
이제 이 코드를 인터넷에서 다운로드할 수 있습니다.
Github에서 배포된 코드를 다운로드했는데 어떻게 사용하는지 모르겠습니다. . .
다음은 홈페이지 주소입니다
https://github.com/rolando/scrapy-redis
위와 같이 환경을 구성했는데 배포가 어떻게 되는 지 모르겠습니다.
이것이 제가 분산을 이해하는 방법입니다. 웹 페이지에서 URL 시드를 가져와서 Redis 서버에 넣은 다음 이 URL 시드를 다른 시스템에 배포하는 Redis 서버가 있습니다. 중간에 스케줄링 문제도 있고, 서버와 머신 간의 통신 문제도 있습니다.
감사합니다. . .

PHP中文网2017-04-24 09:13:57
한두 문장으로 명확하게 설명할 수는 없는 것 같아요.
이전에 언급한 블로그 게시물이 여러분에게 도움이 되기를 바랍니다.
개인적인 이해에 대해 말씀드리겠습니다.
scrapy은 개선된 python 고유의 collection.deque을 사용하여 크롤링할 request을 저장합니다. 어떻게 두 명 이상의 Spider이 deque을 공유할 수 있나요?
크롤링할 대기열은 공유할 수 없으며 배포도 말도 안 됩니다. scrapy-redis이 솔루션을 제공하고, collection.deque을 redis 데이터베이스로 대체하고, 여러 크롤러가 동일한 redis 서버에서 크롤링할 request을 저장하므로 여러 spider가 동일한 Read in으로 이동할 수 있습니다. 데이터베이스화하여 유통의 주요 문제를 해결합니다.
참고: 는 redis을 request 스토어로 대체하지 않으며, scrapy는
scrapy은 待爬队列와 직접적으로 관련된 스케줄러 Scheduler입니다.
scrapy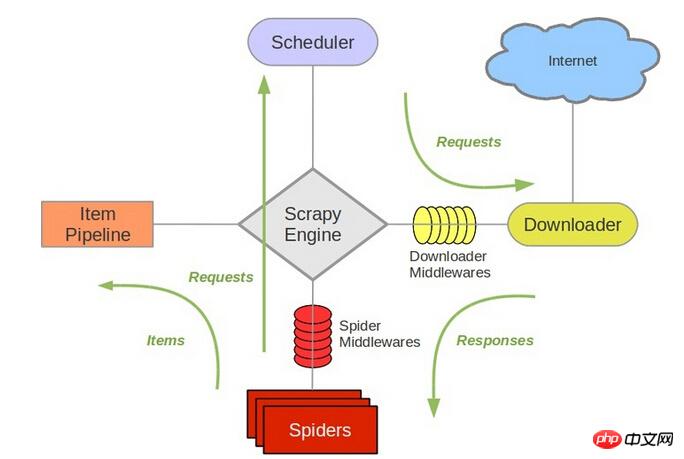
새 request를 대기열에 추가하고 크롤링할 다음 request을 꺼내는 등의 작업을 담당합니다. 따라서 redis를 교체한 후에는 다른 구성 요소도 변경해야 합니다.
그래서 제가 개인적으로 이해한 바는 동일한 크롤러를 여러 시스템에 배포하는 것이 상대적으로 간단하다는 것입니다. 분산 배포 redis, 참조 주소
내 블로그입니다. 그리고 URL 중복 제거를 포함한 이러한 작업은 이미 작성된 scrapy-redis 프레임워크의 기능입니다.
참조 주소는 여기에서 예시를 다운로드하여 구체적인 구현을 확인할 수 있습니다. 저는 최근 scrapy-redis에도 이 작업을 진행하고 있으며, 배포한 후 이 답변을 업데이트하겠습니다.
새로운 진행사항이 있으면 공유하고 소통할 수 있습니다.

黄舟2017-04-24 09:13:57
@伟兴 안녕하세요 11.10.15에 이 댓글을 봤는데 지금 결과가 나오나요?
당신의 블로그를 추천해주실 수 있나요? 감사합니다~
chenjian158978@gmail.com으로 연락주세요
