
Rumah >Peranti teknologi >AI >Penyelidikan baharu NVIDIA: Panjang konteks adalah benar-benar palsu, dan tidak banyak prestasi 32K yang layak
Penyelidikan baharu NVIDIA: Panjang konteks adalah benar-benar palsu, dan tidak banyak prestasi 32K yang layak

- WBOYasal
- 2024-06-05 16:22:471040semak imbas
Mendedahkan fenomena standard palsu model besar "konteks panjang" -
Penyelidikan baharu NVIDIA mendapati 10 model besar, termasuk GPT-4, menjana panjang konteks 128k atau 1M.
Tetapi selepas beberapa ujian, penunjuk baharu "konteks berkesan" telah menyusut dengan serius, dan tidak ramai yang boleh mencapai 32K.
Tanda aras baharu dipanggil RULER, yang merangkumi pendapatan semula, penjejakan berbilang hop, pengagregatan dan soal jawab 4 kategori dengan jumlah 13 tugasan. RULER mentakrifkan "panjang konteks berkesan", iaitu panjang maksimum model boleh mengekalkan prestasi yang sama seperti garis dasar Llama-7B pada panjang 4K.

Kajian ini dinilai sebagai "sangat berwawasan" oleh ahli akademik.

Selepas melihat penyelidikan baharu ini, ramai netizen juga ingin melihat hasil cabaran pemain raja konteks panjang Claude dan Gemini. (Tidak diliputi dalam kertas)


Mari kita lihat bagaimana NVIDIA mentakrifkan penunjuk "konteks berkesan".

Terdapat lebih banyak tugas ujian yang sukar
Untuk menilai keupayaan pemahaman teks panjang model besar, anda mesti terlebih dahulu memilih standard yang baik, seperti ZeroSCROLLS, L-Eval, LongBench, InfiniteBench, dll. yang popular dalam kalangan, atau hanya menilai Keupayaan mendapatkan model sama ada dihadkan oleh gangguan pengetahuan sedia ada.
Jadi kaedah RULER yang dihapuskan oleh NVIDIA boleh diringkaskan dalam satu ayat sebagai "Pastikan penilaian memberi tumpuan kepada keupayaan model untuk memproses dan memahami konteks yang panjang, dan bukannya keupayaan untuk mengingat maklumat daripada data latihan" .
Data penilaian RULER mengurangkan pergantungan pada "pengetahuan berparameter", iaitu pengetahuan yang model besar telah dikodkan ke dalam parameternya sendiri semasa proses latihan.
Secara khusus, penanda aras RULER memanjangkan ujian popular "jarum dalam timbunan jerami" dengan menambah empat kategori tugasan baharu.
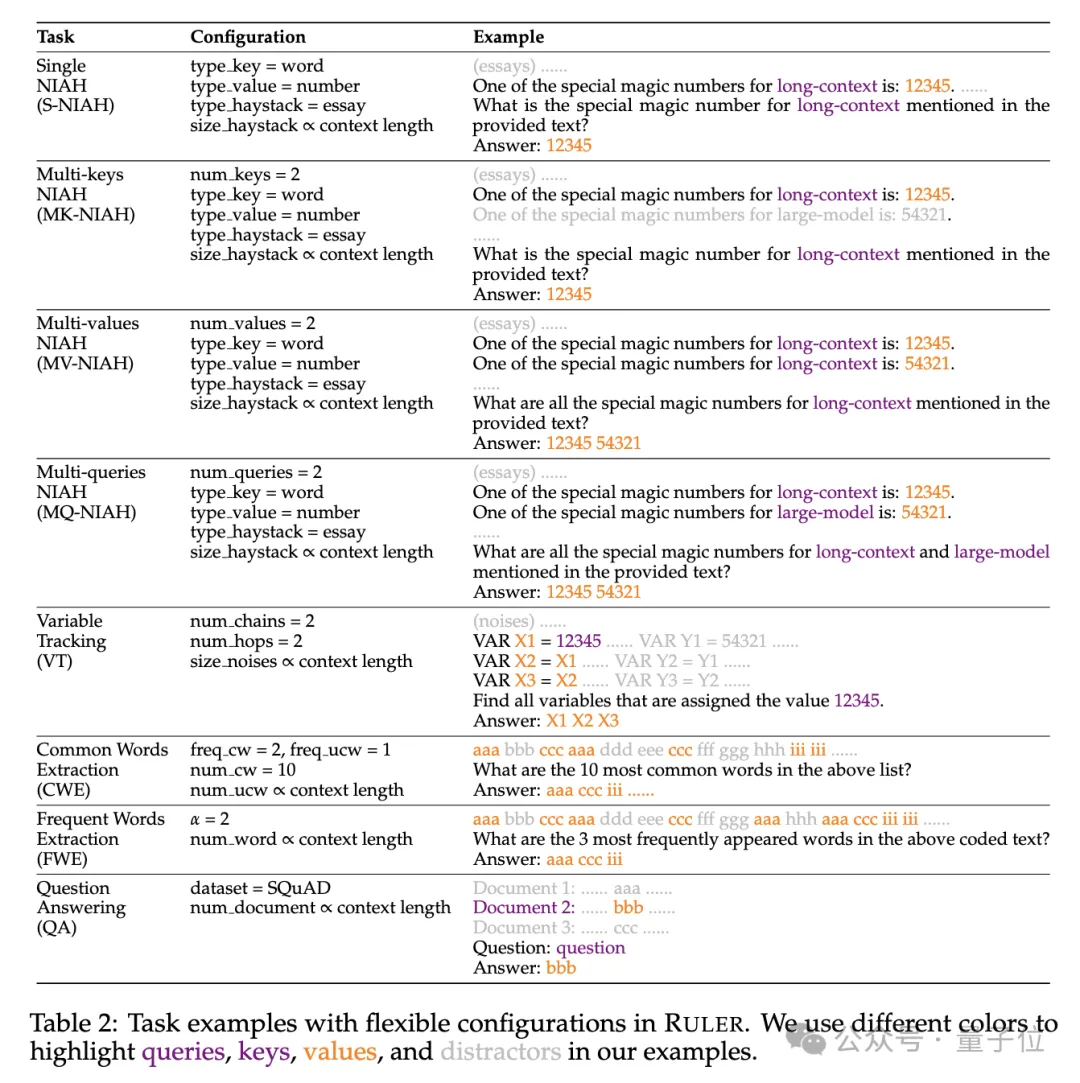
Dari segi pengambilan semula, bermula dari tugas pengambilan jarum tunggal standard untuk mencari jarum dalam timbunan jerami, jenis baharu berikut telah ditambah:
- Pengambilan berbilang kunci -kunci NIAH, MK-NIAH): Masukkan berbilang pin gangguan ke dalam konteks, dan model perlu mendapatkan semula yang ditentukan
- Pendapatan berbilang nilai (Berbilang nilai NIAH, MV-NIAH) : Kunci(kunci) sepadan dengan berbilang nilai (nilai), model perlu mendapatkan semula semua nilai yang dikaitkan dengan kunci tertentu.
- Pendapatan berbilang pertanyaan (Berbilang pertanyaan NIAH, MQ-NIAH): Model perlu mendapatkan berbilang jarum sepadan dalam teks berdasarkan berbilang pertanyaan.
Sebagai tambahan kepada versi pencarian semula yang dinaik taraf, RULER juga menambah Surian Berbilang Hop(Surian Berbilang Hop)cabaran.
Secara khusus, penyelidik mencadangkanPenjejakan Pembolehubah(VT), yang mensimulasikan tugas minimum resolusi rujukan, yang memerlukan model untuk menjejak rantai tugasan pembolehubah dalam teks, walaupun tugasan ini dalam teks adalah tidak berterusan. Tahap ketiga cabaran ialah
Pengagregatan(Penggabungan), termasuk:
- Pengestrakan Kata Biasa
- (CWE): Model memerlukan perkataan dari teks yang paling biasa Frequent Words Extraction
- (Frequent Words Extraction, FWE): Sama seperti CWE, tetapi kekerapan sesuatu perkataan ditentukan berdasarkan kedudukannya dalam perbendaharaan kata dan parameter taburan Zeta α.
Tahap keempat cabaran ialah Tugas Soal Jawab (QA) Berdasarkan set data pemahaman bacaan sedia ada (seperti SQuAD), sejumlah besar perenggan gangguan dimasukkan untuk menguji urutan yang panjang. keupayaan QA.
Berapa lama sebenarnya setiap konteks model?
Dalam fasa percubaan, seperti yang dinyatakan pada mulanya, penyelidik menilai 10 model bahasa yang mendakwa menyokong konteks panjang, termasuk GPT-4, dan 9 model sumber terbuka Command-R, Yi-34B, Mixtral (8x7B), Mixtral ( 7B), ChatGLM, LWM, Bersama-sama, LongChat, LongAlpaca.
Saiz parameter model ini berjulat daripada 6B hingga 8x7B dengan seni bina MoE dan julat panjang konteks maksimum dari 32K hingga 1M.
Dalam ujian penanda aras RULER, setiap model dinilai pada 13 tugasan berbeza, meliputi 4 kategori tugasan, daripada kesukaran yang mudah kepada yang kompleks. Untuk setiap tugasan, 500 sampel ujian dijana, dengan panjang input antara 4K hingga 128K dalam 6 tahap (4K, 8K, 16K, 32K, 64K, 128K).
 Untuk mengelakkan model enggan menjawab soalan, input dilampirkan dengan awalan jawapan dan kehadiran output sasaran disemak berdasarkan ketepatan berdasarkan ingatan semula.
Untuk mengelakkan model enggan menjawab soalan, input dilampirkan dengan awalan jawapan dan kehadiran output sasaran disemak berdasarkan ketepatan berdasarkan ingatan semula.
 Para penyelidik juga mentakrifkan metrik "panjang konteks yang berkesan", iaitu model boleh mengekalkan tahap prestasi yang sama seperti garis dasar Llama-7B pada panjang 4K pada panjang ini.
Para penyelidik juga mentakrifkan metrik "panjang konteks yang berkesan", iaitu model boleh mengekalkan tahap prestasi yang sama seperti garis dasar Llama-7B pada panjang 4K pada panjang ini.
Untuk perbandingan model yang lebih terperinci, skor purata wajaran
(Purata Wajaran, wAvg)digunakan sebagai penunjuk komprehensif untuk melaksanakan purata wajaran prestasi pada panjang yang berbeza. Dua skim pemberat diterima pakai:
wAvg(inc): Berat meningkat secara linear dengan panjang, mensimulasikan senario aplikasi yang didominasi oleh jujukan panjang- wAvg(dec): Berat berkurangan secara linear dengan panjang, mensimulasikan terutamanya adegan jujukan pendek
- untuk melihat hasilnya.
Tiada perbezaan yang dapat dilihat dalam ujian pengambilan jarum biasa dalam timbunan jerami dan kata laluan, dengan hampir semua model mencapai skor sempurna dalam julat panjang konteks yang dituntut.
Dengan RULER, walaupun banyak model mendakwa boleh mengendalikan konteks token 32K atau lebih lama, tiada model kecuali Mixtral mengekalkan prestasi melebihi garis dasar Llama2-7B pada panjang yang didakwa.
 Keputusan lain adalah seperti berikut Secara keseluruhan, GPT-4 menunjukkan prestasi terbaik pada panjang 4K dan menunjukkan penurunan prestasi yang minimum
Keputusan lain adalah seperti berikut Secara keseluruhan, GPT-4 menunjukkan prestasi terbaik pada panjang 4K dan menunjukkan penurunan prestasi yang minimum
apabila konteks dilanjutkan kepada 128K. Tiga model sumber terbuka teratas ialah Command-R, Yi-34B dan Mixtral, yang semuanya menggunakan RoPE frekuensi asas yang lebih besar dan mempunyai lebih banyak parameter berbanding model lain.
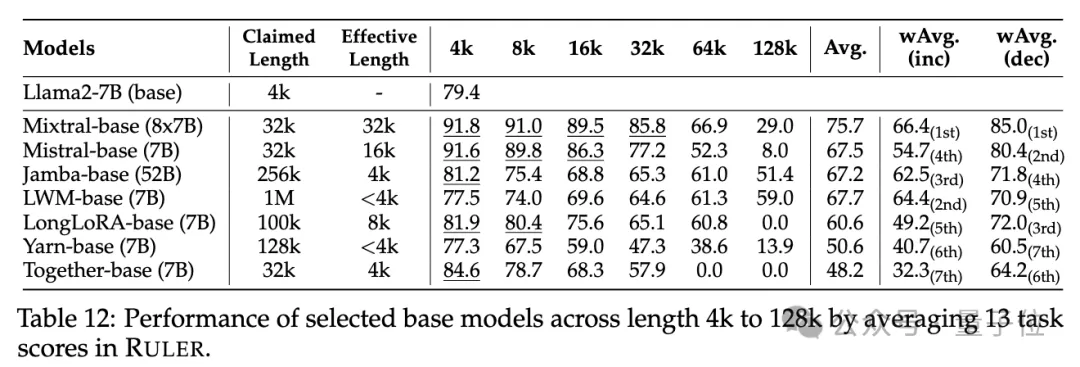
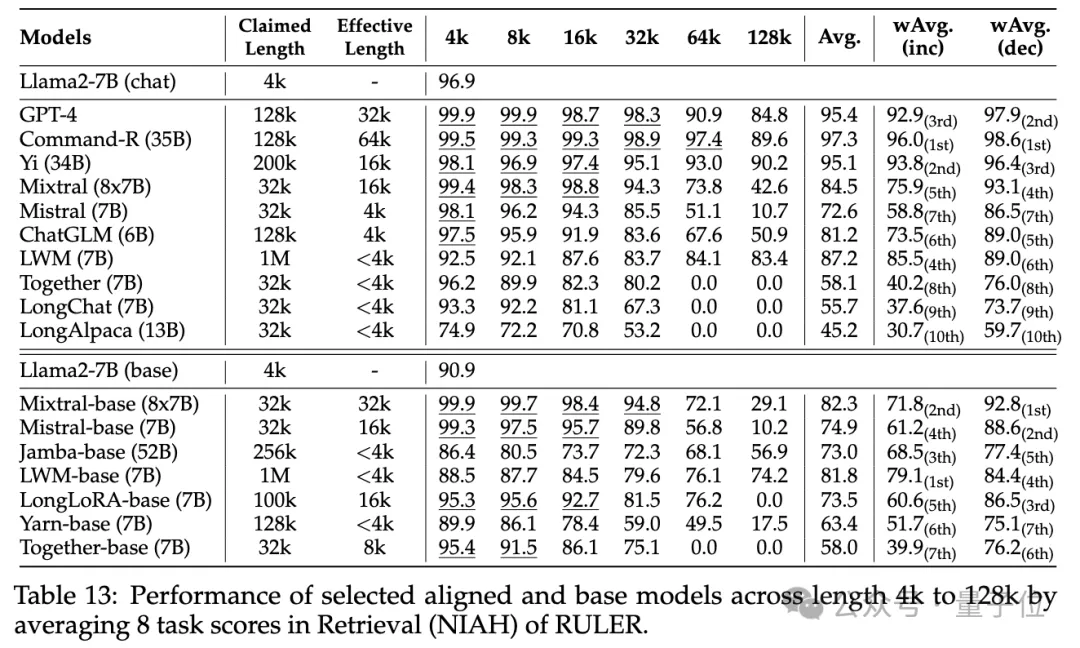

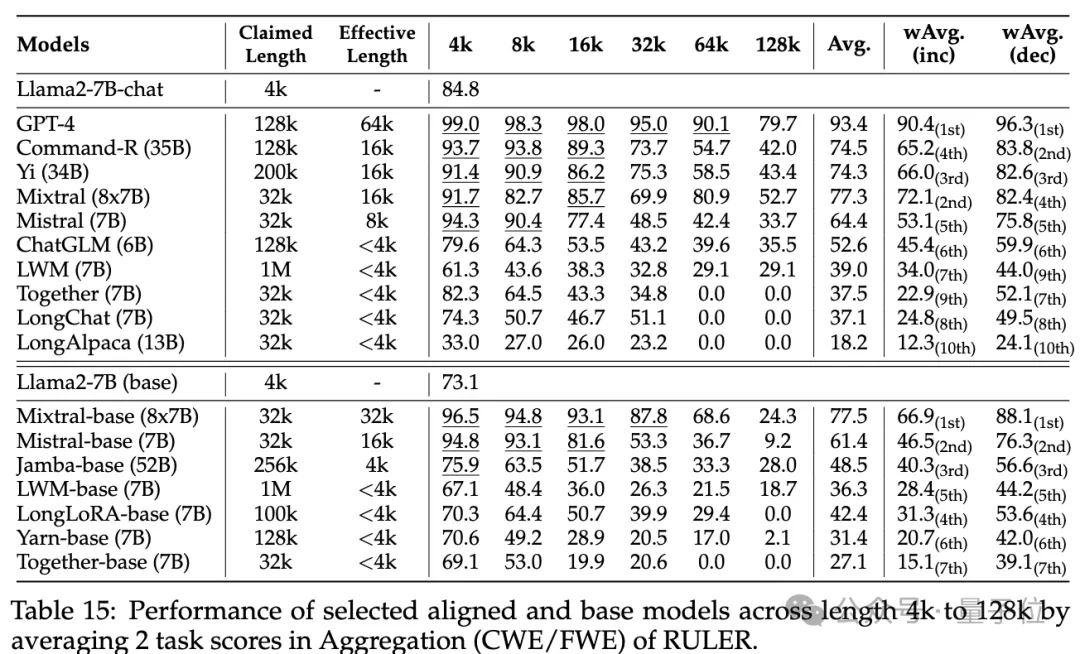
 Selain itu, penyelidik menjalankan analisis mendalam tentang prestasi model Yi-34B-200K pada peningkatan panjang input
Selain itu, penyelidik menjalankan analisis mendalam tentang prestasi model Yi-34B-200K pada peningkatan panjang input
Mereka juga menganalisis kesan panjang konteks latihan, saiz model dan seni bina ke atas prestasi model dan mendapati latihan dengan konteks
yang lebih besar secara amnya membawa kepada prestasi yang lebih baik, tetapi kedudukan urutan yang panjang mungkin tidak konsisten. Terdapat faedah yang ketara untuk memodelkan konteks panjang; seni bina bukan Transformer(seperti RWKV dan Mamba) jauh ketinggalan berbanding Llama2-7B berasaskan Transformer pada RULER. Untuk butiran lanjut, pembaca yang berminat boleh menyemak kertas asal.
Pautan kertas: https://arxiv.org/abs/2404.06654
Atas ialah kandungan terperinci Penyelidikan baharu NVIDIA: Panjang konteks adalah benar-benar palsu, dan tidak banyak prestasi 32K yang layak. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!