
最近想学习利用python的pandas处理apache的大日志,从国外找了一篇文章链接描述,对方用的是sep正则表达式提取数据
pd.read_csv(file_name, sep=r'\s(?=(?:[^"]*"[^"]*")*[^"]*$)(?![^\[]*\])', engine='python', na_values='-', header=None,usecols=[0, 3, 4, 5, 6, 7, 8], names=['ip', 'time', 'request', 'status', 'size', 'referer', 'user_agent'], converters={'time': parse_time, 'request': parse_str, 'status': int, 'size': int, 'referer': parse_str, 'user_agent': parse_str})apache的日志格式是
192.168.1.106 - - [23/Feb/2017:16:39:00 +0800] "GET / HTTP/1.1" 200 2054 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Safari/537.36"得到的结果是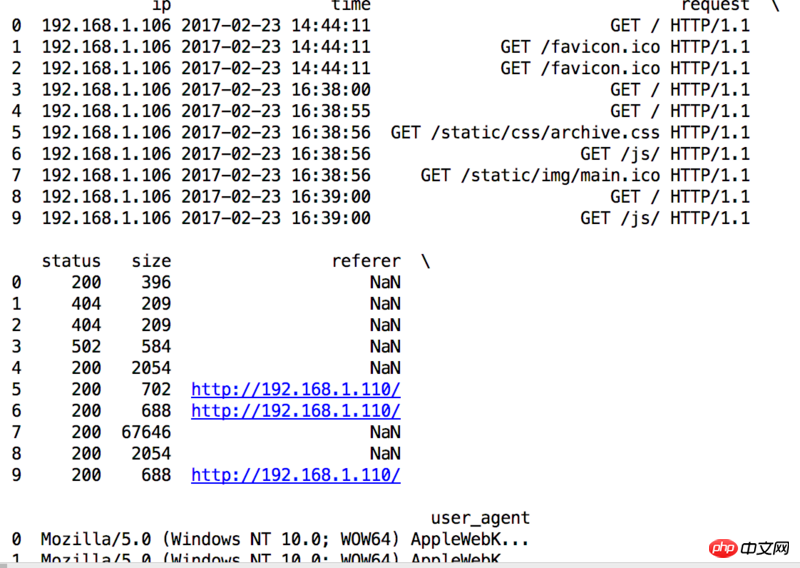
其他参数容易理解,就是sep的正则表达式不大理解,而且好像和python的正则还有点区别,麻烦大神讲解一下这个正则的含义

黄舟2017-04-18 10:26:20
sep 매개변수는 구분 기호를 지정하는 데 사용됩니다. 이 정규식은 공백으로 분할하지만 [] 또는 ""에 포함된 공백은 제외한다는 의미입니다.
