
在70W的数据中,执行 'name': /Mamacitas / 需要17.358767秒才完成
数据内容例:
{
"Attitude_low": NumberInt(0),
"Comments": "i",
"file": [
"mamacitas-7-scene3.avi",
"mamacitas-7-scene4.avi",
"mamacitas-7-scene5.avi",
"mamacitas-7-scene2.avi",
"mamacitas-7-scene1.avi",
"14968frontbig.jpg",
"[000397].gif",
"mamacitas-7-bonus-scene1.avi",
"14968backbig.jpg"
],
"Announce": "http://exodus.desync.com/announce",
"View": NumberInt(0),
"Hash": "9E3842903C56E8BBC0C7AF7A0A8636590491923C",
"name": "Mamacitas 7[SILVERDUST]",
"Encoding": "!",
"EntryTime": 1403169286.9712,
"Attitude_top": NumberInt(0),
"CreatedBy": "ruTorrent (PHP Class - Adrien Gibrat)",
"CreationDate": NumberInt(1365851919)
}
关于索引部分: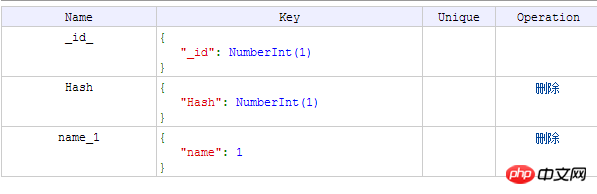
请问我该如何提高匹配速度?

怪我咯2017-04-24 09:11:39
해시 유형 인덱스는 퍼지 쿼리를 사용할 때 유용하지 않습니다. 단어 분할 후 인덱스를 구체적으로 작성하려면 검색 엔진에 의존해야 합니다.
하나는 탄력적 검색과 같은 것을 사용하고 전용 검색을 구축하는 것입니다
단어 분할 라이브러리를 사용하여 필드를 단어로 분할한 다음 mongodb를 사용하여 단어 분할 컬렉션을 생성할 수도 있습니다.


PHPz2017-04-24 09:11:39
MongoDb와 결합된 Lucence/Sphinx를 사용하여 검색 쿼리를 수행할 수 있습니다. 실제로 Mongodb 쿼리 효율성은 상대적으로 낮습니다
