问题:
爬取信息页面为:知乎话题广场
当点击加载的时候,用Chrome 开发者工具,可以看到Network中,实际请求的链接为: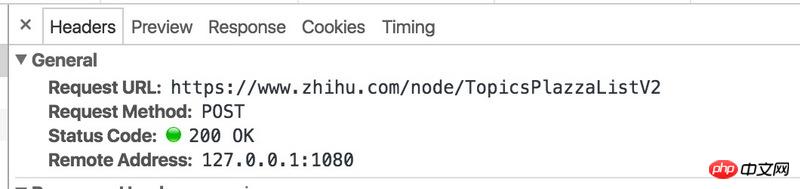
FormData为:
urlencode:
然后我的代码为:
...
data = response.css('.zh-general-list::attr(data-init)').extract()
param = json.loads(data[0])
topic_id = param['params']['topic_id']
# hash_id = param['params']['hash_id']
hash_id = ""
for i in range(32):
params = json.dumps({"topic_id": topic_id,"hash_id": hash_id, "offset":i*20})
payload = {"method": "next", "params": params, "_xsrf":_xsrf}
print payload
yield scrapy.Request(
url="https://m.zhihu.com/node/TopicsPlazzaListV2?" + urlencode(payload),
headers=headers,
meta={
"proxy": proxy,
"cookiejar": response.meta["cookiejar"],
},
callback=self.get_topic_url,
)执行爬虫之后,返回的是:
{'_xsrf': u'161c70f5f7e324b92c2d1a6fd2e80198', 'params': '{"hash_id": "", "offset": 140, "topic_id": 253}', 'method': 'next'}
^C^C^C{'_xsrf': u'161c70f5f7e324b92c2d1a6fd2e80198', 'params': '{"hash_id": "", "offset": 160, "topic_id": 253}', 'method': 'next'}
2016-05-09 11:09:36 [scrapy] DEBUG: Retrying <GET https://m.zhihu.com/node/TopicsPlazzaListV2?_xsrf=161c70f5f7e324b92c2d1a6fd2e80198¶ms=%7B%22hash_id%22%3A+%22%22%2C+%22offset%22%3A+80%2C+%22topic_id%22%3A+253%7D&method=next> (failed 1 times): [<twisted.python.failure.Failure OpenSSL.SSL.Error: [('SSL routines', 'SSL3_READ_BYTES', 'ssl handshake failure')]>]
2016-05-09 11:09:36 [scrapy] DEBUG: Retrying <GET https://m.zhihu.com/node/TopicsPlazzaListV2?_xsrf=161c70f5f7e324b92c2d1a6fd2e80198¶ms=%7B%22hash_id%22%3A+%22%22%2C+%22offset%22%3A+40%2C+%22topic_id%22%3A+253%7D&method=next> (failed 1 times): [<twisted.python.failure.Failure OpenSSL.SSL.Error: [('SSL routines', 'SSL3_READ_BYTES', 'ssl handshake failure')]>]是不是url哪里错了?请指点一二。

伊谢尔伦2017-04-17 17:46:32
디버그: <GET 재시도 그렇게 큰 프롬프트에서는 알기 어렵습니다. . . 패킷을 캡처할 때의 요청은 게시됩니다. scrapy를 사용할 때 get을 사용하는 이유는 무엇입니까? . .
伊谢尔伦2017-04-17 17:46:32
크롤러 작성은 한 단계가 아닌 단계적으로 이루어져야 합니다. 그렇지 않으면 무엇이 잘못되었는지 알 수 없습니다. 일반적으로 원하는 데이터를 먼저 얻은 다음 구문 분석하고 필터링해야 합니다.
원하는 데이터를 얻을 수 있는지 먼저 요청을 보내세요. 그렇지 않으면 URL이 잘못되었거나 차단되었을 수 있습니다