
比如这个酒店:http://hotels.ctrip.com/hotel/dianping/1943326.html
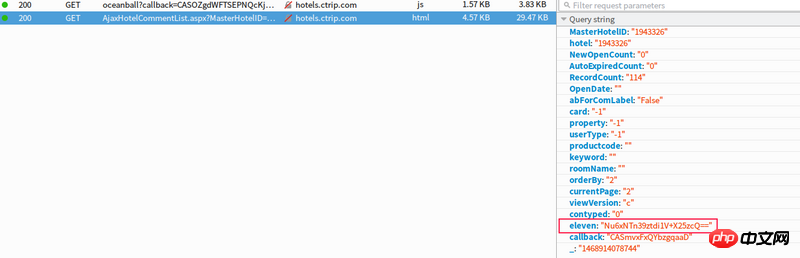
酒店的点评数据是通过ajax方式异步加载的,不想用模拟浏览器的方式来爬,太慢了,想直接请求点评数据的地址,但是这个eleven参数不知道是怎么生成的,在网页源码中没找到,分析js代码也没看出个所以然来,请大神来分析下,多谢了

迷茫2017-04-18 09:26:53
이것은 실제로 약간 왜곡되었지만 휴대폰 액세스를 시뮬레이션할 수 있습니다(사용자 에이전트 변경). 정적 HTML인 댓글 데이터를 얻을 수 있습니다.
http://m.ctrip.com/html5/hotel /HotelDetail/dianping /1943326.html
요청을 주의 깊게 살펴보세요. 매개변수를 계산하는 압축된 js가 있습니다. 

伊谢尔伦2017-04-18 09:26:53
base64로 인코딩되거나 암호화된 것 같습니다. 다른 매개변수와 관련해서는 캡쳐 방지를 위한 시그니처 매개변수인 것으로 의심된다.

