atau tidak diketahui. Walaupun ia diketahui, ia mungkin sangat dikenali, ia mungkin diketahui, atau ia mungkin pengetahuan yang kurang diketahui.
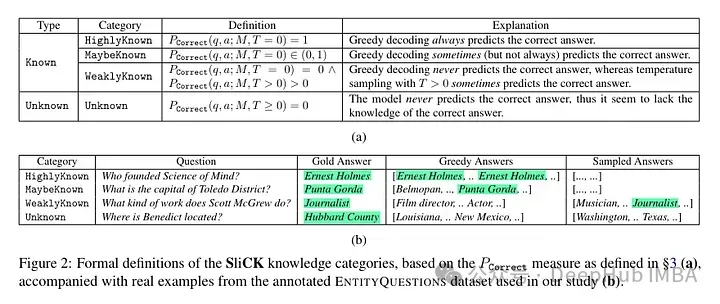
Kemudian penulis menggunakan model (PaLM 2-M) untuk memperhalusinya. Setiap contoh nudge terdiri daripada pengetahuan fakta (subjek, hubungan, objek). Ini adalah untuk membolehkan model menanyakan pengetahuan ini dengan soalan khusus, tiga kali ganda tertentu (cth., "Di manakah Paris?"), dan jawapan kebenaran asas (cth., "Perancis"). Dalam erti kata lain, mereka menyediakan model dengan beberapa pengetahuan baharu, dan kemudian membina semula rangkap tiga ini menjadi soalan (pasangan soal-jawab) untuk menguji pengetahuannya. Mereka mengumpulkan semua contoh ini ke dalam kategori yang dibincangkan di atas dan kemudian menilai jawapannya.
Keputusan ujian selepas memperhalusi model: Perkadaran tinggi fakta yang tidak diketahui membawa kepada kemerosotan prestasi (yang tidak diimbangi oleh masa penalaan halus yang lebih lama).
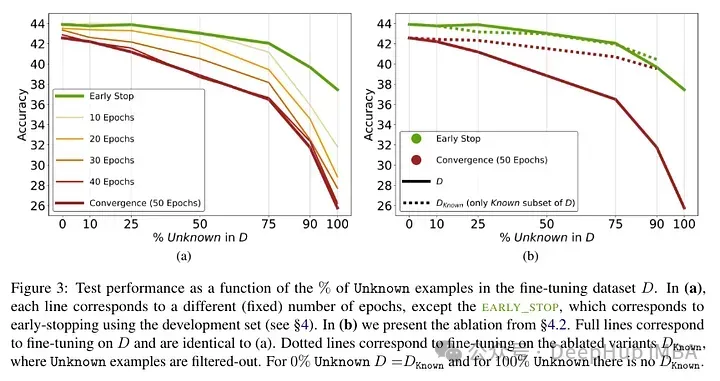
Fakta yang tidak diketahui mempunyai kesan yang hampir neutral pada nombor zaman yang lebih rendah tetapi menjejaskan prestasi pada nombor zaman yang lebih tinggi. Jadi contoh yang tidak diketahui nampaknya berbahaya, tetapi kesan negatifnya ditunjukkan terutamanya pada peringkat latihan yang kemudian. Graf di bawah menunjukkan ketepatan latihan sebagai fungsi tempoh penalaan halus untuk subset yang diketahui dan tidak diketahui bagi contoh set data. Ia boleh dilihat bahawa model mempelajari contoh yang tidak diketahui pada peringkat kemudian.
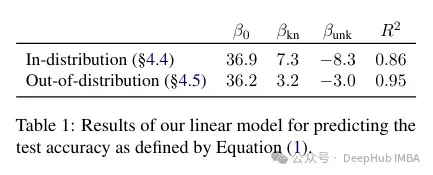
Akhir sekali, memandangkan contoh Tidak diketahui adalah contoh yang berkemungkinan memperkenalkan pengetahuan fakta baharu, kadar penyesuaian yang sangat perlahan menunjukkan bahawa LLM bergelut untuk memperoleh pengetahuan fakta baharu melalui penalaan halus, sebaliknya mereka belajar untuk mendedahkan pengetahuan sedia ada mereka menggunakan contoh-contoh yang Diketahui. Keputusan menunjukkan bahawa terdapat hubungan linear yang kuat antara contoh yang tidak diketahui yang menjejaskan prestasi dan contoh yang diketahui meningkatkan prestasi, hampir sama kuat (pekali korelasi dalam regresi linear ini sangat rapat).
Penalaan halus ini bukan sahaja memberi impak pada prestasi dalam kes tertentu, tetapi juga mempunyai impak yang luas pada pengetahuan model. Pengarang menggunakan set ujian luar pengedaran (OOD) untuk menunjukkan bahawa sampel yang tidak diketahui berbahaya kepada prestasi OOD. Menurut pengarang, ini juga berkaitan dengan kejadian halusinasi:
Secara keseluruhannya, pandangan kami memindahkan merentas perhubungan Ini pada asasnya menunjukkan bahawa penalaan halus pada contoh Tidak diketahui seperti "Di manakah [E1] terletak?", boleh menggalakkan halusinasi pada soalan yang kelihatan tidak berkaitan, seperti "Siapa yang mengasaskan [E2]?".
Satu lagi hasil yang menarik ialah keputusan terbaik diperoleh bukan dengan contoh yang terkenal, tetapi dengan contoh yang berpotensi diketahui. Dalam erti kata lain, contoh-contoh ini membolehkan model mengeksploitasi pengetahuan terdahulunya dengan lebih baik (fakta yang terlalu terkenal tidak akan memberi kesan berguna pada model).
Sebaliknya, fakta yang tidak diketahui dan kurang jelas menjejaskan prestasi model, dan penurunan ini disebabkan oleh peningkatan dalam halusinasi.
Karya ini menyerlahkan risiko dalam menggunakan penalaan halus diselia untuk mengemas kini pengetahuan LLM, sambil kami mengemukakan bukti empirikal bahawa memperoleh pengetahuan baharu melalui penalaan halus dikaitkan dengan halusinasi w.r.t pengetahuan sedia ada.
, pengetahuan yang tidak diketahui ini boleh menjejaskan prestasi (menjadikan penalaan halus hampir tidak berguna). Dan melabelkan pengetahuan yang tidak diketahui ini dengan "Saya tidak tahu" boleh membantu mengurangkan kesakitan ini. .
Ringkasnya, jika pengetahuan yang tidak diketahui muncul semasa penalaan halus, ia akan menyebabkan kerosakan pada model. Penurunan prestasi ini dikaitkan dengan peningkatan dalam halusinasi. Sebaliknya, mungkin contoh yang diketahui mempunyai kesan yang bermanfaat. Ini menunjukkan bahawa model mengalami kesukaran mengintegrasikan pengetahuan baru. Iaitu, terdapat konflik antara apa yang telah dipelajari oleh model dan bagaimana ia menggunakan pengetahuan baru. Ini mungkin berkaitan dengan penjajaran dan penalaan arahan (tetapi kertas ini tidak mengkaji perkara ini).
Jadi, jika anda ingin menggunakan model dengan pengetahuan domain tertentu, makalah ini mengesyorkan agar lebih baik menggunakan RAG. Dan hasil yang ditandakan "Saya tidak tahu" boleh mencari strategi lain untuk mengatasi batasan penalaan halus ini.
Kajian ini sangat menarik, menunjukkan bahawa faktor penalaan halus dan cara menyelesaikan konflik antara pengetahuan lama dan baru masih tidak jelas. Itulah sebabnya kami menguji keputusan sebelum dan selepas penalaan halus.
Atas ialah kandungan terperinci Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!