
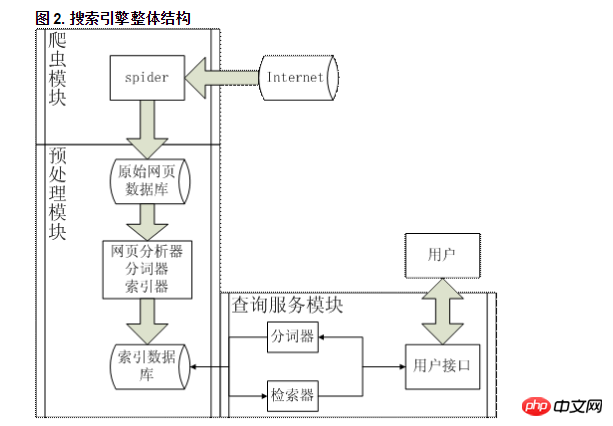
爬虫从 Internet 中爬取众多的网页作为原始网页库存储于本地,然后网页分析器抽取网页中的主题内容交给分词器进行分词,得到的结果用索引器建立正排和倒排索引,这样就得到了索引数据库,用户查询时,在通过分词器切割输入的查询词组并通过检索器在索引数据库中进行查询,得到的结果返回给用户。
请问这里原始网页库是该怎么实现,是直接存到数据库里吗?还是什么形式?
如果是存到数据库里,应该有哪些字段?




PHP中文网2017-04-17 17:49:58
Shenjianshou Cloud Crawler(http://www.shenjianshou.cn)를 사용하는 것이 좋습니다. 크롤러는 클라우드에서 완전히 작성되고 실행되며, 개발 환경을 구성할 필요가 없으며 빠른 개발이 가능합니다. 구현이 가능합니다.
단 몇 줄의 자바스크립트만으로 복잡한 크롤러를 구현하고 크롤러 방지, js 렌더링, 데이터 게시, 차트 분석, 리치 방지 등 다양한 기능을 제공할 수 있습니다. 이러한 문제는 자주 발생하는 문제입니다. 크롤러를 개발하는 과정에서 Archer가 이 모든 것을 해결하는 데 도움이 될 것입니다.
수집된 데이터:
(1) wecenterwordpressdiscuzdeempire 및 기타 cms 시스템과 같은 웹사이트에 게시하도록 선택할 수 있습니다
(2) 데이터베이스에 게시할 수도 있습니다
(3) 또는 파일을 로컬로 내보내기
구체적인 설정은 "데이터 게시 및 내보내기"에 있습니다