
问题始于一个链接
https://i1.pixiv.net/img-zip-...
这个链接在浏览器打开,会直接下载一个不完整的zip文件

但是,使用下载器下载却是完整文件

而当我尝试使用python下载的时候
from urllib import request
import sys
request.urlretrieve('https://i1.pixiv.net/img-zip-ugoira/img/2017/04/05/00/24/41/62259492_ugoira600x600.zip', '123.zip')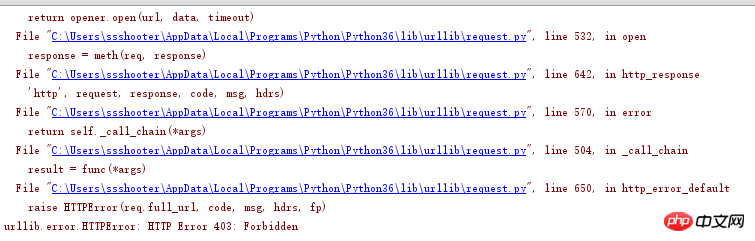
403报错
想问一下,为什么浏览器,下载器,以及python下载的结果会不一样?

