Lajur AIxiv ialah lajur di mana kandungan akademik dan teknikal diterbitkan di laman web ini. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Dalam proses latihan model bahasa besar, cara pemprosesan data adalah penting. Kaedah tradisional biasanya menggabungkan dan membahagikan sejumlah besar dokumen ke dalam urutan latihan yang sama dengan panjang konteks model. Walaupun ini meningkatkan kecekapan latihan, ia sering membawa kepada pemangkasan dokumen yang tidak perlu, merosakkan integriti data, dan membawa kepada kehilangan maklumat kontekstual utama, yang seterusnya menjejaskan kesepaduan logik dan konsistensi fakta kandungan yang dipelajari oleh model, dan menjadikan model lebih mudah kepada Halusinasi. Penyelidik di AWS AI Labs menjalankan penyelidikan mendalam tentang kaedah pemprosesan teks penyambungan-pecahan biasa ini dan mendapati ia menjejaskan keupayaan model untuk memahami koheren kontekstual dan ketekalan fakta. Ini bukan sahaja menjejaskan prestasi model pada tugas hiliran, tetapi juga meningkatkan risiko halusinasi. Sebagai tindak balas kepada masalah ini, mereka mencadangkan strategi pemprosesan dokumen yang inovatif - Pembungkusan Paling Sesuai (Pembungkusan Terbaik), yang menghapuskan pemotongan teks yang tidak perlu dengan mengoptimumkan gabungan dokumen dan meningkatkan dengan ketara Meningkatkan prestasi model dan mengurangkan ilusi model. Penyelidikan ini telah diterima ke dalam ICML 2024. 
Tajuk artikel: Kurang Pemangkasan Meningkatkan Pemodelan BahasaPautan kertas: https://arxiv.org/pdf/2404.10830 Latar belakang penyelidikan
Dalam bahasa besar tradisional Dalam kaedah latihan model, untuk meningkatkan kecekapan, penyelidik biasanya menggabungkan beberapa dokumen input bersama-sama, dan kemudian membahagikan dokumen yang disambung ini ke dalam urutan panjang tetap.
Walaupun kaedah ini mudah dan cekap, ia akan menyebabkan masalah besar - pemotongan dokumen, yang merosakkan integriti data. Pemangkasan dokumen mengakibatkan kehilangan maklumat yang terkandung dalam dokumen.
Di samping itu, pemotongan dokumen mengurangkan jumlah konteks dalam setiap jujukan, yang mungkin menyebabkan ramalan perkataan seterusnya menjadi tidak relevan dengan perkataan sebelumnya, menjadikan model lebih terdedah kepada halusinasi. . akan diperkenalkan dalam urutan latihan, menyebabkan beberapa pembolehubah tidak dapat ditentukan dalam urutan latihan berikutnya, menyebabkan model mempelajari corak yang salah dan mungkin mewujudkan halusinasi dalam tugas hiliran. Contohnya, dalam tugas sintesis program, model boleh menggunakan pembolehubah secara langsung tanpa mentakrifkannya. Rajah 2(b): Pemangkasan juga merosakkan integriti maklumat. Contohnya, "Pagi Isnin" dalam ringkasan tidak boleh sepadan dengan mana-mana konteks dalam urutan latihan, menyebabkan kandungan tidak tepat. Maklumat yang tidak lengkap seperti ini akan mengurangkan sensitiviti model kepada maklumat kontekstual dengan ketara, menyebabkan kandungan yang dijana tidak konsisten dengan keadaan sebenar, iaitu generasi yang tidak setia.
Rajah 2(c): Pemotongan juga menghalang pemerolehan pengetahuan semasa latihan, kerana perwakilan pengetahuan dalam teks sering bergantung pada ayat atau perenggan yang lengkap. Sebagai contoh, model tidak boleh mempelajari lokasi persidangan ICML kerana nama dan lokasi persidangan diedarkan dalam urutan latihan yang berbeza.
- Rajah 2. Contoh pemotongan dokumen yang membawa kepada ilusi atau kehilangan pengetahuan.
(a) Takrif pembolehubah (bahagian biru) dipotong dan panggilan penggunaan seterusnya menghasilkan nama yang tidak ditentukan (bahagian merah).
(b) Maklumat kontekstual utama dipotong (bahagian biru), menjadikan ringkasan kurang tepat daripada teks asal (bahagian merah).
(c) Disebabkan pemotongan, model tidak tahu di mana ICML 2024 akan diadakan.
Pembungkusan Paling SesuaiSebagai tindak balas kepada masalah ini, penyelidik mencadangkan Pembungkusan Terbaik. Kaedah ini menggunakan teknik pengoptimuman gabungan sedar panjang untuk membungkus dokumen dengan cekap ke dalam urutan latihan, menghapuskan sepenuhnya pemangkasan yang tidak perlu. Ini bukan sahaja mengekalkan kecekapan latihan kaedah tradisional, tetapi juga meningkatkan kualiti latihan model dengan ketara dengan mengurangkan pemecahan data. Pengarang membahagikan setiap teks kepada satu atau lebih urutan yang paling banyak panjang konteks model L. Had langkah ini datang dari model, jadi ia mesti dijalankan. Kini, berdasarkan sebilangan besar blok fail dengan panjang paling banyak L, penyelidik berharap dapat menggabungkannya secara munasabah dan memperoleh urutan latihan sesedikit mungkin. Masalah ini boleh dilihat sebagai masalah Pembungkusan Bin. Masalah pengoptimuman pemasangan adalah NP-hard. Seperti yang ditunjukkan dalam algoritma di bawah, di sini mereka menggunakan strategi heuristik Best-Fit-Decreasing (BFD). Seterusnya, kita akan membincangkan kebolehlaksanaan BFD dari sudut kerumitan masa (Time Complexity) dan kekompleksan (Compactness). 
Kerumitan masa untuk pengisihan dan pembungkusan BFD ialah O(N log N), dengan N ialah bilangan blok dokumen. Dalam pemprosesan data pra-latihan, memandangkan panjang blok dokumen ialah integer dan terhad ([1, L]), isihan kiraan boleh digunakan untuk mengurangkan kerumitan masa pengisihan kepada O(N). Dalam fasa pembungkusan, dengan menggunakan struktur data pokok segmen, setiap operasi mencari bekas yang paling sesuai hanya mengambil masa logaritma, iaitu O (log L). Dan kerana L < Dokumentasi) hanya mengambil masa 3 jam. 
Kekompakan adalah satu lagi penunjuk penting untuk mengukur kesan algoritma pembungkusan Tanpa memusnahkan integriti dokumen asal, adalah perlu untuk mengurangkan bilangan urutan latihan mungkin untuk meningkatkan kecekapan latihan model. Dalam aplikasi praktikal, dengan mengawal pengisian dan susunan jujukan dengan tepat, pembungkusan yang paling sesuai boleh menjana bilangan jujukan latihan yang hampir sama seperti kaedah tradisional, sambil mengurangkan kehilangan data dengan ketara akibat pemotongan. 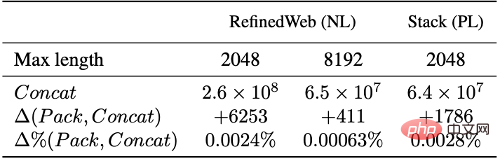
Berdasarkan eksperimen pada set data bahasa semula jadi (RefinedWeb) dan bahasa pengaturcaraan (The Stack), kami mendapati bahawa pembungkusan paling sesuai dengan ketara mengurangkan pemotongan teks. Perlu diperhatikan bahawa kebanyakan dokumen mengandungi kurang daripada 2048 token kerana penyambungan tradisional dan pemotongan berlaku terutamanya dalam julat ini, manakala pembungkusan muat optimum tidak akan memotong mana-mana Dokumen yang panjangnya kurang daripada L, dengan itu mengekalkan dengan berkesan integriti kebanyakan dokumen. 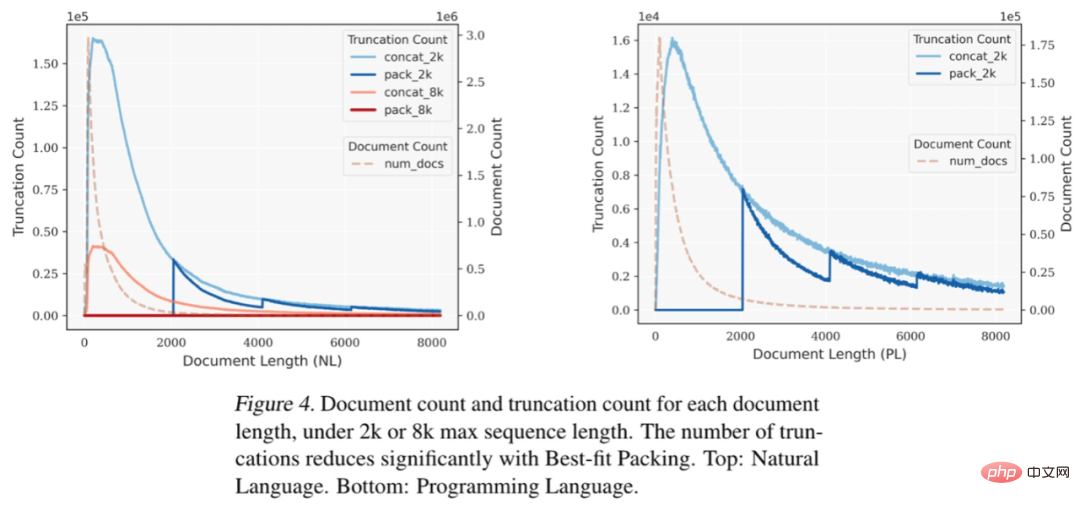
Rajah 4: Apabila panjang jujukan maksimum ditetapkan kepada 2k atau 8k, di bawah panjang dokumen yang berbeza, bilangan dokumen dan bilangan pemotongan sepadan dengan setiap panjang dokumen. Selepas menggunakan teknologi "Pembungkusan Paling Sesuai", bilangan pemotongan berkurangan dengan ketara. Atas: Bahasa semula jadi. Di bawah: Bahasa pengaturcaraan. Para penyelidik melaporkan secara terperinci perbandingan prestasi model bahasa yang dilatih menggunakan pembungkusan paling sesuai dan kaedah splicing yang berbeza (i.elu. pemprosesan bahasa semula jadi dan tugas bahasa pengaturcaraan, seperti pemahaman membaca (Pemahaman Membaca), inferens bahasa semula jadi (Inferens Bahasa Asli), mengikut konteks (Konteks Mengikuti), ringkasan teks (Ringkasan), pengetahuan dunia (Commonsense and Closed-book QA) dan Sintesis Program, sejumlah 22 subtugas. Percubaan melibatkan saiz model antara 7 bilion hingga 13 bilion parameter, panjang jujukan dari 2,000 hingga 8,000 token, dan set data yang meliputi bahasa semula jadi dan bahasa pengaturcaraan. Model ini dilatih pada set data berskala besar seperti Falcon RefinedWeb dan The Stack, dan eksperimen dijalankan menggunakan seni bina LLaMA. 
Hasil eksperimen menunjukkan bahawa menggunakan pembungkusan penyesuaian optimum meningkatkan prestasi model dalam satu siri tugasan, terutamanya dalam pemahaman bacaan (+4.7%), penaakulan bahasa semula jadi (+9.3%) dan mengikut konteks (+ 16.8%) dan sintesis program (+15.0%) dan tugasan lain (disebabkan oleh skala metrik yang berbeza untuk tugasan yang berbeza, pengarang lalai menggunakan peningkatan relatif untuk menerangkan keputusan.) Selepas ujian statistik, penyelidik mendapati Semua keputusan adalah sama ada secara statistik lebih baik daripada garis dasar (ditandakan sebagai s) atau setanding dengan garis dasar (ditandakan sebagai n), dan tiada kemerosotan prestasi yang ketara diperhatikan menggunakan pembungkusan paling sesuai dalam semua tugasan yang dinilai. Peningkatan konsisten dan monotoni ini menyerlahkan bahawa pembungkusan penyesuaian optimum bukan sahaja dapat meningkatkan prestasi keseluruhan model, tetapi juga memastikan kestabilan di bawah tugas dan keadaan yang berbeza. Sila rujuk teks untuk keputusan terperinci dan perbincangan. 
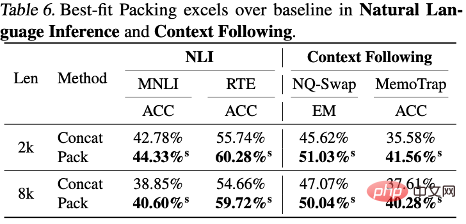

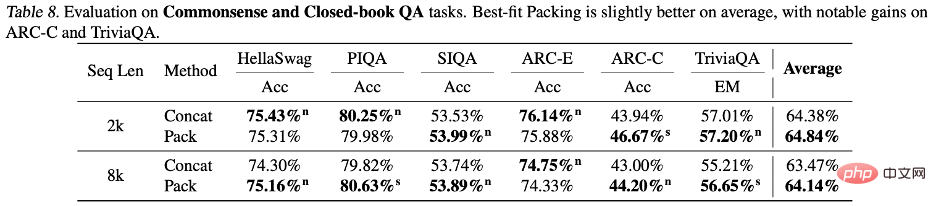

Pengarang memberi tumpuan kepada mengkaji kesan pembungkusan yang paling sesuai terhadap halusinasi. Dalam penjanaan ringkasan, menggunakan metrik QAFactEval didapati bahawa model dengan pembungkusan yang paling sesuai mempunyai secara ketara lebih rendah dalam menjana halusinasi. Lebih ketara lagi, dalam tugasan sintesis program, ralat "Nama Tidak Ditakrifkan" telah dikurangkan sehingga 58.3% apabila menjana kod menggunakan model terlatih berpakej yang paling sesuai, yang menunjukkan Model mempunyai pemahaman yang lebih lengkap tentang struktur program dan logik, dengan itu berkesan mengurangkan halusinasi. Pengarang juga mendedahkan perbezaan dalam prestasi model apabila berhadapan dengan pelbagai jenis pengetahuan. Seperti yang dinyatakan sebelum ini, pemangkasan semasa latihan boleh menjejaskan integriti maklumat, sekali gus menghalang pemerolehan pengetahuan. Tetapi soalan dalam kebanyakan set penilaian standard memberi tumpuan kepada pengetahuan umum, yang sering berlaku dalam bahasa manusia. Jadi walaupun beberapa pengetahuan hilang akibat pemotongan, model masih mempunyai peluang yang baik untuk mempelajari maklumat ini daripada serpihan dokumen. pengetahuan ekor lebih terdedah kepada pemotongan, kerana kekerapan jenis maklumat ini muncul dalam data latihan itu sendiri adalah rendah, dan sukar bagi model untuk menambah kehilangan dari sumber lain pengetahuan.
Dengan menganalisis keputusan dua set ujian ARC-C dan ARC-E, para penyelidik mendapati bahawa berbanding ARC-E, yang mengandungi lebih banyak pengetahuan umum, menggunakan pembungkusan penyesuaian optimum akan menjadikan model lebih baik dalam mengandungi Terdapat peningkatan prestasi yang lebih ketara dalam ARC-C dengan lebih banyak pengetahuan ekor.
Penemuan ini disahkan lagi dengan mengira bilangan kejadian bersama bagi setiap pasangan soalan-jawapan dalam peta entiti Wikipedia yang diproses oleh Kandpal et al (2023). Keputusan statistik menunjukkan bahawa set cabaran (ARC-C) mengandungi pasangan yang jarang berlaku bersama, yang mengesahkan hipotesis bahawa pembungkusan penyesuaian optimum boleh menyokong pembelajaran pengetahuan ekor secara berkesan, dan juga menerangkan sebab model bahasa besar tradisional tidak dapat mempelajari ekor panjang. pengetahuan. 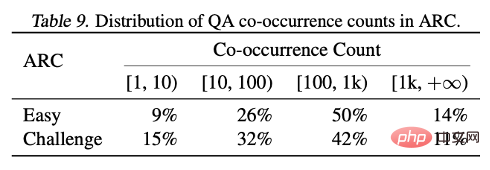
Ringkasan
Artikel ini menimbulkan masalah pemangkasan dokumen biasa dalam latihan model bahasa besar.
Kesan pemotongan ini menjejaskan keupayaan model untuk mempelajari keselarasan logik dan ketekalan fakta, dan meningkatkan fenomena halusinasi semasa proses penjanaan. Penulis mencadangkan Pembungkusan Paling Sesuai, yang memaksimumkan integriti setiap dokumen dengan mengoptimumkan proses pengisihan data. Kaedah ini bukan sahaja sesuai untuk memproses set data berskala besar dengan berbilion dokumen, tetapi juga setanding dengan kaedah tradisional dari segi kekompakan data.
Hasil eksperimen menunjukkan bahawa kaedah ini amat berkesan dalam mengurangkan pemangkasan yang tidak perlu, boleh meningkatkan prestasi model dengan ketara dalam pelbagai tugasan teks dan kod, dan berkesan mengurangkan ilusi penjanaan bahasa dalam domain tertutup. Walaupun eksperimen dalam kertas ini tertumpu terutamanya pada peringkat pra-latihan, pembungkusan penyesuaian optimum juga boleh digunakan secara meluas dalam peringkat lain seperti penalaan halus. Kerja ini menyumbang kepada pembangunan model bahasa yang lebih cekap dan boleh dipercayai serta memajukan pembangunan teknologi latihan model bahasa.
Untuk butiran penyelidikan lanjut, sila lihat kertas asal. Jika anda berminat dengan pekerjaan atau internship, anda boleh menghubungi penulis artikel ini melalui e-mel di zijwan@amazon.com.
Atas ialah kandungan terperinci ICML 2024 |. Sempadan baharu bagi pra-latihan model bahasa besar: 'Pembungkusan Penyesuaian Terbaik' membentuk semula standard pemprosesan dokumen. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn


