
Rumah >Peranti teknologi >AI >Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-06-07 12:05:271192semak imbas
1. . Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens.
Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. Untuk tujuan ini, kami mula-mula mencadangkan peruntukan dwi yang konsisten untuk latihan YOLO tanpa NMS, yang pada masa yang sama membawa prestasi kompetitif dan kependaman inferens yang rendah. Selain itu, strategi reka bentuk model dipacu ketepatan kecekapan keseluruhan YOLO juga diperkenalkan.
Pelbagai komponen YOLO telah dioptimumkan sepenuhnya dari dua perspektif iaitu meningkatkan kecekapan dan ketepatan, dengan ketara mengurangkan overhed pengkomputeran dan meningkatkan keupayaan. Hasil kerja ialah generasi baharu siri YOLO untuk pengesanan sasaran hujung ke hujung masa nyata, yang dipanggil YOLOv10. Eksperimen yang meluas menunjukkan bahawa YOLOv10 mencapai prestasi dan kecekapan terkini pada pelbagai skala model. Contohnya, di bawah AP serupa pada COCO, YOLOv10-Sis1.8 adalah 1.8 kali lebih pantas daripada RT-DETR-R18, dan bilangan parameter serta FLOP yang dikongsi pada masa yang sama ialah 2.8 kali. Berbanding dengan YOLOv9-C, di bawah prestasi yang sama, YOLOv10-B mempunyai pengurangan 46% dalam kependaman dan pengurangan 25% dalam parameter.
II
Latar belakang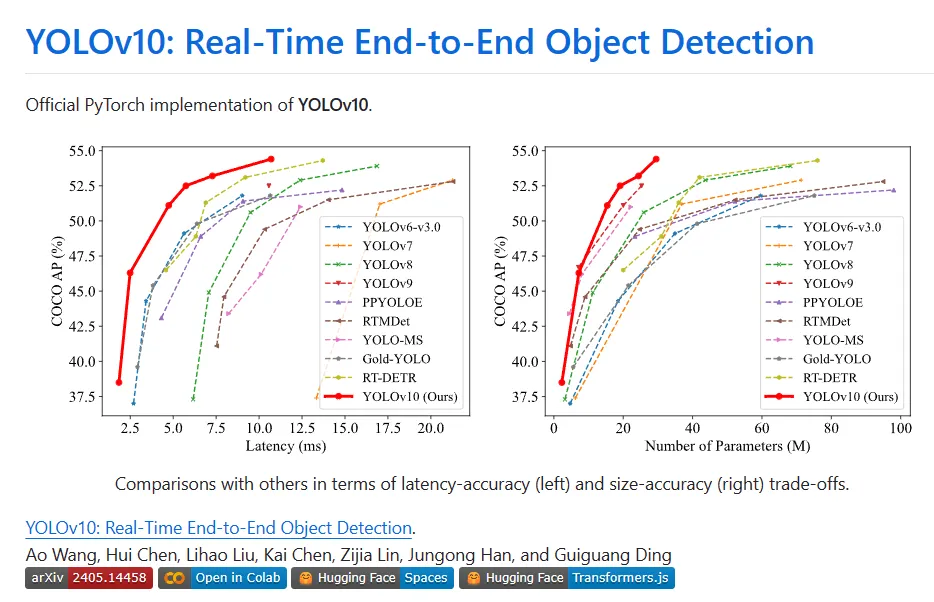
Pengesanan objek masa nyata sentiasa menjadi tempat liputan penyelidikan dalam bidang penglihatan komputer dengan tepat . Ia digunakan secara meluas dalam pelbagai aplikasi praktikal, termasuk pemanduan autonomi, navigasi robot, dan penjejakan objek. Dalam beberapa tahun kebelakangan ini, penyelidik telah memberi tumpuan kepada mereka bentuk pengesan objek berasaskan CNN untuk mencapai pengesanan masa nyata. Pengesan objek masa nyata boleh dibahagikan kepada dua kategori: pengesan satu peringkat dan pengesan dua peringkat. Pengesan satu peringkat membuat ramalan padat secara langsung pada imej input, manakala pengesan dua peringkat mula-mula menjana kotak calon dan kemudian melakukan klasifikasi dan regresi lokasi pada kotak calon ini.
Antaranya, YOLO menjadi semakin popular kerana keseimbangan pintar mereka antara prestasi dan kecekapan. Saluran paip pengesanan YOLO terdiri daripada dua bahagian: pemprosesan hadapan model dan pemprosesan pasca NMS. Walau bagaimanapun, kedua-dua kaedah masih mempunyai kekurangan, menyebabkan ketepatan dan sempadan kependaman yang tidak optimum. Khususnya, YOLO biasanya menggunakan strategi peruntukan label satu-ke-banyak semasa latihan, di mana satu objek pelaksanaan asas sepadan dengan beberapa buku sampel. Walaupun menghasilkan prestasi unggul, pendekatan ini memerlukan NMS untuk memilih ramalan positif terbaik semasa inferens. Ini memperlahankan inferens dan menjadikan prestasi sensitif kepada hiperparameter NMS, menghalang YOLO daripada mencapai penggunaan hujung ke hujung yang optimum. Satu cara untuk menyelesaikan masalah ini ialah dengan menggunakan seni bina DETR hujung ke hujung yang diperkenalkan baru-baru ini. Sebagai contoh, RT-DETR menyediakan pengekod hibrid yang cekap dan pemilihan pertanyaan dengan ketidakpastian yang minimum, mendorong DETR ke dalam aplikasi masa nyata. Walau bagaimanapun, kerumitan yang wujud dalam menggunakan DETR menghalang keupayaannya untuk mencapai keseimbangan optimum antara ketepatan dan kelajuan. Baris lain meneroka pengesanan hujung ke hujung pengesan berasaskan CNN, yang biasanya menggunakan strategi peruntukan satu sama satu untuk menyekat ramalan berlebihan. Walau bagaimanapun, mereka sering memperkenalkan overhed inferens tambahan atau mencapai prestasi yang tidak optimum. Di samping itu, reka bentuk seni bina model kekal sebagai cabaran asas untuk YOLO, yang mempunyai kesan ketara terhadap ketepatan dan kelajuan. Untuk mencapai seni bina model yang lebih cekap dan berkesan, penyelidik telah meneroka strategi reka bentuk yang berbeza. Untuk meningkatkan keupayaan pengekstrakan ciri, pelbagai unit pengkomputeran utama disediakan untuk tulang belakang, termasuk DarkNet, CSPNet, EfficientRep dan ELAN. Untuk leher, PAN, BiC, GD, RepGFPN, dll. diterokai untuk meningkatkan gabungan ciri berbilang skala. Selain itu, strategi penskalaan model dan teknik penskalaan semula disiasat. Walaupun usaha ini telah mencapai kemajuan yang ketara, masih terdapat ruang untuk pemeriksaan menyeluruh terhadap pelbagai komponen dalam YOLO dari perspektif kecekapan dan ketepatan. Oleh itu, keupayaan yang terhasil untuk mengekang model juga membawa kepada prestasi pembezaan, meninggalkan ruang yang cukup untuk peningkatan ketepatan.
3.
Teknologi Baharu
Tugas Dwi Konsisten untuk Latihan Tanpa NMS
Semasa latihan, YOLO biasanya menggunakan TAL untuk menetapkan berbilang sampel positif bagi setiap contoh. Penerimaan peruntukan satu kepada banyak menjana isyarat pemantauan yang kaya yang membantu mengoptimumkan dan mencapai prestasi unggul. Walau bagaimanapun, YOLO mesti bergantung pada pemprosesan pasca NMS, yang mengakibatkan kecekapan inferens penggunaan yang tidak memuaskan. Walaupun kerja-kerja sebelumnya meneroka padanan satu-dengan-satu untuk menyekat ramalan yang berlebihan, kerja-kerja ini sering memperkenalkan overhed inferens tambahan atau menghasilkan prestasi yang tidak optimum. Dalam kerja ini, YOLO menyediakan strategi latihan bebas NMS dengan tugasan dwi-label dan metrik padanan yang konsisten, mencapai kecekapan tinggi dan prestasi kompetitif.
- Penugasan dwi label
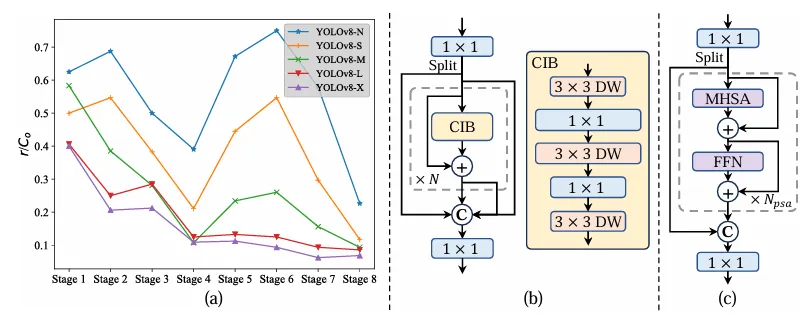
Berbeza dengan tugasan satu-ke-banyak, satu-ke-satu pembetulan pembetulan hanya dengan satu pembetulan MS, satu-dengan-satu padanan kebenaran . Walau bagaimanapun, ia mengakibatkan penyeliaan yang lemah, mengakibatkan ketepatan dan kelajuan penumpuan yang tidak optimum. Nasib baik, kekurangan ini boleh diperbaiki dengan peruntukan satu-ke-banyak. Untuk mencapai matlamat ini, YOLO memperkenalkan peruntukan dwi label untuk menggabungkan yang terbaik daripada kedua-dua strategi. Secara khusus, seperti yang ditunjukkan dalam Rajah (a) di bawah.
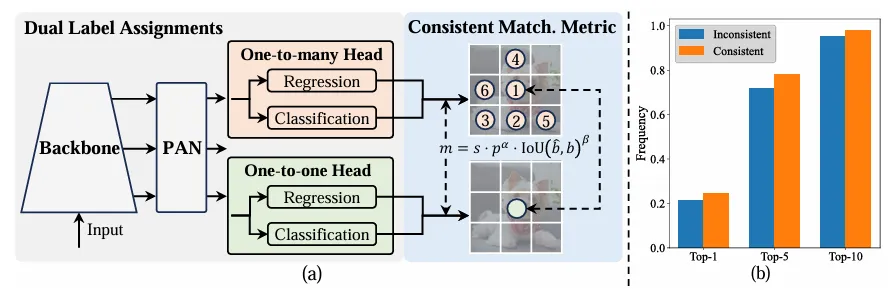
Memperkenalkan satu lagi tajuk satu dengan satu untuk YOLO. Ia mengekalkan struktur yang sama dan menggunakan matlamat pengoptimuman yang sama seperti cawangan satu-ke-banyak yang asal, tetapi menggunakan padanan satu dengan satu untuk mendapatkan tugasan label. Semasa proses latihan, kedua-dua kepala dioptimumkan bersama-sama dengan model, membolehkan tulang belakang dan leher menikmati pengawasan yang kaya yang disediakan oleh satu-ke-banyak tugas. Semasa inferens, pengepala satu-ke-banyak dibuang dan pengepala satu sama satu digunakan untuk ramalan. Ini membolehkan YOLO digunakan dari hujung ke hujung tanpa menanggung sebarang kos inferens tambahan. Tambahan pula, dalam padanan satu dengan satu, pilihan sebelumnya diguna pakai, mencapai prestasi yang sama seperti padanan Hungary dengan masa latihan tambahan yang kurang.
- Metrik pemadanan yang konsisten
Semasa proses peruntukan, kedua-dua kaedah satu-dengan-satu dan satu-dengan-banyak menggunakan metrik untuk menilai secara kuantitatif tahap ramalan dan ketekalan. Untuk mencapai padanan sedar ramalan bagi dua cabang, metrik padanan bersatu digunakan:
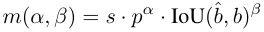
Dalam penugasan dwi-label, cawangan satu-ke-banyak memberikan isyarat pemantauan yang lebih kaya daripada satu-satu cawangan. Secara intuitif, jika penyeliaan pengepala satu dengan satu boleh diselaraskan dengan penyeliaan pengepala satu-ke-banyak, pengepala satu-ke-satu boleh dioptimumkan ke arah pengoptimuman pengepala satu-ke-banyak. Oleh itu, kepala satu sama satu boleh memberikan kualiti sampel yang lebih baik semasa inferens, menghasilkan prestasi yang lebih baik. Untuk tujuan ini, jurang peraturan antara kedua-duanya dianalisis terlebih dahulu. Disebabkan oleh rawak dalam proses latihan, memulakan pemeriksaan dengan dua kepala yang dimulakan dengan nilai yang sama dan menghasilkan ramalan yang sama, iaitu kepala satu dengan satu dan kepala satu kepada banyak menghasilkan yang sama untuk setiap yang diramalkan. pasangan contoh p dan IoU. Perhatikan matlamat regresi untuk kedua-dua cawangan.
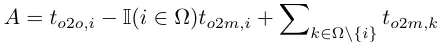
Apabila to2m, i=u*, ia mencapai nilai minimum, iaitu i ialah sampel positif terbaik dalam Ω, seperti yang ditunjukkan dalam (a) di atas. Untuk mencapai matlamat ini, metrik padanan yang konsisten dicadangkan, iaitu αo2o=r·αo2m dan βo2o=r·βo2m, yang bermaksud mo2o=mro2m. Oleh itu, sampel positif terbaik untuk kepala satu-ke-banyak juga merupakan sampel terbaik untuk kepala satu-dengan-satu. Hasilnya, kedua-dua kepala boleh dioptimumkan secara konsisten dan harmoni. Untuk kesederhanaan, r=1 diambil secara lalai, iaitu, αo2o=αo2m dan βo2o=βo2m. Untuk mengesahkan penjajaran seliaan yang dipertingkatkan, bilangan pasangan padanan satu dengan satu dalam 1/5/10 pertama hasil satu-ke-banyak dikira selepas latihan. Seperti yang ditunjukkan dalam (b) di atas, penjajaran diperbaiki di bawah kaedah pemadanan yang konsisten.
Disebabkan ruang yang terhad, inovasi utama YOLOv10 ialah pengenalan strategi peruntukan dwi label. . latihan; dalam peringkat inferens, pemotongan kecerunan digunakan untuk bertukar kepada kepala pengesanan satu-ke-satu Ini menghapuskan keperluan untuk pemprosesan pasca NMS, mengurangkan overhed inferens sambil mengekalkan prestasi. Prinsipnya sebenarnya tidak sukar, anda boleh melihat kod untuk memahami:
#https://github.com/THU-MIG/yolov10/blob/main/ultralytics/nn/modules/head.pyclass v10Detect(Detect):max_det = -1def __init__(self, nc=80, ch=()):super().__init__(nc, ch)c3 = max(ch[0], min(self.nc, 100))# channelsself.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(Conv(x, x, 3, g=x), Conv(x, c3, 1)), \ nn.Sequential(Conv(c3, c3, 3, g=c3), Conv(c3, c3, 1)), \nn.Conv2d(c3, self.nc, 1)) for i, x in enumerate(ch))self.one2one_cv2 = copy.deepcopy(self.cv2)self.one2one_cv3 = copy.deepcopy(self.cv3)def forward(self, x):one2one = self.forward_feat([xi.detach() for xi in x], self.one2one_cv2, self.one2one_cv3)if not self.export:one2many = super().forward(x)if not self.training:one2one = self.inference(one2one)if not self.export:return {'one2many': one2many, 'one2one': one2one}else:assert(self.max_det != -1)boxes, scores, labels = ops.v10postprocess(one2one.permute(0, 2, 1), self.max_det, self.nc)return torch.cat([boxes, scores.unsqueeze(-1), labels.unsqueeze(-1)], dim=-1)else:return {'one2many': one2many, 'one2one': one2one}def bias_init(self):super().bias_init()'''Initialize Detect() biases, WARNING: requires stride availability.'''m = self# self.model[-1]# Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum())# nominal class frequencyfor a, b, s in zip(m.one2one_cv2, m.one2one_cv3, m.stride):# froma[-1].bias.data[:] = 1.0# boxb[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2)# cls (.01 objects, 80 classes, 640 img)Holistic Efficiency-Accuracy Driven Model Design
架构改进:
- Backbone & Neck:使用了先进的结构如 CSPNet 作为骨干网络,和 PAN 作为颈部网络,优化了特征提取和多尺度特征融合。
- 大卷积核与分区自注意力:这些技术用于增强模型从大范围上下文中学习的能力,提高检测准确性而不显著增加计算成本。
- 整体效率:引入空间-通道解耦下采样和基于秩引导的模块设计,减少计算冗余,提高整体模型效率。
四、实验
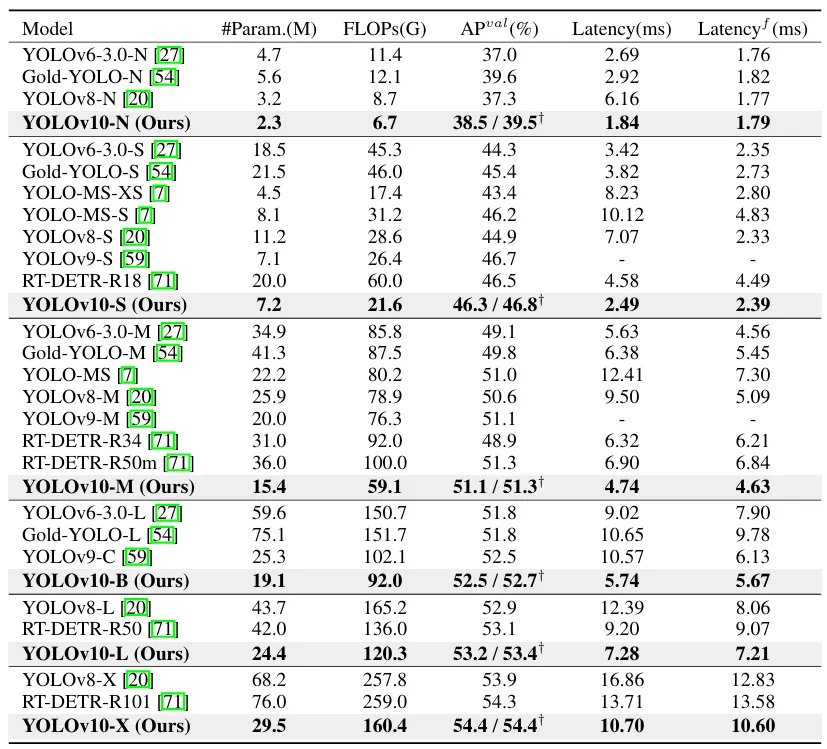
与最先进的比较。潜伏性是通过官方预训练的模型来测量的。潜在的基因测试在具有前处理的模型的前处理中保持了潜在性。†是指YOLOv10的结果,其本身对许多训练NMS来说都是如此。以下是所有结果,无需添加先进的训练技术,如知识提取或PGI或公平比较:

五、部署测试
首先,按照官方主页将环境配置好,注意这里 python 版本至少需要 3.9 及以上,torch 版本可以根据自己本地机器安装合适的版本,默认下载的是 2.0.1:
conda create -n yolov10 pythnotallow=3.9conda activate yolov10pip install -r requirements.txtpip install -e .
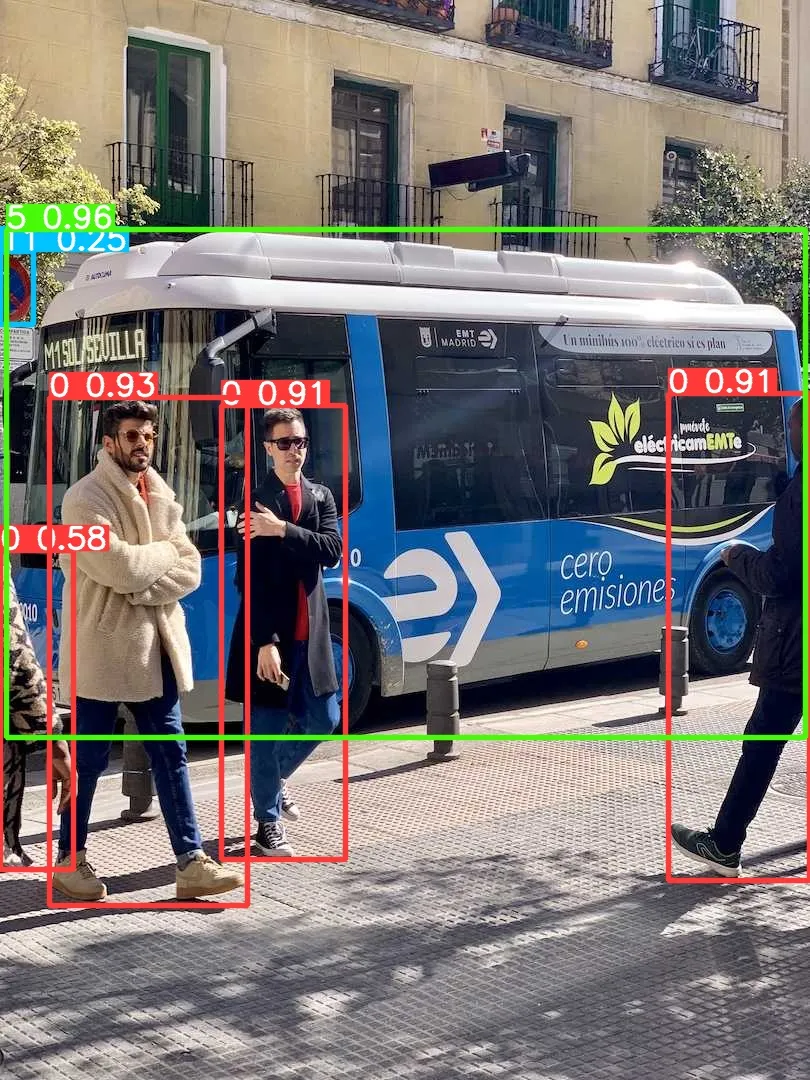
安装完成之后,我们简单执行下推理命令测试下效果:
yolo predict model=yolov10s.pt source=ultralytics/assets/bus.jpg
让我们尝试部署一下,譬如先导出个 onnx 模型出来看看:
yolo export model=yolov10s.pt format=onnx opset=13 simplify
好了,接下来通过执行 pip install netron 安装个可视化工具来看看导出的节点信息:
# run python fisrtimport netronnetron.start('/path/to/yolov10s.onnx')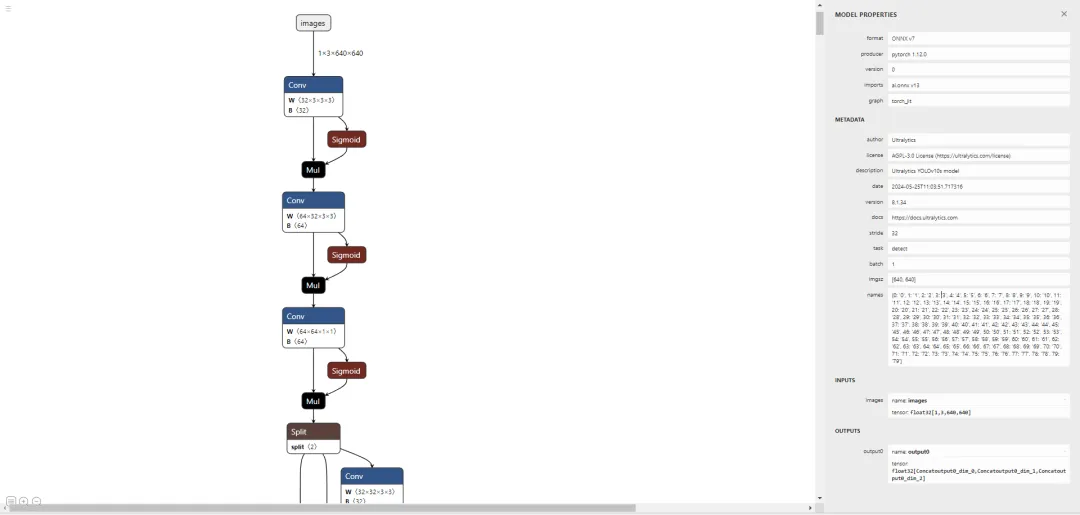
先直接通过 Ultralytics 框架预测一个测试下能否正常推理:
yolo predict model=yolov10s.onnx source=ultralytics/assets/bus.jpg

大家可以对比下上面的运行结果,可以看出 performance 是有些许的下降。问题不大,让我们基于 onnxruntime 写一个简单的推理脚本,代码地址如下,有兴趣的可以自行查看:
# 推理脚本https://github.com/CVHub520/X-AnyLabeling/blob/main/tools/export_yolov10_onnx.py# onnx 模型权重https://github.com/CVHub520/X-AnyLabeling/releases/tag/v2.3.6

Atas ialah kandungan terperinci Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!