
Rumah >Peranti teknologi >AI >Cara baharu untuk bermain sumber ramai! Ujian penanda aras telah dilahirkan di Arena LLM untuk memisahkan pelajar jahat dan pelajar terbaik dengan tegas.
Cara baharu untuk bermain sumber ramai! Ujian penanda aras telah dilahirkan di Arena LLM untuk memisahkan pelajar jahat dan pelajar terbaik dengan tegas.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-06-02 13:21:08455semak imbas
Syarikat manakah yang terbaik dalam ranking model besar? Tonton juga LLM Arena~
Setakat ini, sejumlah 90 LLM telah menyertai pertempuran, dan jumlah undian pengguna telah melebihi 770,000.
 Gambar
Gambar
Namun, ketika netizen mempersendakan model baharu yang bergegas ke atas dan model lama kehilangan maruah mereka, LMSYS, organisasi di belakang Renjia Arena, secara senyap-senyap telah menyelesaikan kebanyakan transformasi keputusan: dari The ujian penanda aras yang meyakinkan dilahirkan dalam pertempuran sebenar-Arena-Hard. .
- Kedudukan yang paling hampir dengan Chatbot Arena pada 89.1%; peperiksaan berskala besar ini mesti dibezakan, dan pelajar miskin tidak boleh mendapat 90 mata; , soalan tidak boleh bocor, jadi data ujian mesti dikemas kini dengan kerap untuk memastikan kesaksamaan peperiksaan
 - Dua keperluan terakhir dibuat khusus untuk Arena LLM.
- Dua keperluan terakhir dibuat khusus untuk Arena LLM.
Mari kita lihat kesan penanda aras baharu:
Gambar
Gambar di atas membandingkan Arena Hard v0.1 dengan penanda aras SOTA MT Bench.
Kita dapati bahawa berbanding dengan MT Bench, Arena Hard v0.1 mempunyai kebolehpisahan yang lebih kuat (lonjakan daripada 22.6% kepada 87.4%), dan selang keyakinan juga lebih sempit.
Selain itu, lihat ranking ini, yang pada asasnya konsisten dengan ranking arena LLM terkini di bawah:
Gambar
Ini menunjukkan bahawa penilaian Arena Hard sangat hampir dengan penilaian manusia (89.1 %) .
——Arena Hard boleh dianggap sebagai membuka cara baharu penyumberan ramai:
Netizen mendapat pengalaman percuma, dan platform rasmi mendapat kedudukan paling berpengaruh, serta data segar dan berkualiti tinggi— — Dunia di mana tiada siapa yang terluka adalah lengkap.
 Soalan untuk model besar
Soalan untuk model besar
Jom lihat cara membina penanda aras ini.
Ringkasnya, ini adalah cara memilih beberapa yang lebih baik daripada 200,000 gesaan (soalan) pengguna di arena.
"Baik" ini dicerminkan dalam dua aspek: kepelbagaian dan kerumitan. Gambar berikut menunjukkan aliran kerja Arena-Hard:
 Pictures
Pictures
Untuk meringkaskan: pertama kelaskan semua gesaan (lebih daripada 4,000 topik dibahagikan di sini), dan kemudian tetapkan beberapa standard secara buatan untuk mengklasifikasikan setiap Petua diberi markah , dan petua dalam kategori yang sama dipuratakan.
Kategori dengan skor tinggi boleh dianggap mempunyai kerumitan (atau kualiti) yang tinggi - iaitu maksud "Keras" dalam Arena-Hard.
Pilih 250 kategori skor tertinggi teratas (250 memastikan kepelbagaian), dan pilih secara rawak 2 gesaan bertuah daripada setiap kategori untuk membentuk set penanda aras terakhir (500 gesaan).
Kembangkan secara terperinci di bawah:
Kepelbagaian
Para penyelidik mula-mula mengubah setiap petua menggunakan OpenAI's text-embedding-3-small, mengurangkan dimensi menggunakan UMAP dan mengenal pasti kelompok menggunakan algoritma pengelompokan berasaskan hierarki (HDBSCAN), Kemudian gunakan GPT-4 -turbo untuk pengagregatan.
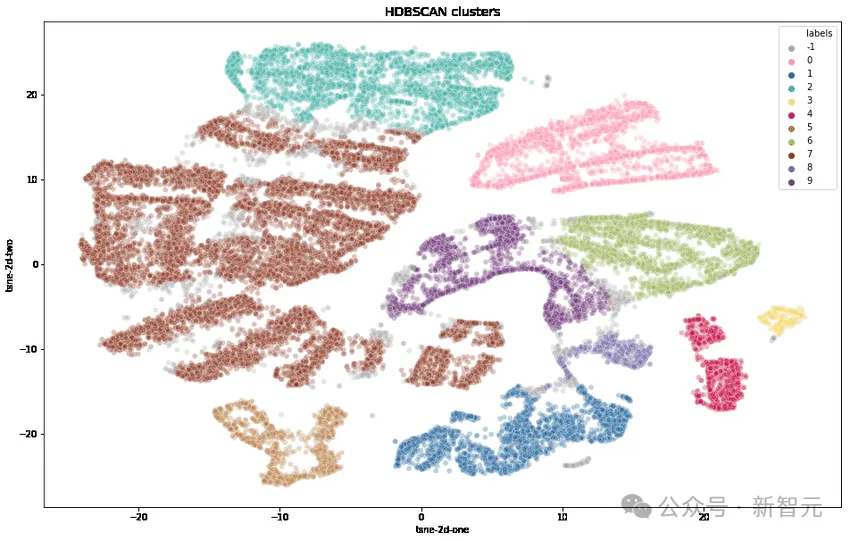
Complexity
Pilih pertanyaan pengguna berkualiti tinggi melalui tujuh kriteria utama dalam jadual di bawah:
 image
image
1. Prompt sama ada untuk meminta output tertentu?
2. Adakah ia meliputi satu atau lebih kawasan tertentu?
3. Adakah anda mempunyai pelbagai peringkat penaakulan, komponen atau pembolehubah?
4 Sekiranya AI secara langsung menunjukkan keupayaannya untuk menyelesaikan masalah?
5. Adakah terdapat tahap kreativiti yang terlibat?
6. Adakah ketepatan teknikal tindak balas diperlukan?
7. Adakah ia berkaitan dengan aplikasi praktikal?
Untuk setiap petua, gunakan LLM (GPT-3.5-Turbo, GPT-4-Turbo) untuk menandakan berapa banyak kriteria yang dipenuhi (skor 0 hingga 7), kemudian, hitung purata setiap kumpulan petua (pengelompokan) Pecahan.
Angka berikut menunjukkan kedudukan purata skor beberapa kelompok:
 Gambar
Gambar
Kita dapat perhatikan bahawa kelompok dengan markah yang lebih tinggi biasanya merupakan topik yang lebih mencabar (seperti pembangunan permainan, mathematical proof). kelompok dengan markah yang lebih rendah tergolong dalam masalah remeh atau samar-samar.
Dengan kerumitan ini, jurang antara pelajar cemerlang dan pelajar miskin boleh diluaskan. Mari lihat hasil eksperimen di bawah:
 Gambar
Gambar
Dalam perbandingan 3-PT di atas. daripada Llama2-70b, cawan besar Claude lebih kuat daripada cawan sederhana, Mistral-Large lebih kuat daripada Mixtral,
Kita dapat melihat bahawa apabila skor (kerumitan) meningkat, kadar kemenangan model yang lebih kuat Ia juga bertambah baik - pelajar terbaik dibezakan dan pelajar buruk ditapis.
Oleh kerana semakin tinggi skor (semakin kompleks masalahnya), semakin baik diskriminasi, jadi 250 klasifikasi berkualiti tinggi dengan purata skor >= 6 mata (daripada 7 mata) akhirnya dipilih.
Kemudian, 2 petua daripada setiap kategori dipilih secara rawak untuk membentuk versi penanda aras ini - Arena-Hard-v0.1.
Adakah penjaring ujian boleh dipercayai?
Sekarang kertas ujian sudah keluar, siapa yang akan menilai mereka adalah satu soalan.
Sudah tentu kerja manual adalah yang paling tepat, dan kerana ini adalah "Mod Keras", banyak isu yang melibatkan pengetahuan domain masih memerlukan pakar untuk menilai - ini jelas tidak mungkin.
Maka perkara terbaik seterusnya ialah memilih GPT-4, model paling bijak yang diiktiraf pada masa ini, sebagai guru ujian.
Sebagai contoh, dalam carta di atas, semua aspek pemarkahan dikendalikan oleh GPT-4. Selain itu, penyelidik menggunakan CoT untuk menggesa LLM menjana jawapan sebelum membuat keputusan.
hasil penghakiman GPT-4
Yang berikut menggunakan gpt-4-1106-pratonton sebagai model penghakiman, dan garis dasar untuk perbandingan menggunakan gpt-4-0314.
 Gambar
Gambar
Pekali Bradley-Terry bagi setiap model dibandingkan dan dikira dalam jadual di atas, dan ditukar kepada kadar kemenangan berbanding garis dasar sebagai skor akhir. 95% selang keyakinan telah dikira melalui 100 pusingan bootstrap.
Claude meluahkan rasa tidak puas hati
——Saya, Claude-3 Opus, juga terikat di kedudukan pertama Mengapa saya harus membiarkan GPT menjadi hakim?
Jadi, penyelidik membandingkan prestasi GPT-4-1106-Preview dan Claude-3 Opus sebagai guru pemarkahan.
Ringkasan dalam satu ayat: GPT-4 adalah bapa yang tegas dan Claude-3 ialah ibu yang penyayang.
 Imej
Imej
Kebolehpisahan merentas model adalah lebih tinggi (antara 23.0 hingga 78.0) apabila dijaringkan menggunakan GPT-4.
Apabila menggunakan Claude-3, markah kebanyakan model telah banyak meningkat: Saya pastinya perlu menjaga model saya sendiri, saya juga suka model sumber terbuka (Mixtral, Yi, Starling), gpt-4-0125 -preview juga Lebih baik daripada saya sememangnya.
Claude-3 malah lebih suka gpt-3.5-0613 daripada gpt-4-0613.
Jadual di bawah membandingkan lagi GPT-4 dan Claude-3 menggunakan metrik kebolehpisahan dan ketekalan:
 Gambar
Gambar
Daripada data yang terhasil, GPT-4 lebih baik.
Dengan membandingkan secara manual contoh penghakiman yang berbeza antara GPT-4 dan Claude-3, kita boleh mendapati bahawa apabila dua LLM tidak bersetuju, mereka biasanya boleh dibahagikan kepada dua kategori utama:
Pemarkahan konservatif dan pemarkahan pandangan konservatif berbeza daripada gesaan pengguna.
Claude-3-Opus lebih berlembut dalam memberikan markah dan lebih kecil kemungkinannya untuk memberikan markah yang keras - amat teragak-agak untuk mendakwa bahawa satu jawapan adalah "lebih baik" daripada yang lain.
Sebaliknya, GPT-4-Turbo mengenal pasti ralat dalam tindak balas model dan menghukum model dengan markah yang jauh lebih rendah.
Sebaliknya, Claude-3-Opus kadangkala mengabaikan ralat yang lebih kecil. Walaupun Claude-3-Opus mendapati ralat ini, ia cenderung menganggapnya sebagai isu kecil dan sangat berlembut semasa proses pemarkahan.
Walaupun dalam masalah pengekodan dan matematik di mana kesilapan kecil sebenarnya boleh merosakkan jawapan akhir sepenuhnya, Claude-3-Opus masih melayan kesilapan ini dengan lembut, GPT-4-Turbo tidak.
 Gambar
Gambar
Untuk satu lagi set petua yang kecil, Claude-3-Opus dan GPT-4-Turbo dinilai dari perspektif asas yang berbeza.
Sebagai contoh, memandangkan masalah pengekodan, Claude-3-Opus lebih suka struktur ringkas yang tidak bergantung pada perpustakaan luaran, yang boleh memberikan pengguna respons nilai pendidikan maksimum.
Dan GPT-4-Turbo mungkin mengutamakan respons yang memberikan jawapan yang paling praktikal, tanpa mengira nilai pendidikannya kepada pengguna.
Walaupun kedua-dua penjelasan adalah kriteria yang sah untuk menilai, pandangan GPT-4-Turbo mungkin lebih hampir kepada pengguna biasa.
Lihat imej di bawah untuk contoh khusus penghakiman berbeza, kebanyakannya mempamerkan fenomena ini.
 Gambar
Gambar
Ujian Terhad
LLM Suka jawapan yang lebih panjang?
Purata panjang token dan markah setiap model pada MT-Bench dan Arena-Hard-v0.1 diplotkan di bawah. Secara visual, tidak ada korelasi yang kuat antara pecahan dan panjang.
 Gambar
Gambar
Untuk mengkaji lebih lanjut potensi bias verbositi, penyelidik menggunakan GPT-3.5-Turbo untuk menghapuskan tiga gesaan sistem yang berbeza (mentah, cerewet, verbose).
Hasilnya menunjukkan bahawa pertimbangan GPT-4-Turbo dan Claude-3-Opus mungkin dipengaruhi oleh output yang lebih panjang, manakala Claude lebih terjejas (kerana pertimbangan GPT-3.5-Turbo terhadap GPT-4-0314 The kadar kemenangan melebihi 40%).
Menariknya, "ceramah" mempunyai sedikit kesan pada kadar kemenangan kedua-dua hakim, menunjukkan bahawa panjang output bukan satu-satunya faktor, dan jawapan yang lebih terperinci juga mungkin digemari oleh hakim LLM.
 Pictures
Pictures
Tips for Eksperimen:
Detailed: Anda adalah pembantu yang membantu yang menerangkan perkara dengan teliti dengan seberapa banyak yang mungkin
Variance pertimbangan GPT-4
Para penyelidik mendapati bahawa walaupun dengan suhu = 0, GPT-4-Turbo mungkin masih menghasilkan pertimbangan yang sedikit berbeza.
Penghakiman berikut pada gpt-3.5-turbo-0125 diulang tiga kali dan varians dikira.
Gambar
 Disebabkan bajet terhad, hanya satu penilaian untuk semua model dilakukan di sini. Walau bagaimanapun, penulis mengesyorkan menggunakan selang keyakinan untuk menentukan pemisahan model.
Disebabkan bajet terhad, hanya satu penilaian untuk semua model dilakukan di sini. Walau bagaimanapun, penulis mengesyorkan menggunakan selang keyakinan untuk menentukan pemisahan model.
Rujukan:
https://www.php.cn/link/6e361e90ca5f9bee5b36f3d413c51842Atas ialah kandungan terperinci Cara baharu untuk bermain sumber ramai! Ujian penanda aras telah dilahirkan di Arena LLM untuk memisahkan pelajar jahat dan pelajar terbaik dengan tegas.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!