

 Peranti teknologiAIMenyesuaikan diri dengan pelbagai bentuk dan tugas, sistem pembelajaran robot sumber terbuka yang paling berkuasa 'Octopus' telah dilahirkan
Peranti teknologiAIMenyesuaikan diri dengan pelbagai bentuk dan tugas, sistem pembelajaran robot sumber terbuka yang paling berkuasa 'Octopus' telah dilahirkanMenyesuaikan diri dengan pelbagai bentuk dan tugas, sistem pembelajaran robot sumber terbuka yang paling berkuasa 'Octopus' telah dilahirkan

Dari segi pembelajaran robot, pendekatan biasa ialah mengumpul set data khusus untuk robot dan tugas tertentu, dan kemudian menggunakannya untuk melatih dasar. Walau bagaimanapun, jika kaedah ini digunakan untuk belajar dari awal, data yang mencukupi perlu dikumpul untuk setiap tugas, dan keupayaan generalisasi dasar yang dihasilkan biasanya lemah.
“Pada dasarnya, pengalaman yang dikumpul daripada robot dan tugasan lain boleh memberikan penyelesaian yang mungkin, membolehkan model melihat pelbagai masalah kawalan robot, dan masalah ini boleh meningkatkan prestasi umum robot pada tugas hiliran adalah model umum yang boleh mengendalikan pelbagai bahasa semula jadi dan tugas penglihatan komputer, masih sukar untuk membina "model robot universal" untuk melatih strategi kawalan bersatu untuk robot Amat sukar, melibatkan banyak kesukaran termasuk mengendalikan badan robot yang berbeza. konfigurasi sensor, ruang tindakan, spesifikasi tugas, persekitaran dan belanjawan pengiraan.
Untuk mencapai matlamat ini, beberapa hasil penyelidikan yang berkaitan dengan "model asas robot" telah muncul; pendekatan mereka adalah untuk memetakan secara langsung pemerhatian robot ke dalam tindakan, dan kemudian membuat generalisasi kepada medan baharu atau robot baharu melalui penyelesaian sampel sifar. Model ini sering dirujuk sebagai "dasar robot generalis," atau GRP, yang menekankan keupayaan robot untuk melaksanakan kawalan visuomotor peringkat rendah merentas pelbagai tugas, persekitaran dan sistem robotik.
GNM (Model Navigasi Umum) sesuai untuk pelbagai senario navigasi robot yang berbeza RoboCat boleh mengendalikan badan robot yang berbeza mengikut matlamat misi RT-X boleh mengendalikan lima badan robot yang berbeza melalui bahasa. Walaupun model ini sememangnya merupakan kemajuan yang penting, mereka juga mengalami beberapa batasan: pemerhatian input mereka sering dipratakrifkan dan selalunya terhad (seperti aliran video input kamera tunggal, mereka sukar untuk diperhalusi dengan berkesan kepada domain baharu; model Versi terbesar tidak tersedia untuk digunakan oleh orang ramai (ini penting).
Baru-baru ini, Pasukan Model Octo terdiri daripada 18 penyelidik dari Universiti California, Berkeley, Universiti Stanford, Universiti Carnegie Mellon dan Google DeepMind mengeluarkan hasil penyelidikan terobosan mereka: model Octo. Projek ini berjaya mengatasi batasan di atas.

- Alamat kertas: https://arxiv.org.org/pdf/240 Projek sumber terbuka : https://octo-models.github.io/
- Mereka mereka bentuk sistem yang membolehkan GRP lebih mudah menangani isu kepelbagaian antara muka aplikasi robot hiliran.
- Inti model ialah seni bina Transformer, yang memetakan token input sewenang-wenangnya (dicipta berdasarkan pemerhatian dan tugasan) ke dalam token output (kemudian dikodkan ke dalam tindakan), dan seni bina ini boleh digunakan dengan robot yang pelbagai dan set data tugas kereta api. Dasar ini boleh menerima konfigurasi kamera yang berbeza tanpa latihan tambahan, boleh mengawal robot yang berbeza dan boleh dibimbing oleh arahan lisan atau imej sasaran—semuanya dengan hanya menukar input token kepada model.
Paling penting, model ini juga boleh menyesuaikan diri dengan konfigurasi robot baharu dengan input sensor yang berbeza, ruang operasi atau morfologi robot Apa yang diperlukan ialah menggunakan penyesuai yang sesuai dan menggunakan set data domain sasaran yang kecil dan sejumlah kecil data.
Bukan itu sahaja, Octo juga telah dilatih terlebih dahulu mengenai set data manipulasi robot terbesar setakat ini - 800,000 demonstrasi robot daripada set data Open X-Embodiment. Octo bukan sahaja GRP pertama yang diperhalusi dengan cekap kepada ruang pemerhatian dan tindakan baharu, ia juga merupakan strategi manipulasi robot generalis pertama yang sumber terbuka sepenuhnya (aliran kerja latihan, pusat pemeriksaan model dan data). Pasukan itu juga menyerlahkan dalam kertas itu sifat unik dan inovatif gabungan komponen Octonya.
Model Oktober
Mari kita lihat bagaimana Octo, strategi robot generalis sumber terbuka, dibina. Secara keseluruhan, Octo direka bentuk untuk menjadi strategi robotik generalis yang fleksibel dan boleh digunakan secara meluas yang boleh digunakan oleh beberapa aplikasi robotik hiliran yang berbeza dan projek penyelidikan.
Senibina
Teras Octo adalah berdasarkan strategi Transformer π. Ia mengandungi tiga bahagian utama: tokenizer input, rangkaian tulang belakang Transformer dan kepala bacaan.
Seperti yang ditunjukkan dalam Rajah 2, fungsi tokenizer input adalah untuk menukar arahan bahasa, sasaran dan urutan pemerhatian kepada token Tulang belakang Transformer akan memproses token ini menjadi benam, dan kepala bacaan akan memperoleh output yang diperlukan. iaitu tindakan.
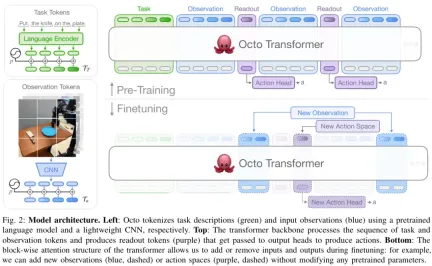
Task and Observation Tokenizer
Untuk menukar definisi tugas (seperti arahan bahasa dan imej sasaran) dan pemerhatian (seperti strim video kamera) ke dalam format token yang biasa digunakan, modaliti yang disasarkan berbeza tokenizer:
Untuk input bahasa, ia di token terlebih dahulu, dan kemudian diproses menjadi urutan token pembenaman bahasa melalui Transformer yang telah terlatih. Secara khusus, model yang mereka gunakan ialah t5-base (111M).
Untuk pemerhatian imej dan sasaran, ia diproses melalui timbunan lilitan yang lebih cetek dan kemudian dipecah menjadi urutan jubin yang diratakan.
Akhir sekali, jujukan input Transformer dibina dengan menambahkan pembenaman kedudukan yang boleh dipelajari pada token tugas dan pemerhatian dan menyusunnya dalam susunan tertentu.
Tulang belakang transformer dan kepala pembacaan
Selepas memproses input menjadi urutan token bersatu, ia boleh diserahkan kepada Transformer untuk diproses. Ini adalah serupa dengan kerja penyelidikan terdahulu mengenai latihan dasar berasaskan Transformer berdasarkan pemerhatian dan urutan tindakan.
Mod perhatian bulan Oktober ialah penyamaran blok demi blok: token pemerhatian hanya boleh memberi perhatian kepada token dan token tugas daripada langkah masa yang sama atau sebelumnya mengikut hubungan sebab akibat. Token yang sepadan dengan pemerhatian yang tidak wujud adalah bertopeng sepenuhnya (seperti set data tanpa arahan bahasa). Reka bentuk modular ini memudahkan untuk menambah atau mengalih keluar pemerhatian atau tugas semasa fasa penalaan halus.
Sebagai tambahan kepada modul token input ini, pasukan juga memasukkan token bacaan yang dipelajari. Token pembacaan akan memberi perhatian kepada pemerhatian sebelumnya dan token tugas, tetapi tidak akan diberi perhatian oleh mana-mana pemerhatian atau token tugas. Oleh itu, token bacaan hanya boleh membaca dan memproses pembenaman dalaman, tetapi tidak boleh menjejaskan pembenaman dalaman. Token pembacaan bertindak sama dengan token [CLS] dalam BERT, bertindak sebagai pembenaman vektor padat bagi jujukan pemerhatian setakat ini. Untuk pembenaman token baca, "pengepala tindakan" ringan yang melaksanakan proses penyebaran akan digunakan. Pengepala tindakan ini meramalkan "sebahagian" berbilang tindakan berturut-turut.
Reka bentuk ini membolehkan pengguna menambahkan tugas baharu dan pengepala input atau output tindakan secara fleksibel pada model semasa penalaan halus hiliran. Apabila menambah tugasan baharu, pemerhatian atau fungsi kehilangan hiliran, anda boleh mengekalkan pemberat pralatihan Transformer secara keseluruhan dan hanya menambah pembenaman kedudukan baharu, pengekod ringan baharu atau pengepala baharu yang diperlukan disebabkan oleh perubahan spesifikasi. Ini berbeza daripada seni bina sebelumnya, yang memerlukan pemulaan semula atau latihan semula pelbagai komponen model pralatihan jika input imej ditambah atau dialih keluar atau spesifikasi tugasan diubah.
Untuk menjadikan Octo model "generalis" sebenar, fleksibiliti ini penting: kerana adalah mustahil bagi kami untuk merangkumi semua konfigurasi penderia dan tindakan robot yang mungkin dalam peringkat pra-latihan, jika kami boleh melaraskan Octo dengan baik- peringkat penalaan Input dan outputnya menjadikannya alat serba boleh untuk komuniti robotik. Selain itu, reka bentuk model sebelumnya yang menggunakan tulang belakang Transformer standard atau menggabungkan pengekod visual dengan kepala keluaran MLP membetulkan jenis dan susunan input model. Sebaliknya, menukar pemerhatian atau tugas Octo tidak memerlukan pemulaan semula kebanyakan model.
Data latihan
Pasukan mengambil set data campuran 25 set data daripada Open X-Embodiment. Rajah 3 memberikan komposisi set data.

Sila rujuk kertas asal untuk butiran lanjut tentang objektif latihan dan konfigurasi perkakasan latihan.
Model pusat pemeriksaan dan kod
Inilah hakikatnya! Pasukan ini bukan sahaja mengeluarkan kertas kerja Octo, tetapi juga sumber terbuka sepenuhnya semua sumber, termasuk:
- Pusat pemeriksaan Octo pra-latihan, termasuk Octo-Small dengan 27 juta parameter dan Octo-Base dengan 93 juta parameter.
- Skrip penalaan halus untuk model Octo, berdasarkan JAX.
- Model aliran kerja pra-latihan untuk Octo pra-latihan pada set data Open X-Embodiment, berdasarkan JAX. Pemuat data untuk data Open X-Embodiment, serasi dengan JAX dan PyTorch.
Eksperimen
Pasukan juga menjalankan analisis empirikal Octo melalui eksperimen dan menilai prestasinya sebagai model robot asas dalam pelbagai dimensi:
- Bolehkah robot digunakan secara langsung? badan dan menyelesaikan bahasa dan tugasan sasaran?
- Bolehkah pemberat Octo berfungsi sebagai asas permulaan yang baik untuk menyokong penalaan halus yang cekap data untuk tugasan dan robot baharu, dan adakah ia lebih baik daripada kaedah latihan dari awal dan perwakilan pra-latihan yang biasa digunakan?
- Keputusan reka bentuk manakah dalam Octo yang paling penting dalam membina strategi robot generalis?
Rajah 4 menunjukkan 9 tugasan untuk menilai Octo.

Gunakan Octo secara langsung untuk mengawal berbilang robot
Pasukan membandingkan keupayaan kawalan sampel sifar Octo, RT-1-X dan RT-2-X. Hasilnya ditunjukkan dalam Rajah 5.
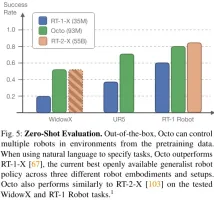
Dapat dilihat bahawa kadar kejayaan Octo adalah 29% lebih tinggi daripada RT-1-X (35 juta parameter). Dalam penilaian Robot WidowX dan RT-1, prestasi Octo adalah setara dengan RT-2-X dengan 55 bilion parameter.
Selain itu, RT-1-X dan RT-2-X hanya menyokong arahan bahasa, manakala Octo turut menyokong imej bersyarat pada sasaran. Pasukan itu juga mendapati bahawa pada tugas WidowX, kadar kejayaan adalah 25% lebih tinggi apabila dikondisikan pada imej sasaran berbanding apabila dikondisikan pada bahasa. Ini mungkin kerana imej sasaran memberikan lebih banyak maklumat tentang penyiapan tugas.
Oktober boleh menggunakan data dengan cekap untuk menyesuaikan diri dengan medan baharu
Jadual 1 memberikan hasil percubaan penalaan halus yang cekap data.

Anda dapat melihat bahawa penalaan halus Octo memberikan hasil yang lebih baik daripada latihan dari awal atau pra-latihan dengan pemberat VC-1 yang telah dilatih. Merentasi 6 tetapan penilaian, kelebihan purata Octo berbanding garis dasar tempat kedua ialah 52%!
Dan saya perlu menyebut: untuk semua tugas penilaian ini, resipi dan hiperparameter yang digunakan semasa menala halus Octo semuanya adalah sama, yang menunjukkan bahawa pasukan itu menemui konfigurasi lalai yang sangat baik. Keputusan reka bentuk untuk latihan dasar robot generalis . Seterusnya, pasukan menganalisis kesan keputusan reka bentuk yang berbeza terhadap prestasi strategi Octo. Secara khusus, mereka memberi tumpuan kepada aspek berikut: seni bina model, data latihan, objektif latihan dan saiz model. Untuk melakukan ini, mereka menjalankan kajian ablasi.
Jadual 2 menunjukkan hasil kajian ablasi mengenai seni bina model, data latihan dan objektif latihan.
Rajah 6 menunjukkan kesan saiz model pada kadar kejayaan sampel sifar Ia boleh dilihat bahawa model yang lebih besar mempunyai keupayaan persepsi pemandangan visual yang lebih baik.
 Secara keseluruhannya, keberkesanan komponen Octo telah terbukti.
Secara keseluruhannya, keberkesanan komponen Octo telah terbukti.
Atas ialah kandungan terperinci Menyesuaikan diri dengan pelbagai bentuk dan tugas, sistem pembelajaran robot sumber terbuka yang paling berkuasa 'Octopus' telah dilahirkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bahaya Tersembunyi Penggunaan Dalaman AI: Jurang Tadbir Urus dan Risiko BencanaApr 28, 2025 am 11:12 AM
Bahaya Tersembunyi Penggunaan Dalaman AI: Jurang Tadbir Urus dan Risiko BencanaApr 28, 2025 am 11:12 AMPenyebaran dalaman yang tidak terkawal sistem AI yang canggih menimbulkan risiko yang signifikan, menurut laporan baru dari Apollo Research. Kekurangan pengawasan ini, lazim di kalangan firma AI utama, membolehkan hasil yang berpotensi bencana, mulai dari UNCON
 Membina polygraph AIApr 28, 2025 am 11:11 AM
Membina polygraph AIApr 28, 2025 am 11:11 AMPengesan kebohongan tradisional sudah lapuk. Bergantung pada penunjuk yang disambungkan oleh gelang tangan, pengesan kebohongan yang mencetak tanda -tanda penting subjek dan tindak balas fizikal tidak tepat dalam mengenal pasti kebohongan. Inilah sebabnya mengapa keputusan pengesanan kebohongan biasanya tidak diterima pakai oleh mahkamah, walaupun ia telah membawa kepada banyak orang yang tidak bersalah yang dipenjara. Sebaliknya, kecerdasan buatan adalah enjin data yang kuat, dan prinsip kerja adalah untuk memerhatikan semua aspek. Ini bermakna saintis boleh menggunakan kecerdasan buatan kepada aplikasi yang mencari kebenaran melalui pelbagai cara. Satu pendekatan adalah untuk menganalisis tindak balas penting orang yang diinterogasi seperti pengesan dusta, tetapi dengan analisis perbandingan yang lebih terperinci dan tepat. Pendekatan lain adalah menggunakan markup linguistik untuk menganalisis apa yang orang katakan dan menggunakan logik dan penalaran. Seperti kata pepatah, satu pembohongan membiak kebohongan yang lain, dan akhirnya
 Adakah AI dibersihkan untuk berlepas dalam industri aeroangkasa?Apr 28, 2025 am 11:10 AM
Adakah AI dibersihkan untuk berlepas dalam industri aeroangkasa?Apr 28, 2025 am 11:10 AMIndustri aeroangkasa, perintis inovasi, memanfaatkan AI untuk menangani cabaran yang paling rumit. Kerumitan Peningkatan Penerbangan Moden memerlukan automasi dan keupayaan perisikan masa nyata AI untuk keselamatan yang dipertingkatkan, dikurangkan oper
 Menonton Perlumbaan Robot Spring BeijingApr 28, 2025 am 11:09 AM
Menonton Perlumbaan Robot Spring BeijingApr 28, 2025 am 11:09 AMPerkembangan pesat robotik telah membawa kita kajian kes yang menarik. Robot N2 dari Noetix beratnya lebih dari 40 paun dan tinggi 3 kaki dan dikatakan dapat backflip. Robot G1 Unitree berat kira -kira dua kali saiz N2 dan kira -kira 4 kaki tinggi. Terdapat juga banyak robot humanoid yang lebih kecil yang menyertai pertandingan ini, dan terdapat juga robot yang didorong ke hadapan oleh peminat. Tafsiran data Setengah maraton menarik lebih daripada 12,000 penonton, tetapi hanya 21 robot humanoid yang mengambil bahagian. Walaupun kerajaan menegaskan bahawa robot yang mengambil bahagian menjalankan "latihan intensif" sebelum pertandingan, tidak semua robot menyelesaikan keseluruhan persaingan. Champion - Tiangong Ult Dibangunkan oleh Pusat Inovasi Robot Humanoid Beijing
 Perangkap Cermin: Etika AI dan keruntuhan imaginasi manusiaApr 28, 2025 am 11:08 AM
Perangkap Cermin: Etika AI dan keruntuhan imaginasi manusiaApr 28, 2025 am 11:08 AMKecerdasan buatan, dalam bentuknya sekarang, tidak benar -benar pintar; Ia mahir meniru dan menyempurnakan data sedia ada. Kami tidak mewujudkan kecerdasan buatan, tetapi sebaliknya kesimpulan buatan -merapikan yang memproses maklumat, sementara manusia su
 New Google Leak mendedahkan kemas kini ciri Google Photos yang bergunaApr 28, 2025 am 11:07 AM
New Google Leak mendedahkan kemas kini ciri Google Photos yang bergunaApr 28, 2025 am 11:07 AMLaporan mendapati bahawa antara muka yang dikemas kini disembunyikan dalam kod untuk Google Photos Android versi 7.26, dan setiap kali anda melihat foto, satu baris lakaran muka yang baru dikesan dipaparkan di bahagian bawah skrin. Thumbnail wajah baru adalah tag nama yang hilang, jadi saya mengesyaki anda perlu mengkliknya secara individu untuk melihat lebih banyak maklumat mengenai setiap orang yang dikesan. Buat masa ini, ciri ini tidak memberikan maklumat selain daripada orang -orang yang ditemui oleh Google Foto dalam imej anda. Ciri ini belum tersedia, jadi kami tidak tahu bagaimana Google akan menggunakannya dengan tepat. Google boleh menggunakan gambar kecil untuk mempercepatkan mencari lebih banyak gambar orang terpilih, atau boleh digunakan untuk tujuan lain, seperti memilih individu untuk mengedit. Mari tunggu dan lihat. Buat masa ini
 Panduan untuk Finetuning Pengukuhan - Analytics VidhyaApr 28, 2025 am 09:30 AM
Panduan untuk Finetuning Pengukuhan - Analytics VidhyaApr 28, 2025 am 09:30 AMPenguatkuasaan penguatkuasaan telah mengguncang pembangunan AI dengan mengajar model untuk menyesuaikan berdasarkan maklum balas manusia. Ia menggabungkan asas pembelajaran yang diawasi dengan kemas kini berasaskan ganjaran untuk menjadikannya lebih selamat, lebih tepat, dan benar-benar membantu
 Let's Dance: Gerakan berstruktur untuk menyempurnakan jaring saraf manusia kitaApr 27, 2025 am 11:09 AM
Let's Dance: Gerakan berstruktur untuk menyempurnakan jaring saraf manusia kitaApr 27, 2025 am 11:09 AMPara saintis telah mengkaji secara meluas rangkaian saraf manusia dan mudah (seperti yang ada di C. elegans) untuk memahami fungsi mereka. Walau bagaimanapun, soalan penting timbul: Bagaimana kita menyesuaikan rangkaian saraf kita sendiri untuk berfungsi dengan berkesan bersama -sama dengan novel AI s


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Dreamweaver CS6
Alat pembangunan web visual

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

