
爬取了一个用户的论坛数据,但是这个数据库中有重复的数据,于是我想把重复的数据项给去掉。数据库的结构如下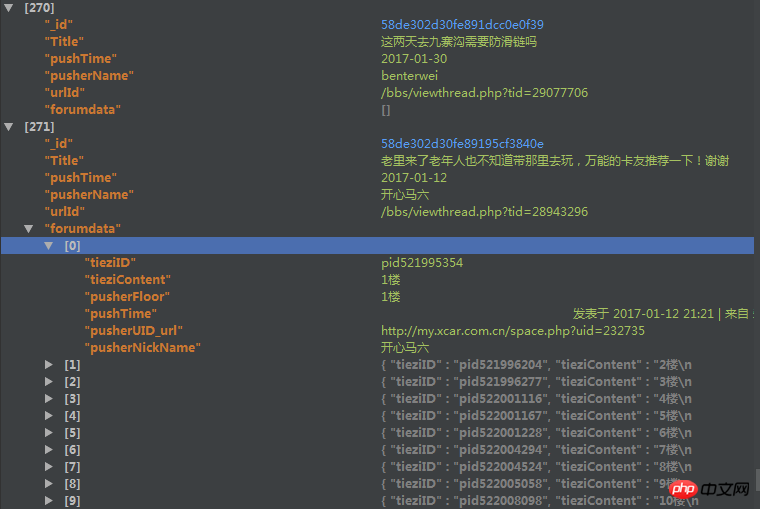
里边的forundata是这个帖子的每个楼层的发言情况。
但是因为帖子爬取的时候有可能重复爬取了,我现在想根据里边的urlId来去掉重复的帖子,但是在去除的时候我想保留帖子的forumdata(是list类型)字段中列表长度最长的那个。
用mongodb的distinct方法只能返回重复了的帖子urlId,都不返回重复帖子的其他信息,我没法定位。。。假如重复50000个,那么我还要根据这些返回的urlId去数据库中find之后再在mongodb外边代码修改吗?可是即使这样,我发现运行的时候速度特别慢。
之后我用了group函数,但是在reduce函数中,因为我要比较forumdata函数的大小,然后决定保留哪一个forumdata,所以我要传入forumdata,但是有些forumdata大小超过了16M,导致报错,然后这样有什么解决办法吗?
或者用第三种方法,用Map_reduce,但是我在map-reduce中的reduce传入的forumdata大小限制竟然是8M,还是报错。。。
代码如下
group的代码:
reducefunc=Code(
'function(doc,prev){'
'if (prev==null){'
'prev=doc'
'}'
'if(prev!=null){'
'if (doc.forumdata.lenth>prev.forumdata.lenth){'
'prev=doc'
'}'
'}'
'}'
)
map_reduce的代码:
reducefunc=Code(
'function(urlId,forumdata){'
'if(forumdata.lenth=1){'
'return forumdata[0];'
'}'
'else if(forumdata[0].lenth>forumdata[1].lenth){'
'return forumdata[0];'
'}'
'else{'
'return forumdata[1]}'
'}'
)
mapfunc=Code(
'function(){'
'emit(this.urlId,this.forumdata)'
'}'
)望各位高手帮我看看这个问题该怎么解决,三个方案中随便各一个就好,或者重新帮我分析一个思路,感激不尽。
鄙人新人,问题有描述不到位的地方请提出来,我会立即补充完善。

黄舟2017-04-18 10:34:12
이 문제가 아직 해결되지 않은 경우 다음 아이디어를 고려해 보세요.
1. MongoDB에서는 Aggregation을 권장하지만 map-reduce는 권장하지 않습니다.
2. 귀하의 요구 사항 중 매우 중요한 점은 가장 긴 배열 길이를 가진 문서를 찾기 위해 Forumdata의 길이, 즉 배열의 길이를 얻는 것입니다. 귀하의 원본 기사에서는 Forumdata가 목록(MongoDB의 배열이어야 함)이라고 나와 있습니다. MongoDB는 배열의 크기를 얻기 위해 $size 연산자를 제공합니다.
아래 밤을 참고해주세요:
으아악3. 위의 데이터를 얻은 후 $sort, $group 등을 집계하여 필요에 맞는 문서의 objectId를 찾을 수 있습니다.
https://segmentfault.com/q/10...
4. 마지막으로 관련 ObjectId를 일괄 삭제합니다
유사함:
var dupls = [] 삭제할 objectId를 저장하세요.
db.collectionName.remove({_id:{$in:dupls}})
참고로.
MongoDB를 사랑해주세요! 재미있게 보내세요!
찔러주세요<-왼쪽으로 찔러주세요 4월이에요! MongoDB 중국어 커뮤니티 심천 사용자 컨퍼런스 등록이 시작되었습니다! 위대한 신들의 집합!

迷茫2017-04-18 10:34:12
데이터의 양이 그다지 크지 않은 경우에는 다시 크롤링하여 저장할 때마다 쿼리하는 것이 가장 많은 데이터 세트만 저장됩니다.
훌륭한 크롤러 전략>>뛰어난 데이터 정리 전략

PHPz2017-04-18 10:34:12
네티즌 여러분, 감사합니다. qq 그룹에서 누군가가 map에서 forumdata를 먼저 urlId로 처리한 다음, forumdata.length를 그대로 유지하면서 Reduce에서 처리합니다. 해당 urlId와 해당 urlId가 최종적으로 데이터베이스에 저장되고, 이 데이터베이스의 urlId를 통해 원본 데이터베이스에서 모든 데이터를 읽어옵니다. 시도해 보았는데 효율성은 기대했던 것과는 다르지만 이전에 Python을 사용했을 때보다 속도는 여전히 훨씬 빠릅니다.
지도를 첨부하고 코드를 줄입니다:
'''javaScript
mapfunc=Code(
reducefunc=코드(
으아아아 으아아아mapfunc=코드(
으아아아)
reducefunc=코드(
으아아아)
으아아아