
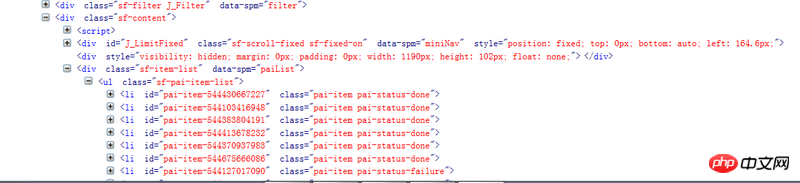
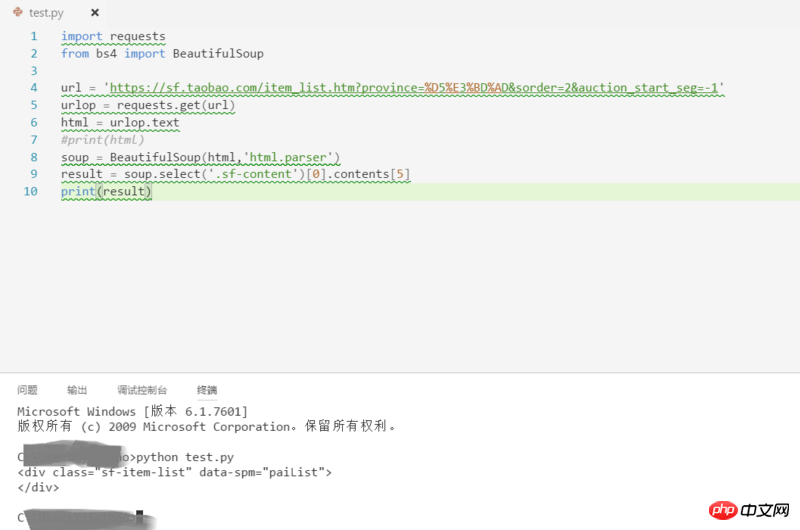
待解析页面的部分代码如第一幅图所示,我自己写的代码及运行结果如第二幅图所示。看到已经有答主提问解析页面丢失是因为用的是lxml的解析方式,我想说我一直用的是html.parser的方式。希望各位大神不吝赐教~


伊谢尔伦2017-04-18 10:20:51
질문자님, 크롬 F12를 사용하여 보시면 동적으로 컨텐츠가 로딩되는데, 페이지 URL을 직접 요청하여서는 이런 컨텐츠를 얻을 수 없습니다. 웹 페이지의 소스 코드를 마우스 오른쪽 버튼으로 클릭하여 F12의 내용과 비교하는 것이 좋습니다. 소스 코드에 내용이 없으면 네트워크에서 다른 요청을 확인하여 데이터가 있는지 확인하십시오. 필요.
