


之前听说火狐的JS引擎支持for each in的语法,例如下述的代码:
var arr = [10,20,30,40,50];
for each(var k in arr)
console.log(k);
即可直接遍历出arr数组的内容。
由于只有FireFox才支持,所以几乎所有的JS代码都不用这一特征。
不过在ActionScript里天生就支持for each的语法,不论Array还是Vector,还是Dictionary,只要是可枚举的对象都可以for in和for each in。
之前并没有感觉有太大的差异,为了懒得敲一个each单词,一直用熟悉的for in来遍历。
不过今天仔细琢磨了会,从数据结构的角度分析了下,觉得for in和for each in效率上有着本质的区别,无论是JS还是AS。
原因很简单:Array不是真正意义上的数组!
何为真正意义的数组?当然就是传统语言里type[]定义的数据类型,所有元素都是连续保存的。
“Array”虽然也是数组的意思,但熟悉JS的都知道,它其实是个非线性的伪数组,下标可以是任意数字。写入arr[1000000]并非真正申请容纳一百万个元素的空间,而是把1000000转换成相应的哈希值,对应到很小一块储存空间里,从而节省了大量内存。
例如有如下数组:
var arr = [];
arr[10] = 1000;
arr[20] = 2000;
arr[30] = 5000;
arr[40] = 8000;
arr[200] = 9000;
用for...in遍历Array,是个很累赘的过程:
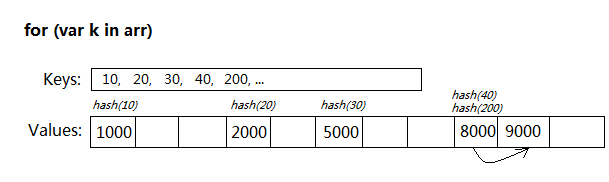
遍历时每次访问arr[k],都要进行一次Hash(k)计算,根据散列表的容量取模,最终在冲突链表里找到结果。
如果支持for each...in的语法,其内部的数据结构就决定了会快很多:
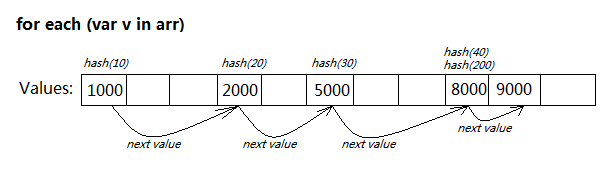
Array里储存存了keys的列表,也把每个values值作为链表关联起来。每当有值添加或删除,就更新其链接关系。
当for each...in遍历时,只需从第一个节点往后迭代即可,无需任何Hash计算。
当然,对于AS3里Vector这样的线性数组来说,两者相差不大;同理,HTML5里支持二进制的数组ArrayBuffer也是如此。不过从理论上来看,即使arr是个连续的线性数组,for each in还是要快一点:
for...in遍历时,每次访问arr[k]都要进行下标越界检查;而for each in则根据内部链表,直接从底层反馈出迭代变量,节省了越界检查的过程。

 JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AM
JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AMPenggunaan utama JavaScript dalam pembangunan web termasuk interaksi klien, pengesahan bentuk dan komunikasi tak segerak. 1) kemas kini kandungan dinamik dan interaksi pengguna melalui operasi DOM; 2) pengesahan pelanggan dijalankan sebelum pengguna mengemukakan data untuk meningkatkan pengalaman pengguna; 3) Komunikasi yang tidak bersesuaian dengan pelayan dicapai melalui teknologi Ajax.
 Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AM
Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AMMemahami bagaimana enjin JavaScript berfungsi secara dalaman adalah penting kepada pemaju kerana ia membantu menulis kod yang lebih cekap dan memahami kesesakan prestasi dan strategi pengoptimuman. 1) aliran kerja enjin termasuk tiga peringkat: parsing, penyusun dan pelaksanaan; 2) Semasa proses pelaksanaan, enjin akan melakukan pengoptimuman dinamik, seperti cache dalam talian dan kelas tersembunyi; 3) Amalan terbaik termasuk mengelakkan pembolehubah global, mengoptimumkan gelung, menggunakan const dan membiarkan, dan mengelakkan penggunaan penutupan yang berlebihan.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AMPython lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
 Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AMPython dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AM
Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AMPeralihan dari C/C ke JavaScript memerlukan menyesuaikan diri dengan menaip dinamik, pengumpulan sampah dan pengaturcaraan asynchronous. 1) C/C adalah bahasa yang ditaip secara statik yang memerlukan pengurusan memori manual, manakala JavaScript ditaip secara dinamik dan pengumpulan sampah diproses secara automatik. 2) C/C perlu dikumpulkan ke dalam kod mesin, manakala JavaScript adalah bahasa yang ditafsirkan. 3) JavaScript memperkenalkan konsep seperti penutupan, rantaian prototaip dan janji, yang meningkatkan keupayaan pengaturcaraan fleksibiliti dan asynchronous.
 Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AM
Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AMEnjin JavaScript yang berbeza mempunyai kesan yang berbeza apabila menguraikan dan melaksanakan kod JavaScript, kerana prinsip pelaksanaan dan strategi pengoptimuman setiap enjin berbeza. 1. Analisis leksikal: Menukar kod sumber ke dalam unit leksikal. 2. Analisis Tatabahasa: Menjana pokok sintaks abstrak. 3. Pengoptimuman dan Penyusunan: Menjana kod mesin melalui pengkompil JIT. 4. Jalankan: Jalankan kod mesin. Enjin V8 mengoptimumkan melalui kompilasi segera dan kelas tersembunyi, Spidermonkey menggunakan sistem kesimpulan jenis, menghasilkan prestasi prestasi yang berbeza pada kod yang sama.
 Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AM
Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AMAplikasi JavaScript di dunia nyata termasuk pengaturcaraan sisi pelayan, pembangunan aplikasi mudah alih dan Internet of Things Control: 1. Pengaturcaraan sisi pelayan direalisasikan melalui node.js, sesuai untuk pemprosesan permintaan serentak yang tinggi. 2. Pembangunan aplikasi mudah alih dijalankan melalui reaktnatif dan menyokong penggunaan silang platform. 3. Digunakan untuk kawalan peranti IoT melalui Perpustakaan Johnny-Five, sesuai untuk interaksi perkakasan.
 Membina aplikasi SaaS Multi-penyewa dengan Next.js (Integrasi Backend)Apr 11, 2025 am 08:23 AM
Membina aplikasi SaaS Multi-penyewa dengan Next.js (Integrasi Backend)Apr 11, 2025 am 08:23 AMSaya membina aplikasi SaaS multi-penyewa berfungsi (aplikasi edTech) dengan alat teknologi harian anda dan anda boleh melakukan perkara yang sama. Pertama, apakah aplikasi SaaS multi-penyewa? Aplikasi SaaS Multi-penyewa membolehkan anda melayani beberapa pelanggan dari Sing


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

Dreamweaver Mac版
Alat pembangunan web visual

