
http://apk.hiapk.com/appinfo/...
我想要爬取这个网页中的用户评论
但是却发现使用urllib2.urlopen(request)获取的html页面不完整
代码如图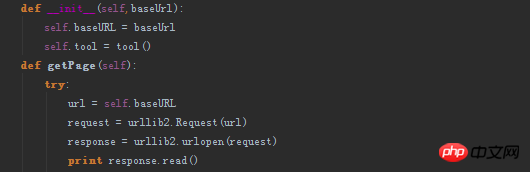

输出如图
但是实际上这个页面里面是有东西的
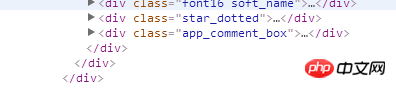
请问一下为什么获取到的html不全呢

PHP中文网2017-04-18 09:58:27
검색이 불완전한 것은 아닙니다. 이 페이지의 댓글은 javascript post-loading을 통해 생성됩니다. 요청한 html이 urllib2.urlopen에 반환되고 해당 페이지의 javascript가 실행되지 않습니다.
http://apk.hiapk.com/web/api.... 를 직접 요청할 수 있습니다. 이 주소는 모든 댓글을 반환할 수 있으며, 여전히 json이므로 처리가 매우 쉽습니다.
