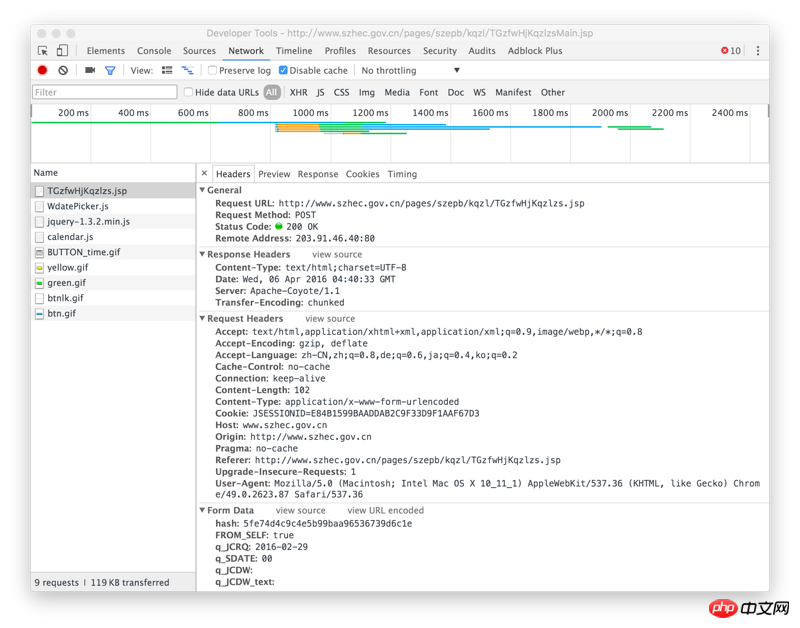
需要用到这方面的数据,单独一页一页的复制了一段时间的数据,发现很是耗时,想从深圳市环保局下载空气质量历史数据。选择日期后,页面出现一个相应的数据表格,每天有24个时间点的。需要将每一天每一个小时的数据都爬下来。页面如下:
网址:http://www.szhec.gov.cn/pages/szepb/kqzl...
麻烦大家

黄舟2017-04-17 17:35:12
requests.post를 사용하여 요청
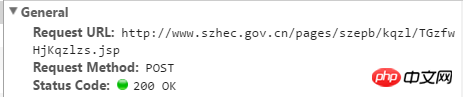
위 이미지 URL
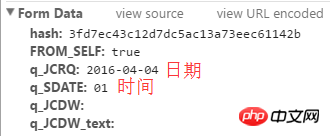
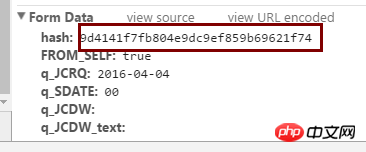

해시값은 위 사진의 위치에 있습니다.
이 사진은 반응입니다
#coding=utf-8
가져오기 요청
bs4 import BeautifulSoup
get_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp?FLAG=FIRSTFW"#해시 값 가져오기
post_url="http://www.szhec. gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp" #공기질 시간 확인
html=requests.get(get_url)
#Beautiful를 사용하여 웹페이지를 구문 분석하고 해시 값 가져오기
html_soup=BeautifulSoup (html .text,"html.parser")
hash=html_soup.select("input[name=hash]")
hash=hash[0].get('value')
#구성 데이터
데이터={
}
#이 시점에서 품질 관리 시간 정보가 올바르게 얻어졌습니다.
tqHtml=requests.post(post_url,data=data)
print tqHtml.text


PHPz2017-04-17 17:35:12
계속:
아마도 이 코드를 시도해 보았지만 프로그램에서 오류를 보고하지도 않았고 어떤 결과도 생성하지 않았습니다. 무슨 일이야?
가져오기 요청
import xlwt
from bs4 import BeautifulSoup
import datetime
import tqdm
def 날짜 목록(시작, 끝):
으아아아def get_html():
으아아아def get_excel():
으아아아get_excel()