
 < /p>
< /p>
sql语句是:
SELECT bp.amount / (yd_order_product에서 count(*) 선택, 여기서 order = bp.order 및 product = bp.product)를 설명합니다. ) 금액, s.costprice, 가격, s.store,b.type yd_batch_product에서 bp 왼쪽으로 yd_order_product를 op.order =에서 op로 조인 bp.order 및 op.product = bp.product 왼쪽은 bp.batch = b.id에서 yd_batch를 b로 결합하고 왼쪽은 bp.order = o .id에서 yd_order를 o로 결합하고 왼쪽은 bp.product = s.id에서 yd_stock을 s로 결합합니다. 여기서 o.deleted = '0' 및 s.forbidden = '0' 및 '2015-10-13 사이의 b.createdDate 00:00:00' 및 '2017-04-30 23:59:59' 및 s.store in (1,2,3,4,5,6) 및 s.chainID = 1
모든 유형의 모든 유형의 모든
巴扎黑2017-05-16 13:15:12
@TroyLiu 님의 의견은 인덱스가 너무 많이 생성되어 주문/제품/배치/금액 통합 인덱스를 구축한다는 아이디어가 잘못된 것 같다는 것입니다.
SQL 최적화의 핵심 아이디어는 빅데이터 테이블이 기존 where 문의 조건에 따라 데이터를 필터링할 수 있다는 것입니다. 이 예에서는
yd_batch_product 테이블이 가장 커야 하지만 where 문에는 필터링 조건이 없어 실행 효율성이 떨어집니다.
"Using temporary; Using filesort"가 나타나는 이유는 group by의 필드가 첫 번째 테이블 yd_batch_product 테이블의 필드 범위에 완전히 포함되지 않기 때문입니다.
제안 사항:
1.yd_batch/yd_order/yd_stock은 LEFT JOIN을 사용하지만 where 문에 이러한 테이블 필드에 대한 필터 조건이 있으므로 INNER JOIN과 동일하므로 연결 방법을 INNER JOIN으로 변경할 수 있으므로 mysql 실행 계획을 판단할 때 yd_batch_product 테이블만 먼저 쿼리할 수는 없습니다.
2. yd_batch 테이블의 CreateDate 필드에 인덱스를 생성하여 실행 계획의 첫 번째 드라이버 테이블에 변경 사항이 있는지 확인합니다. .
3. 강력한 필터링을 위해 store와 chainID를 결합하는 방법인 yd_stock 테이블은 결합된 인덱스를 생성하고 이전 단계와 동일한 방법으로 실행 계획이 변경되었는지 확인할 수 있습니다.
물론, 가장 이상적인 상황은 비즈니스와 데이터에서 출발하여, 대량의 데이터를 필터링할 수 있는 yd_batch_product 테이블에서 조건을 알아낸 후, 이 조건을 기반으로 인덱스를 생성하는 것입니다. 예를 들어, yd_batch 테이블의 CreateDate 필드에는 yd_batch_product 테이블에도 유사한 중복 필드가 있으며 이 필드는 인덱스를 생성하는 데 사용됩니다.
질문 업데이트 후 제안 사항:
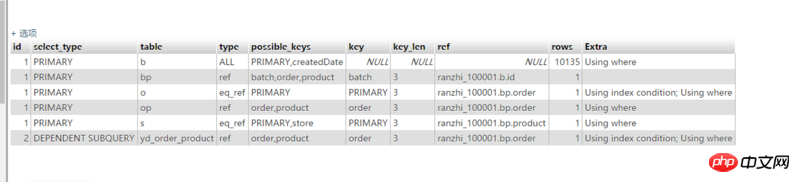
1. TYPE=ALL은 전체 테이블 스캔이 사용됨을 나타냅니다. 비록 CreateDate가 이미 인덱스를 생성했지만 데이터베이스 평가에서는 전체 테이블 스캔을 사용하는 것이 더 저렴하고 일반적으로 정상으로 간주됩니다. 1년 이상의 데이터, 총 10,000개 이상의 항목을 포함하여 더 큰 생성 날짜). 인덱스를 사용하려면 며칠 내에 범위를 좁히고 실행 계획에 변경 사항이 있는지 확인하면 됩니다. 물론 프롬프트를 사용하여 인덱스 사용을 강제할 수도 있지만 효율성이 반드시 높은 것은 아닙니다.
2. yd_order_product 테이블은 두 번 쿼리되며, 특히 실행 계획의 선택 하위 쿼리는 최대한 피해야 합니다.

阿神2017-05-16 13:15:12
먼저 yd_batch_product 테이블의 데이터 양이 너무 많고, 인덱스가 제대로 생성되지 않아 전체 쿼리에서 인덱스를 활용하지 못하는 현상이 발생합니다.
테이블 bp의 해당 키 열을 보면 bp가 NULL임을 알 수 있습니다.
최적화 참조:
yd_batch_product 테이블의 order/product/batch/amount 열에 공동 인덱스를 생성합니다. 공동 인덱스 순서에 주의하세요. (커버링 인덱스를 사용하려면 인덱스에 금액도 추가됩니다.)
yd_batch_product에 대한 다른 쿼리가 없으면 테이블의 모든 단일 열 인덱스를 삭제하는 것이 좋습니다.
yd_stock 테이블은 allowed/store/chainID 열에 공동으로 색인이 생성됩니다(인덱스 순서 참고).
yd_order 테이블은 삭제된 열에 단일 열 인덱스를 생성합니다.
yd_batch 테이블은 CreateDate 열에 단일 열 인덱스를 생성합니다.
현재 분석을 바탕으로 위의 최적화를 수행할 수 있습니다.
테스트용 데이터시트가 없기 때문에 오류가 있으면 수정해주세요.