집 > Q&A > 본문
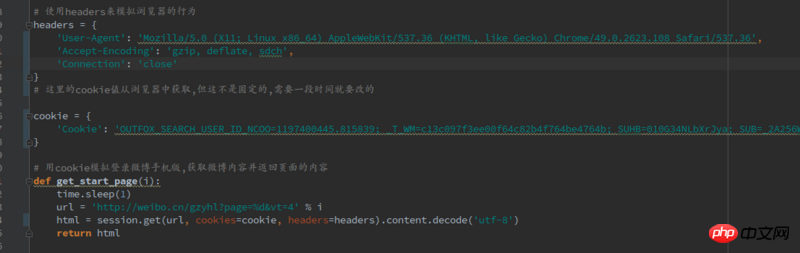
使用cookie模拟登录微博后想抓取多页微博内容,只是抓取到第二页就出现错误,以前都没出现过,使用的是Request库来模拟登录和获取内容。代码如下:
循环抓取在这里:
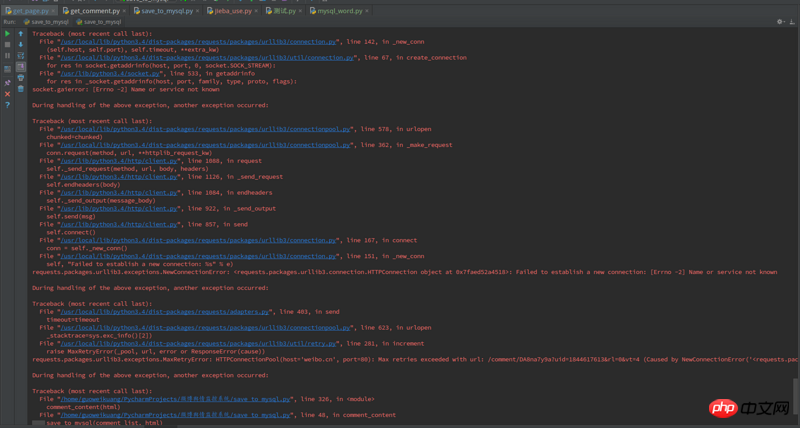
出现错误的代码如下:
我google过,有人说是因为requests发送http request占用太多connection资源,具体说明在Python使用requests時遇到Failed to establish a new connection
阿神2017-04-17 17:56:35
코드를 찍으세요. 여기에는 10페이지만 캡처되어 있습니다. 쿠키를 직접 추가하세요