
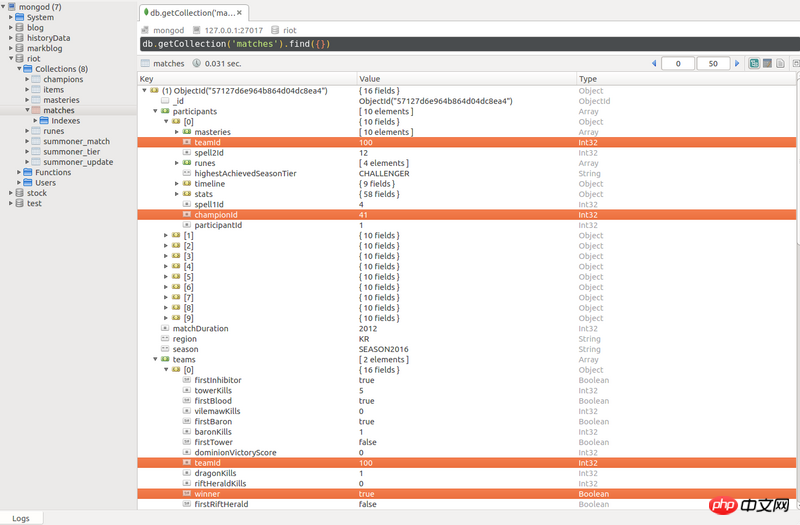
으아아아사진은 LOL 게임의 세부 사항을 기록하는 mongodb의 문서 구조를 보여줍니다.
참가자는 10명이며 처음 5개의 팀 ID는 100, 마지막 5개의 팀 ID는 200입니다. 게임 팀이 승리한 결과는 팀의 하위 문서에 기록됩니다.
현재 챔피언 ID가 64(리 신)과 157(야스오)인 두 영웅이 같은 팀에 속해 있을 때(지정된 게임 버전 번호 >6.7) 승리 횟수를 쿼리하고 싶습니다. , 쿼리문을 다음과 같이 작성했습니다.
데이터 크기가 140,000인데 이런 쿼리를 실행하는데 3초가 걸립니다. 해당 쿼리가 색인화되었습니다. explain 쿼리 결과는 다음과 같습니다 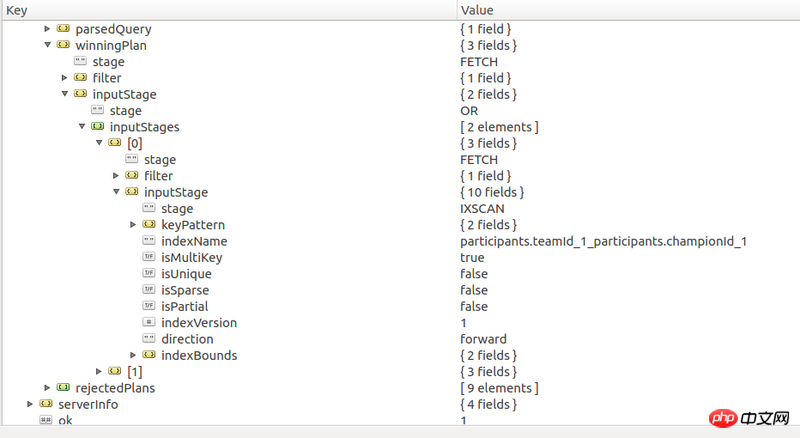
단, teams.teamId, teams.winner의 복합지수, matchVersion
이 쿼리를 어떻게 최적화할 수 있나요? 내 사용 습관으로 인해 이 데이터 크기가 발생하는 데 시간이 너무 오래 걸리는 것 같아요.
淡淡烟草味2017-05-02 09:20:33
귀하의 실행계획 지수를 사용하고 있으나 효율성이 높지 않음을 알 수 있으나, 핵심정보가 많이 접혀져 자세한 내용을 볼 수 없습니다. 다음번에는 원본 JSON을 직접 보내는 것이 이해하기 쉽기 때문에 가장 좋습니다. 마찬가지로 데이터 샘플이 있는 경우 JSON으로 보내는 것이 가장 좋습니다. 그러면 다른 사람들이 문제를 해결할 때 테스트 데이터의 복사본을 가질 수 있어 훨씬 편리합니다. $and이것은 대부분의 경우 나타날 필요가 없습니다. 객체의 두 평행 요소는 and 사이의 관계입니다. 이렇게 하면 쿼리 구조가 단순화되고 다른 사람이 보기가 더 쉬워집니다. 따라서 귀하의 쿼리는 다음과 같이 단순화되었습니다.
마지막이자 가장 중요한 인덱스 문제는 자신에게 더 유용한 인덱스는 participants.teamId+participants.championId+teams.teamId+teams.winner+matchVersion의 공동 인덱스가 되어야 한다는 추측입니다. 조건의 필터링 가능성에 따라 필터링해야 합니다. 더 나은 조건을 먼저 설정하세요. 쓰기 효율성을 높이기 위해 일부 조건을 제거할 수도 있습니다. 그러나 이는 데이터 분포에 따라 다릅니다.
인덱스가 사용되지 않는 이유는 무엇입니까? mongodb 2.6 이상에서는 교차 인덱싱을 지원하고 동일한 쿼리를 충족하기 위해 여러 인덱스를 사용할 수 있지만 현재 실행 계획 평가 시스템에서는 교차 인덱스를 트리거하기가 어렵습니다. 따라서 쿼리를 만족시키기 위해 인덱스를 사용해 보십시오.