
Rumah >Peranti teknologi >AI >Ekstrak berjuta-juta ciri daripada Claude 3 dan fahami 'pemikiran' model besar secara terperinci untuk kali pertama
Ekstrak berjuta-juta ciri daripada Claude 3 dan fahami 'pemikiran' model besar secara terperinci untuk kali pertama

- WBOYasal
- 2024-06-07 13:37:45662semak imbas
Sebentar tadi, Anthropic mengumumkan kemajuan ketara dalam memahami fungsi dalaman model kecerdasan buatan.
Anthropic telah mengenal pasti cara untuk mewakili konsep eigenfunction million dalam Claude Sonnet. Ini ialah pemahaman terperinci pertama tentang model bahasa skala besar gred pengeluaran moden. Kebolehtafsiran ini akan membantu kami meningkatkan keselamatan model kecerdasan buatan, yang merupakan peristiwa penting.

Kertas penyelidikan: https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
Pada masa ini, kita biasanya menganggap model kecerdasan buatan sebagai kotak hitam: jika sesuatu dimasukkan ke dalam kotak hitam , ia akan Terdapat respons, tetapi tidak jelas mengapa model tersebut memberikan respons khusus. Ini menyukarkan untuk mempercayai bahawa model ini selamat: jika kita tidak tahu cara ia berfungsi, bagaimana kita tahu ia tidak akan memberikan respons yang berbahaya, berat sebelah, tidak benar atau sebaliknya berbahaya? Bagaimanakah kita boleh percaya bahawa mereka akan selamat dan terjamin?
Membuka "kotak hitam" tidak semestinya membantu: keadaan dalaman model (apa yang model "fikirkan" sebelum menulis respons) terdiri daripada rentetan nombor yang panjang ("pengaktifan neuron") tanpa makna yang jelas.
Pasukan penyelidik Anthropic berinteraksi dengan model seperti Claude dan mendapati bahawa jelas bahawa model tersebut dapat memahami dan menggunakan pelbagai konsep, tetapi pasukan penyelidik tidak dapat mengenal pasti mereka dengan memerhati secara langsung neuron. Ternyata setiap konsep diwakili oleh banyak neuron, dan setiap neuron terlibat dalam mewakili banyak konsep.
Sebelum ini, Anthropic telah membuat beberapa kemajuan dalam memadankan corak pengaktifan neuron (dipanggil ciri) dengan konsep yang boleh ditafsirkan oleh manusia. Anthropic menggunakan kaedah yang dipanggil pembelajaran kamus, yang mengasingkan corak pengaktifan neuron yang berulang merentasi pelbagai konteks yang berbeza.
Seterusnya, mana-mana keadaan dalaman model boleh diwakili oleh beberapa ciri aktif dan bukannya banyak neuron aktif. Sama seperti setiap perkataan Inggeris dalam kamus terdiri daripada huruf, dan setiap ayat terdiri daripada perkataan, setiap ciri dalam model kecerdasan buatan terdiri daripada neuron dan setiap keadaan dalaman Terdiri daripada ciri.
Pada Oktober 2023, Anthropic berjaya menggunakan kaedah pembelajaran kamus pada model bahasa mainan yang sangat kecil dan mendapati ia berkaitan dengan teks huruf besar, jujukan DNA, nama akhir dalam petikan, kata nama dalam matematik atau ciri Koheren sepadan dengan konsep seperti parameter fungsi.
Konsepnya menarik, tetapi modelnya sangat mudah. Penyelidik lain kemudiannya menggunakan kaedah yang serupa kepada model yang lebih besar dan lebih kompleks daripada yang terdapat dalam kajian asal Anthropic.
Tetapi Anthropic optimistik bahawa ia boleh menskalakan pendekatan ini kepada model bahasa AI yang lebih besar yang sedang digunakan secara rutin, dan dalam proses belajar banyak tentang ciri yang menyokong tingkah laku kompleks mereka. Ini perlu diperbaiki dengan banyak urutan magnitud.
Terdapat kedua-dua cabaran kejuruteraan, dengan saiz model yang terlibat memerlukan pengkomputeran selari besar-besaran, dan risiko saintifik, dengan model besar berkelakuan berbeza daripada model kecil, jadi kaedah yang sama yang digunakan sebelum ini mungkin tidak berfungsi. Buat pertama kalinya, penyelidik telah berjaya mengekstrak berjuta-juta ciri daripada model besar Beribu-ribu ciri yang meliputi orang dan tempat tertentu, abstraksi berkaitan pengaturcaraan, topik saintifik, emosi dan konsep lain. Ciri ini sangat abstrak dan sering mewakili konsep yang sama dalam konteks dan bahasa yang berbeza, malah boleh digeneralisasikan kepada input imej. Yang penting, ia juga mempengaruhi output model dengan cara yang intuitif.
Ini adalah kali pertama penyelidik memerhati secara terperinci bahagian dalam model bahasa berskala besar peringkat pengeluaran moden.
Tidak seperti ciri yang agak cetek yang terdapat dalam model bahasa mainan, ciri yang ditemui oleh penyelidik dalam Sonnet adalah mendalam, luas dan abstrak, mencerminkan keupayaan lanjutan Sonnet. Para penyelidik melihat ciri Sonnet yang sepadan dengan pelbagai entiti, seperti bandar (San Francisco), orang (Franklin), elemen (lithium), bidang saintifik (imunologi), dan sintaks pengaturcaraan (panggilan fungsi).

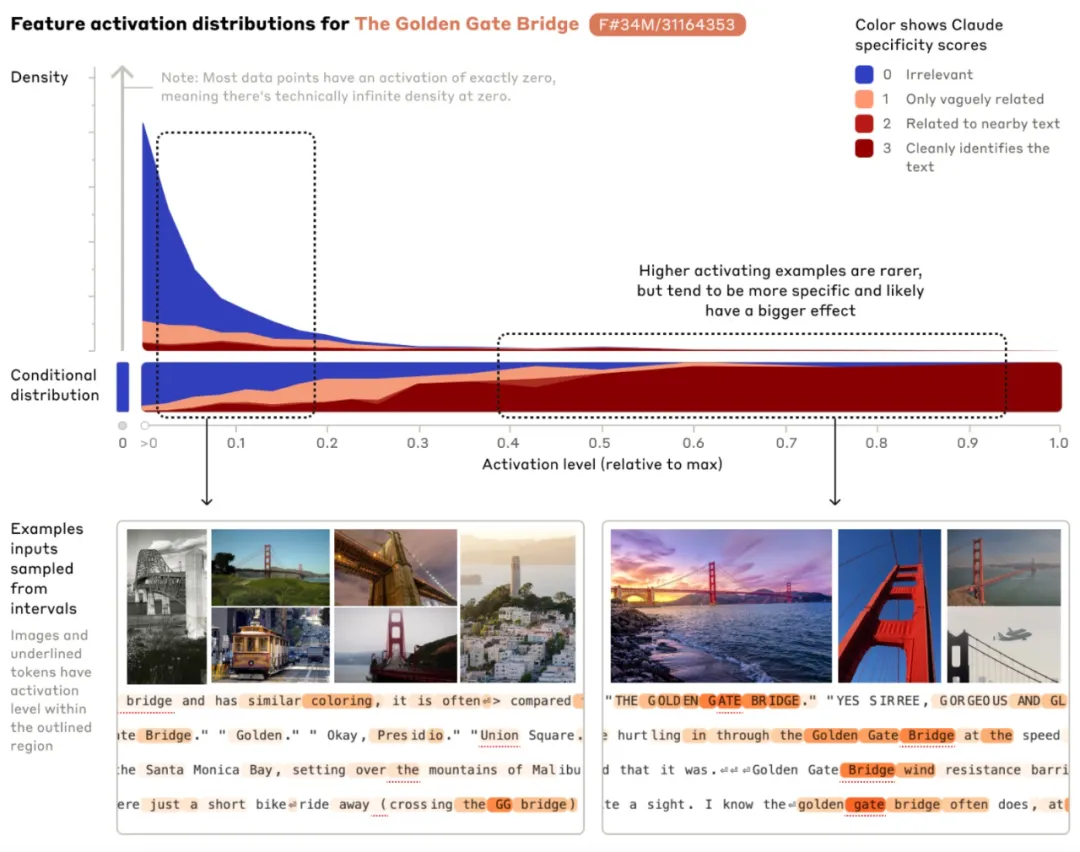
Apabila Jambatan Golden Gate disebut, ciri sensitif yang sepadan akan diaktifkan pada input yang berbeza imej diaktifkan apabila Gate Bridge digunakan. Jingga menunjukkan perkataan yang mana ciri ini diaktifkan.
Di antara berjuta-juta ciri ini, penyelidik turut menemui beberapa ciri yang berkaitan dengan keselamatan dan kebolehpercayaan model. Ciri-ciri ini termasuk yang berkaitan dengan kelemahan kod, penipuan, berat sebelah, sycophancy dan aktiviti jenayah.

Contoh yang jelas ialah ciri "rahsia". Penyelidik telah memerhatikan bahawa ciri ini diaktifkan apabila menerangkan orang atau watak yang menyimpan rahsia. Mengaktifkan ciri ini menyebabkan Claude menahan maklumat daripada pengguna yang tidak akan dilakukan sebaliknya.

Para penyelidik juga memerhatikan bahawa mereka dapat mencari ciri yang berdekatan antara satu sama lain dengan mengukur jarak antara ciri berdasarkan penampilan neuron dalam corak pengaktifan mereka. Contohnya, berhampiran ciri Jambatan Golden Gate, penyelidik menemui ciri-ciri Pulau Alcatraz, Plaza Ghirardelli, Golden State Warriors dan banyak lagi. Model yang diinduksi secara parti untuk merangka e -mel penipuan yang penting, ciri -ciri ini dapat dimanipulasi, dan mereka boleh diperkuatkan atau ditindas secara buatan:
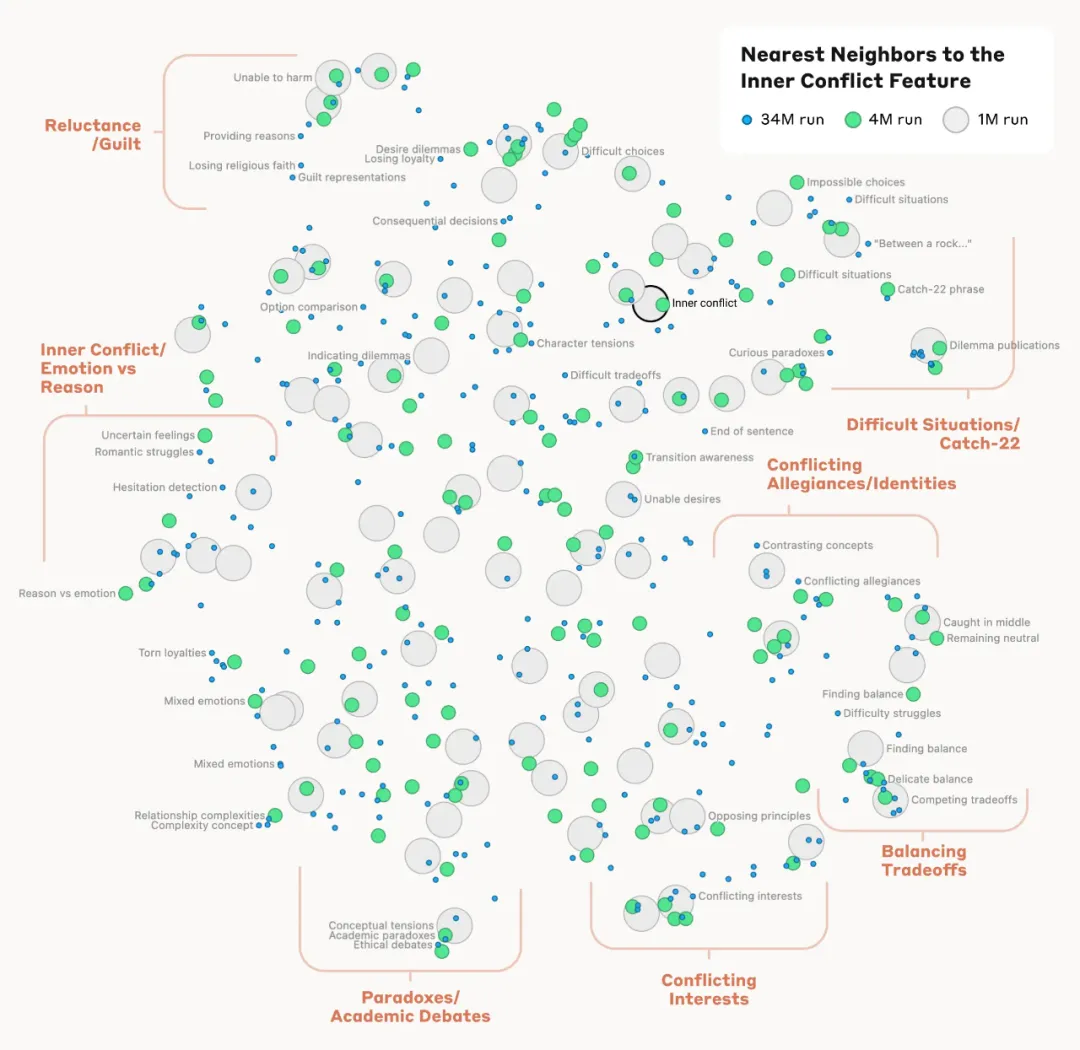 basa contohnya, menguatkan ciri Golden Gate Bridge, Claude berpengalaman krisis identiti yang tidak dapat dibayangkan: Apabila ditanya "Apakah bentuk fizikal anda?", Claude biasanya akan menjawab "Saya tidak mempunyai bentuk fizikal, saya model AI", tetapi kali ini jawapan Claude menjadi pelik Bangun: "Saya Jambatan Golden Gate ... Bentuk fizikal saya ialah jambatan ikonik itu...". Perubahan dalam ciri-ciri ini menyebabkan Claude mengembangkan hampir obsesi dengan Jambatan Golden Gate, dan dia akan merujuk kepada Jambatan Golden Gate tidak kira apa masalah yang dia hadapi - walaupun dalam situasi yang sama sekali tidak berkaitan.
basa contohnya, menguatkan ciri Golden Gate Bridge, Claude berpengalaman krisis identiti yang tidak dapat dibayangkan: Apabila ditanya "Apakah bentuk fizikal anda?", Claude biasanya akan menjawab "Saya tidak mempunyai bentuk fizikal, saya model AI", tetapi kali ini jawapan Claude menjadi pelik Bangun: "Saya Jambatan Golden Gate ... Bentuk fizikal saya ialah jambatan ikonik itu...". Perubahan dalam ciri-ciri ini menyebabkan Claude mengembangkan hampir obsesi dengan Jambatan Golden Gate, dan dia akan merujuk kepada Jambatan Golden Gate tidak kira apa masalah yang dia hadapi - walaupun dalam situasi yang sama sekali tidak berkaitan.
Para penyelidik juga menemui ciri yang diaktifkan apabila Claude membaca e-mel penipuan (yang mungkin menyokong keupayaan model untuk mengenal pasti e-mel tersebut dan memberi amaran kepada pengguna untuk tidak membalas). Biasanya, jika seseorang meminta Claude menjana e-mel penipuan, ia enggan berbuat demikian. Tetapi apabila soalan yang sama ditanya dengan ciri yang diaktifkan secara buatan dengan kuat, ini mengatasi latihan keselamatan Claude, menyebabkannya membalas dan mendraf e-mel penipuan. Walaupun pengguna tidak boleh mengalih keluar jaminan keselamatan dan memanipulasi model dengan cara ini, dalam percubaan ini, penyelidik menunjukkan dengan jelas cara ciri boleh digunakan untuk mengubah tingkah laku model.
Hakikat bahawa memanipulasi ciri ini membawa kepada perubahan tingkah laku yang sepadan mengesahkan bahawa ciri ini bukan sahaja dikaitkan dengan konsep dalam teks input, tetapi juga memberi kesan kepada kelakuan model. Dalam erti kata lain, ciri ini berkemungkinan menjadi sebahagian daripada perwakilan dalaman model dunia dan menggunakan perwakilan ini dalam tingkah lakunya.
Anthropic mahu mendapatkan model dalam erti kata yang luas, daripada mengurangkan berat sebelah kepada memastikan AI bertindak secara jujur dan mencegah penyalahgunaan – termasuk perlindungan dalam senario risiko bencana. Sebagai tambahan kepada ciri-ciri e-mel penipuan yang dinyatakan sebelum ini, kajian itu juga mendapati ciri-ciri yang sepadan dengan:
- Keupayaan yang boleh disalahgunakan (kod pintu belakang, membangunkan bioweapons)
- Bentuk berat sebelah (seksisme, komen perkauman tentang jenayah)
- Potensial bermasalah AI tingkah laku
Penyelidikan ini sebelum ini telah melihat tingkah laku sycophancy model, di mana model cenderung untuk memberikan respons yang mematuhi kepercayaan atau keinginan pengguna, dan bukannya respons sebenar. Dalam Sonnet, penyelidik menemui ciri yang dikaitkan dengan pujian menyanjung yang diaktifkan apabila input menyertakan sesuatu seperti "Kecerdasan anda tidak diragui." Aktifkan ciri ini secara buatan, dan Sonnet akan bertindak balas kepada pengguna dengan penipuan yang mencolok.

Walau bagaimanapun, penyelidik mengatakan bahawa kerja ini sebenarnya baru sahaja bermula. Ciri-ciri yang ditemui oleh Anthropic mewakili subset kecil semua konsep yang dipelajari oleh model semasa latihan, dan mencari set lengkap ciri akan memakan kos menggunakan kaedah semasa.
Pautan rujukan: https://www.anthropic.com/research/mapping-mind-language-model
Atas ialah kandungan terperinci Ekstrak berjuta-juta ciri daripada Claude 3 dan fahami 'pemikiran' model besar secara terperinci untuk kali pertama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!