
Rumah >Peranti teknologi >AI >Yann LeCun: ViT lambat dan tidak cekap pemprosesan imej masa nyata masih bergantung pada lilitan.
Yann LeCun: ViT lambat dan tidak cekap pemprosesan imej masa nyata masih bergantung pada lilitan.

- WBOYasal
- 2024-06-06 13:25:021090semak imbas
Dalam era penyatuan Transformer, adakah masih perlu untuk mengkaji arah CNN visi komputer?
Pada awal tahun ini, model video besar OpenAI Sora menjadikan seni bina Vision Transformer (ViT) popular. Sejak itu, terdapat perdebatan berterusan tentang siapa yang lebih berkuasa, ViT atau rangkaian neural convolutional tradisional (CNN).
Baru-baru ini, pemenang Anugerah Turing Yann LeCun, ketua saintis Meta, yang aktif di media sosial, turut menyertai perbincangan mengenai pertikaian antara ViT dan CNN.

Punca kejadian ini ialah Harald Schäfer, CTO Comma.ai, sedang mempamerkan penyelidikan terbarunya. Beliau (seperti ramai sarjana AI baru-baru ini) mengisyaratkan ungkapan Yann LeCun bahawa walaupun hartawan Anugerah Turing percaya bahawa ViT tulen tidak praktikal, baru-baru ini kami telah menukar pemampat kami kepada ViT tulen. Tidak ada keuntungan yang cepat dan ia akan mengambil masa yang lebih lama kesannya sangat bagus.
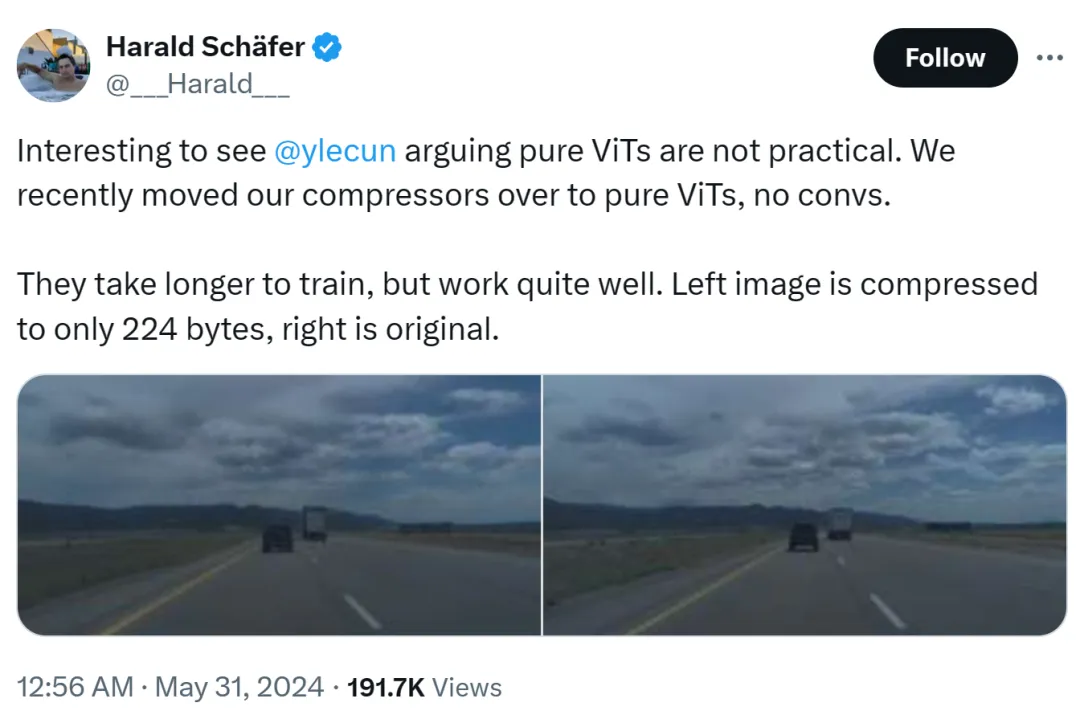
Sebagai contoh, imej di sebelah kiri dimampatkan kepada 224 bait sahaja, dan sebelah kanan ialah imej asal.
hanya 14×128, yang sangat besar untuk model dunia untuk pemanduan autonomi, yang bermaksud bahawa sejumlah besar data boleh menjadi input untuk latihan. Latihan dalam persekitaran maya adalah lebih murah daripada dalam persekitaran sebenar, di mana ejen perlu dilatih mengikut dasar untuk berfungsi dengan baik. Resolusi yang lebih tinggi untuk latihan maya akan berfungsi dengan lebih baik, tetapi simulator akan menjadi sangat perlahan, jadi pemampatan diperlukan pada masa ini.
Demonstrasinya mencetuskan perbincangan dalam kalangan AI, dan Eric Jang, VP Kecerdasan Buatan di 1X, menjawab bahawa hasilnya adalah menakjubkan.
Harald terus memuji ViT: Ini adalah seni bina yang sangat cantik.
Seseorang mula tersinggung di sini: Sarjana seperti LeCun kadangkala gagal untuk bersaing dengan rentak inovasi.
Walau bagaimanapun, Yann LeCun dengan cepat bertindak balas dan berhujah bahawa dia tidak mengatakan bahawa ViT tidak praktikal, dan semua orang menggunakannya sekarang. Apa yang beliau ingin nyatakan ialah ViT terlalu perlahan dan tidak cekap, menjadikannya tidak sesuai untuk pemprosesan masa nyata bagi tugasan imej dan video beresolusi tinggi.
Yann LeCun juga Cue Xie Saining, penolong profesor di Universiti New York, yang kerjanya ConvNext membuktikan bahawa CNN boleh menjadi sebaik ViT jika kaedahnya betul.
Dia seterusnya mengatakan bahawa anda memerlukan sekurang-kurangnya beberapa lapisan konvolusi dengan pengumpulan dan langkah sebelum berpegang pada gelung perhatian diri.
Jika perhatian diri bersamaan dengan pilih atur, ia tidak masuk akal sama sekali untuk pemprosesan imej atau video peringkat rendah, dan juga tidak menampal menggunakan satu langkah di bahagian hadapan. Di samping itu, memandangkan korelasi dalam imej atau video sangat tertumpu secara tempatan, perhatian global tidak bermakna dan tidak boleh skala.
Pada tahap yang lebih tinggi, apabila ciri mewakili objek, masuk akal untuk menggunakan gelung perhatian diri: hubungan dan interaksi antara objek yang penting, bukan lokasinya. Seni bina hibrid ini dipelopori oleh sistem DETR yang disiapkan oleh saintis penyelidikan Meta Nicolas Carion dan pengarang bersama.
Sejak kemunculan kerja DETR, Yann LeCun berkata bahawa seni bina kegemarannya ialah konvolusi/langkah/penggabungan peringkat rendah dan gelung perhatian diri peringkat tinggi.
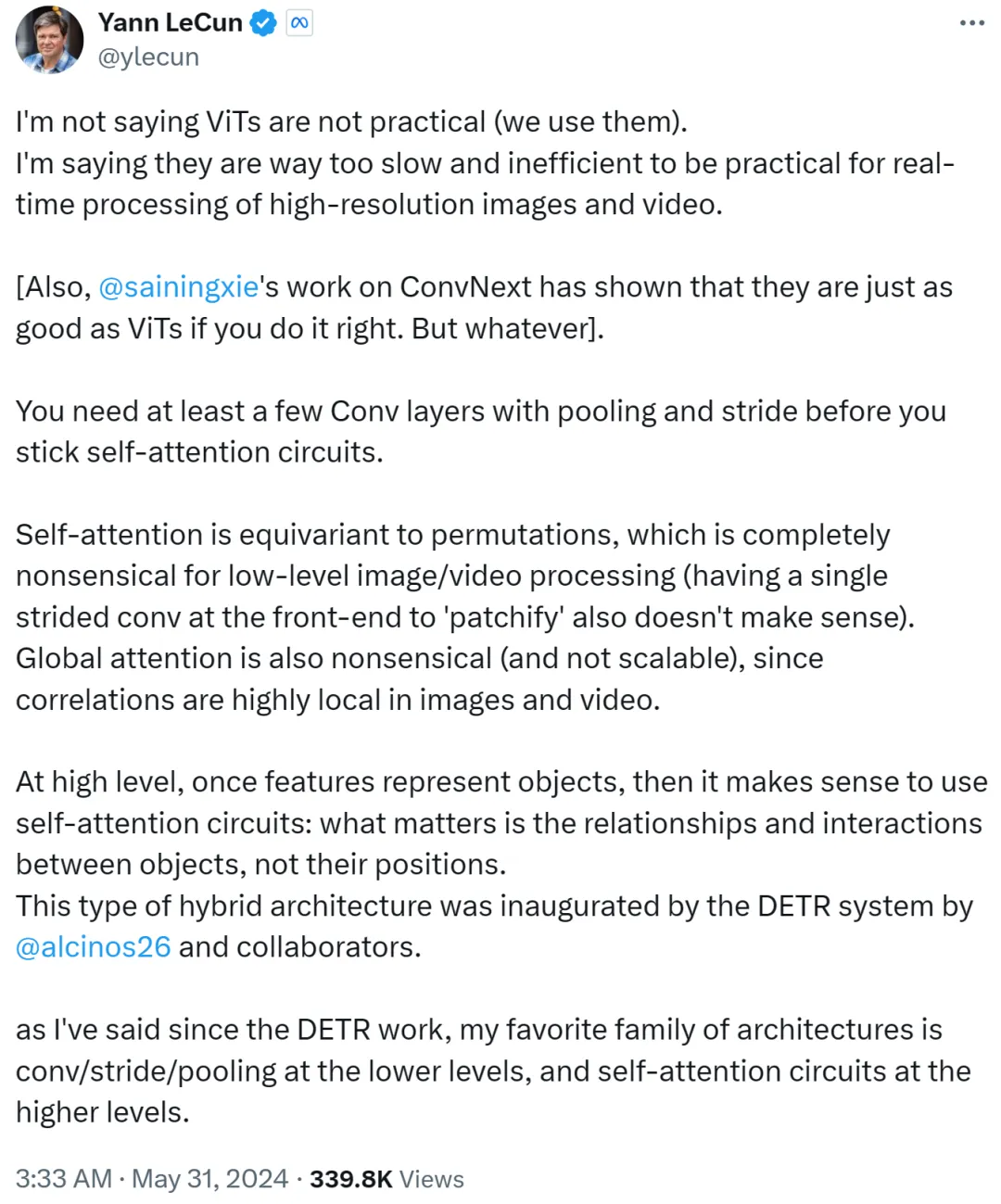
Yann LeCun meringkaskannya dalam catatan kedua: gunakan lilitan dengan langkah atau gabungan pada tahap rendah, gunakan gelung perhatian diri pada tahap tinggi dan gunakan vektor ciri untuk mewakili objek.
Dia juga bertaruh bahawa Tesla Fully Self-Driving (FSD) menggunakan konvolusi (atau operator tempatan yang lebih kompleks) pada tahap rendah, digabungkan dengan lebih banyak gelung global pada tahap yang lebih tinggi (mungkin menggunakan perhatian diri ). Oleh itu, menggunakan Transformers pada benam tampalan peringkat rendah adalah satu pembaziran yang lengkap.
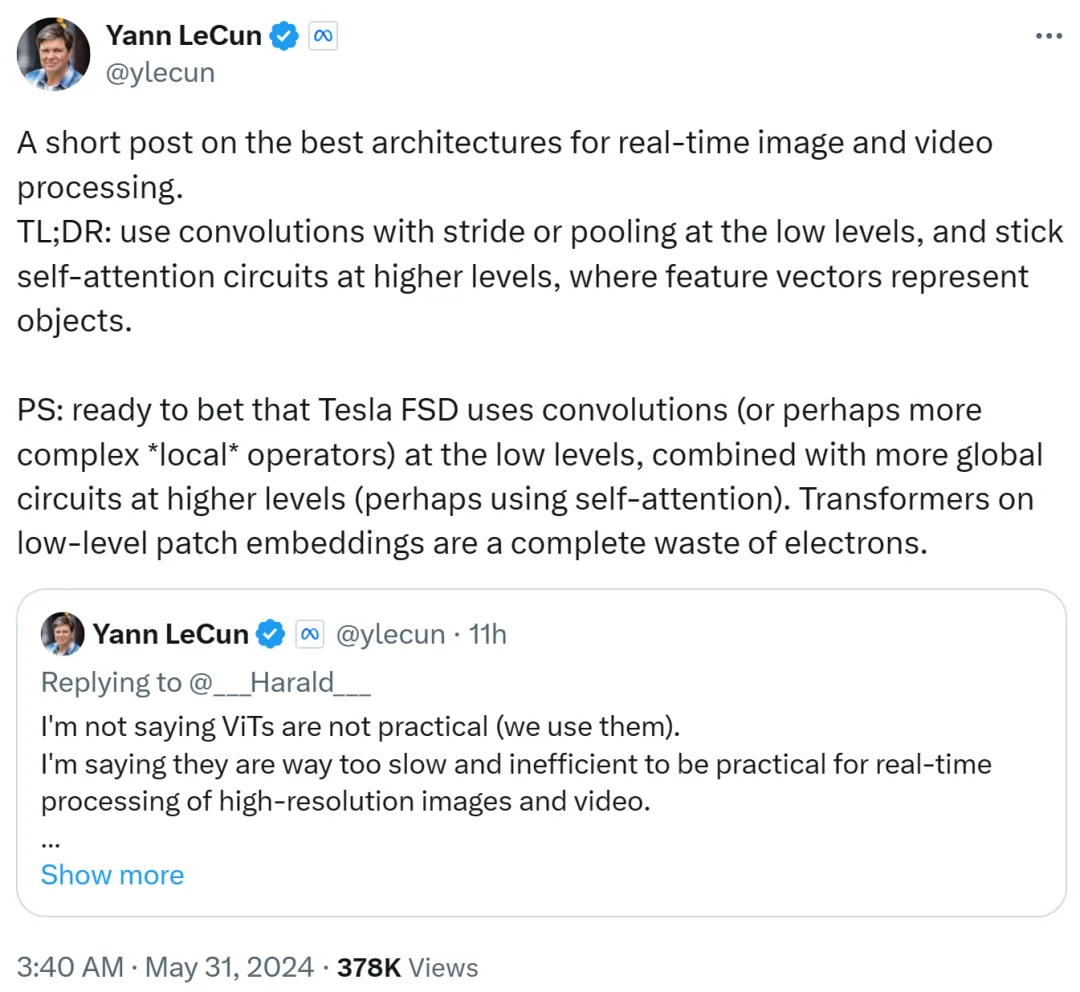
Saya rasa musuh utama Musk masih menggunakan laluan konvolusi.
Xie Senin juga menyatakan pendapatnya Dia percaya ViT sangat sesuai untuk imej resolusi rendah 224x224, tetapi bagaimana jika resolusi imej mencapai 1 juta x 1 juta? Pada masa ini, sama ada konvolusi digunakan, atau ViT ditampal dan diproses menggunakan pemberat bersama, yang masih bersifat konvolusi.
Oleh itu, Xie Senin berkata bahawa pada masa itu dia menyedari bahawa rangkaian konvolusi bukan seni bina, tetapi cara berfikir.
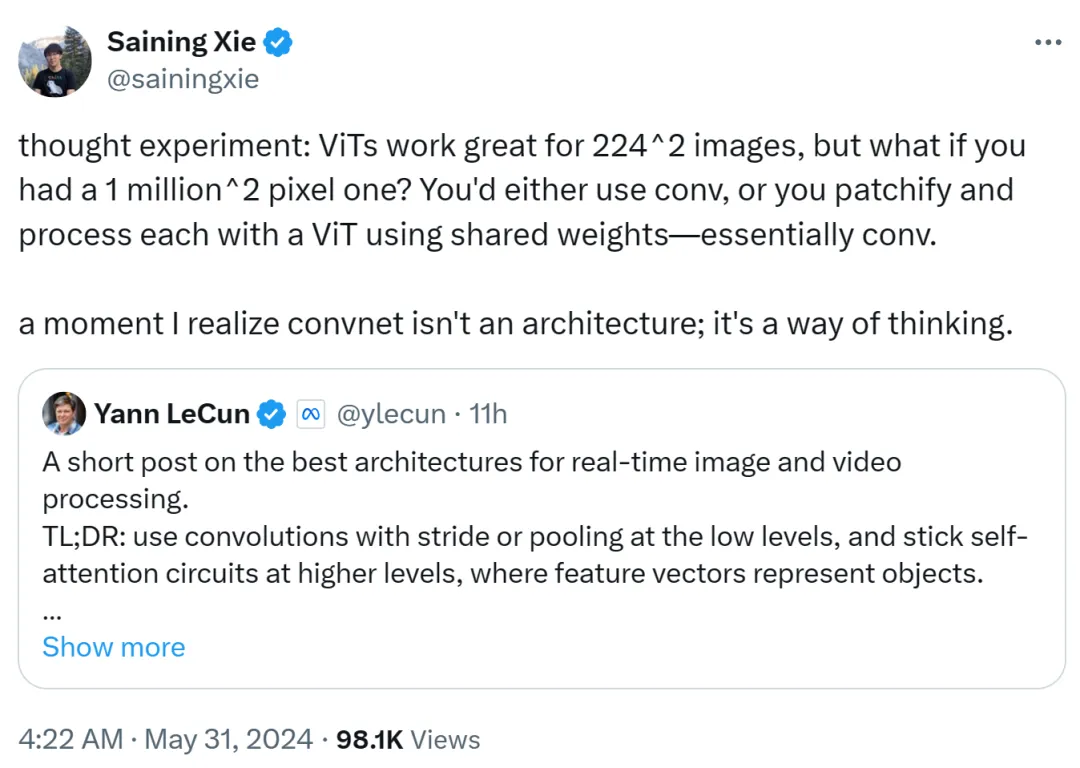
Pandangan ini diiktiraf oleh Yann LeCun.

Penyelidik Google DeepMind Lucas Beyer juga berkata terima kasih kepada pelapisan sifar rangkaian konvolusi konvensional, dia pasti bahawa "konvolusi ViT" (bukan ViT + konvolusi) akan berfungsi dengan baik .
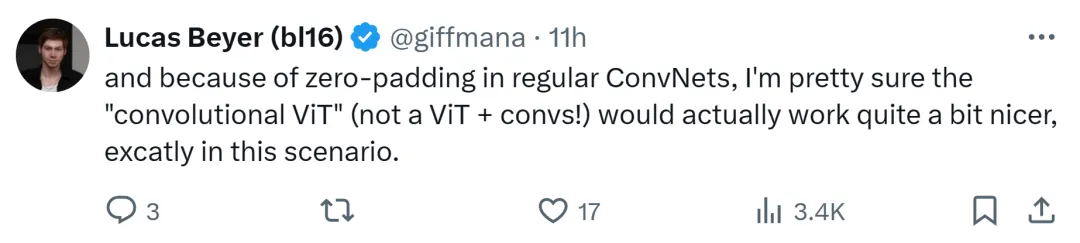
Adalah dijangka bahawa perdebatan antara ViT dan CNN ini akan berterusan sehingga satu lagi seni bina yang lebih berkuasa muncul pada masa hadapan.
Atas ialah kandungan terperinci Yann LeCun: ViT lambat dan tidak cekap pemprosesan imej masa nyata masih bergantung pada lilitan.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!